文章目录
- 一、GPU 与 CPU 简介
- 1、GPU 与 CPU 的区别
- 2、GPU 分类
- 3、GPU(NVIDIA A100 ) 介绍
- 二、CUDA 简介
- 1、多版本 CUDA 切换
- 2、为各种 NVIDIA 架构匹配 CUDA arch 和 gencode
- 三、OpenCL 简介
- 1、OpenCL 平台模型
- 2、OpenCL 执行模型
- 四、参考资料
一、GPU 与 CPU 简介
1、GPU 与 CPU 的区别
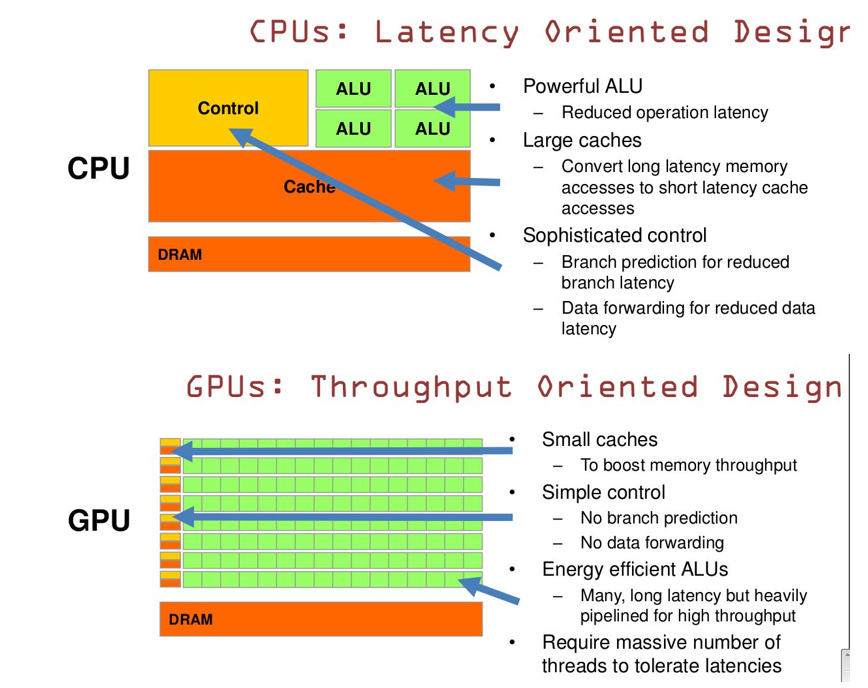
- GPU 的线程数(
Threads)、寄存器数(Registers)、单指令多数据流(SIMD Unit)比 CPU 多,而 CPU 的缓存(Cache)及算术逻辑单元(ALU)要比 GPU 大很多- GPU 的功耗(显存大)相对 CPU 要大很多
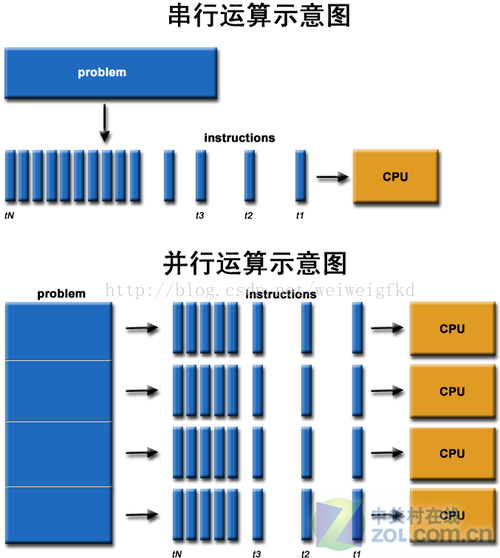
- CPU 擅长复杂逻辑控制及
串行的运算,GPU 擅长的是计算密集型及并行的运算- GPU 加速:服务器端主要是 NVIDIA 的 GPU,使用
CUDA/cuDNN/TensorRT加速;在 Android 手机的 GPU 领域主要是高通 Adreno系列和ARM Mali系列两大类,使用OpenCL,OpenGL或者Vulkan等方式进行加速- CPU 加速:Intel 发布了
OpenVINO对 CPU 进行加速,ARM 使用NEON对 CPU 进行加速
2、GPU 分类
| 分类 | 概述 | 特点 | 代表厂商 |
|---|---|---|---|
| 独立 GPU | 封装在独立的电路板,专用的显存 | 性能高,功耗大 | NVIDIA/Cambricon |
| 集成 GPU | 内嵌到主板上,共享系统内存 | 性能中等,功耗中等 | Intel |
| 移动端 GPU | 嵌在 SoC 中,共享系统内存 | 性能低,功耗低 | ARM Mali/Qualcomm Adreno |
3、GPU(NVIDIA A100 ) 介绍
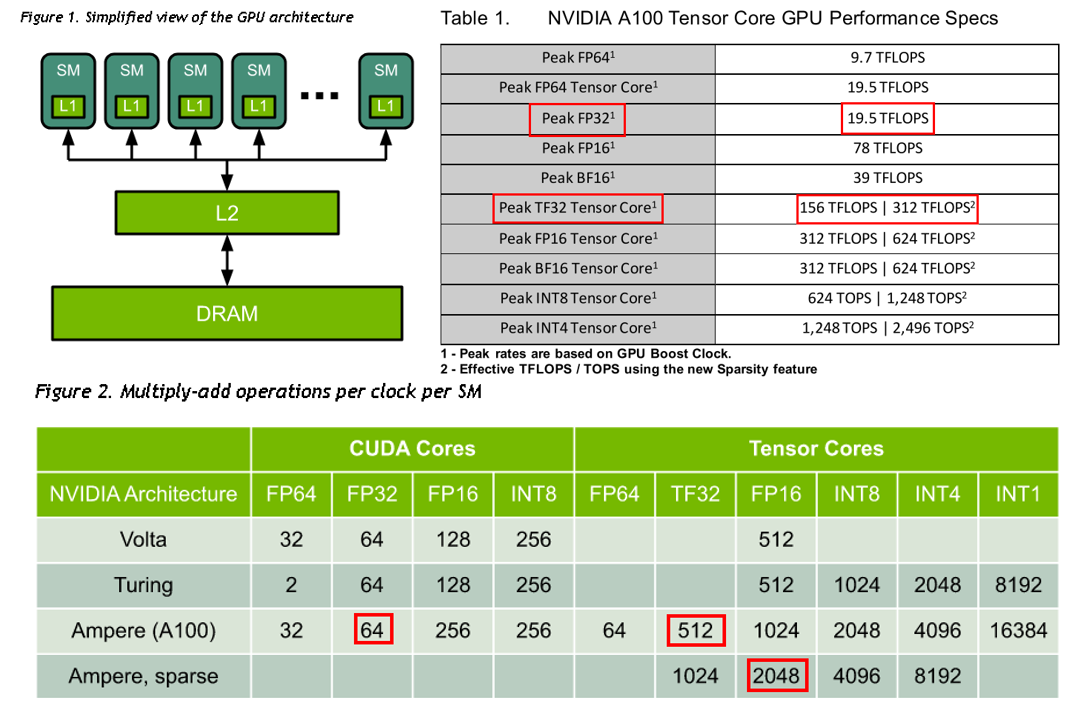
- 一个 GPU 包含多个
Streaming Multiprocessor(SM,支持并发执行多达几百上千的 thread ),而每个SM又包含多个CUDA Cores(全能通吃型的浮点运算单元,每一个GPU时钟执行一次值普通乘法) 和Tensor Cores(专门为深度学习矩阵运算设计,每个GPU时钟执行一次矩阵乘法)- NVIDIA A100 GPU 的整体架构及算力如下图所示,GPU 频率为
1.41GHZ,处理器( Streaming Multiprocessors, SMs)数为108,每个处理器 FP32 的 CUDA Cores 数量为64(总CUDA 核心数:108*64=6912),那么PeakFLOPS = 1.41*108*64*2 = 19.49TFLOPS

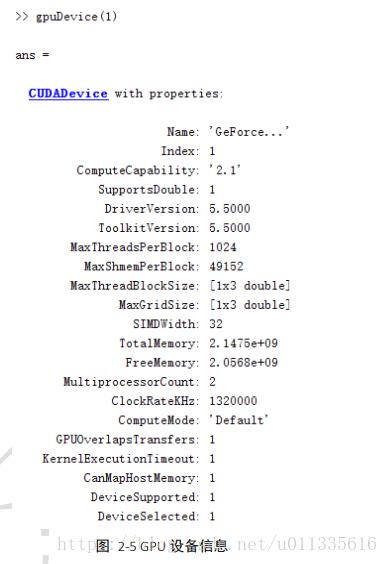
- 查看 GPU 的各种信息:
// 编译
nvcc gpu_info.cpp// 执行
./a.ou// 输出 GPU 信息如下
GPU Name = GeForce GTX 1080 Ti
Compute Capability = 6.1
GPU SMs = 28
GPU SM clock rate = 1.683 GHz
GPU Mem clock rate = 5.505 GHz// gpu_info.cpp 源代码如下
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#include <cuda_runtime.h>#define CHECK_CUDA(x, str) \if((x) != cudaSuccess) \{ \fprintf(stderr, str); \exit(EXIT_FAILURE); \}int main(void) {int gpu_index = 0;cudaDeviceProp prop;CHECK_CUDA(cudaGetDeviceProperties(&prop, gpu_index), "cudaGetDeviceProperties error");printf("GPU Name = %s\n", prop.name);printf("Compute Capability = %d.%d\n", prop.major, prop.minor); // 获得 SM 版本printf("GPU SMs = %d\n", prop.multiProcessorCount); // 获得 SM 数目printf("GPU SM clock rate = %.3f GHz\n", prop.clockRate / 1e6); // prop.clockRate 单位为 kHz,除以 1e6 之后单位为 GHzprintf("GPU Mem clock rate = %.3f GHz\n", prop.memoryClockRate / 1e6); // 同上/*if((prop.major == 8) && (prop.minor == 0)) // SM 8.0,即 A100{// 根据公式计算峰值吞吐,其中 64、32、256、256 是从表中查到printf("-----------CUDA Core Performance------------\n");printf("FP32 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 64 * 2); printf("FP64 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 32 * 2); printf("FP16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 256 * 2); printf("BF16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 128 * 2);printf("INT8 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 256 * 2); printf("-----------Tensor Core Dense Performance------------\n");printf("TF32 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 512 * 2); printf("FP64 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 64 * 2); printf("FP16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 1024 * 2); printf("BF16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 1024 * 2); printf("INT8 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 2048 * 2); printf("INT4 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 4096 * 2);printf("INT1 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 16384 * 2);printf("-----------Tensor Core Sparse Performance------------\n");printf("TF32 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 1024 * 2);printf("FP16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 2048 * 2);printf("BF16 Peak Performance = %.3f GFLOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 2048 * 2);printf("INT8 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 4096 * 2);printf("INT4 Peak Performance = %.3f GOPS.\n", prop.multiProcessorCount * (prop.clockRate/1e6) * 8192 * 2);}*/return 0;
}
二、CUDA 简介
CUDA(Compute Unified Device Architecture):是一种由 NVIDIA 推出的通用并行计算架构,该架构使 GPU 能够解决复杂的计算问题;,它包括编译器(nvcc)、开发工具、运行时库和驱动等模块,是当今最流行的GPU编程环境cuDNN:是基于 CUDA 的深度学习 GPU 加速库,支持常见的深度学习计算类型(卷积、下采样、非线性、Softmax 等)- 一个基本的
CUDA程序架构包含 5 个主要方面:
- 分配 GPU 内存
- 复制 CPU内存数据到 GPU 内存
- 激活 CUDA 内核去执行特定程序的计算
- 将数据从 GPU 拷贝 到 CPU 中
- 删除 GPU 中的数据
1、多版本 CUDA 切换
# 1、查看当前 cuda 版本
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176# 2、删除之前创建的软链接
sudo rm -rf /usr/local/cuda# 3、建立新的软链接,cuda9.0 切换到 cuda11.0
sudo ln -s /usr/local/cuda-11.0/ /usr/local/cuda/# 4、查看当前 cuda 版本
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Wed_Jul_22_19:09:09_PDT_2020
Cuda compilation tools, release 11.0, V11.0.221
Build cuda_11.0_bu.TC445_37.28845127_0# 5、将 ~/.bashrc 或 caffe Makefile.config 等下与 cuda 相关的路径都改为 /usr/local/cuda/(指定版本的软链接)
vim ~/.bashrc # 不使用 /usr/local/cuda-9.0/ 或 /usr/local/cuda-11.0/ 等,这样每次切换版本,就不用改配置了export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/lib/x86_64-linux-gnu
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64source ~/.bashrc # 立即生效
2、为各种 NVIDIA 架构匹配 CUDA arch 和 gencode
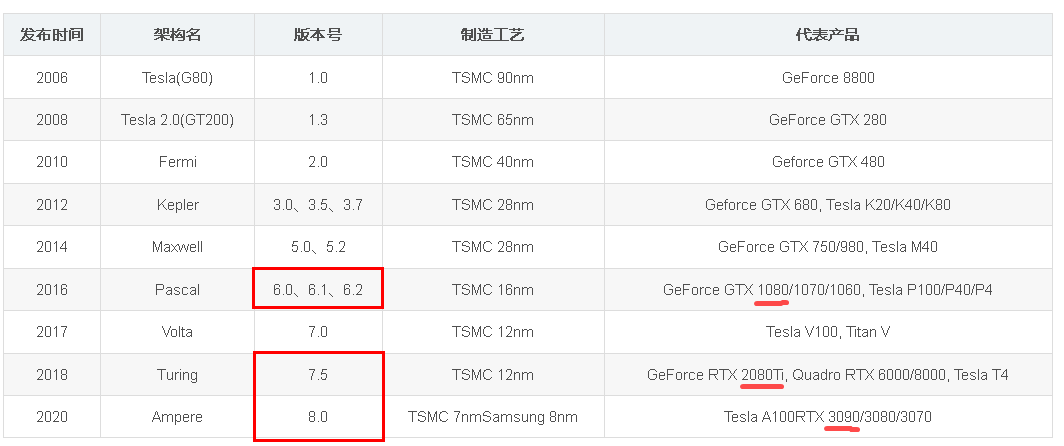
- Nvidia 通用计算 GPU 架构历程如下表所示:
Volta(推出第一代tensor core) ->Turning(第二代tensor core) ->Ampere(第三代tensor core)- CUDA C++ 编译器
nvcc基于每个内核,既可以用来产生特定于体系结构的 cubin 文件(sm_XX),又能产生前向兼容的 PTX 版本(compute_XX),使用较新的架构的 GPU
设备能够向下兼容在旧架构设备上编译得到的可执行程序- CUDA 代码编译的时候,需要根据 GPU 所使用的架构提供
arch和gencode,不同设备的编译选项说明可参考下面代码示例
# 一、各种架构下 GPU arch 和 gencode 的设置说明
- gencode:生成码,允许生成更多的 PTX文 件,并且对不同的架构可以重复许多次
- arch:架构标志位,前端编译目标,指明了 CUDA 文件编译产生的结果所依赖的 NVIDIA GPU 架构的名称,必须始终为 PTX 版本
- compute_XX:指的是 PTX 版本
- sm_XX:指的是 cubin 版本
- code:指定后端编译目标,可以是 cubin 或 PTX 或两者均可# 1、Maxwell cards(CUDA 6 until CUDA 11):GTX Titan X, GTX-970, GTX-980
ARCH= -gencode arch=compute_52,code=[sm_52,compute_52]# 2、Pascal (CUDA 8 and later):GTX 1080, Titan Xp, Tesla P40, Tesla P4
ARCH= -gencode arch=compute_61,code=[sm_61,compute_61]
ARCH= -gencode arch=compute_60,code=[sm_60,compute_60] # Quadro GP100, Tesla P100, DGX-1 (Generic Pascal)# 3、Volta (CUDA 9 and later):Tesla V100, GTX 1180 (GV104), Titan V
ARCH= -gencode arch=compute_70,code=[sm_70,compute_70]# 4、Turing (CUDA 10 and later):GeForce RTX 2080 Ti, RTX 2080, Quadro RTX 8000, Tesla T4
ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]# 5、Ampere (CUDA 11.1 and later)
ARCH= -gencode arch=compute_80,code=[sm_80,compute_80] # NVIDIA A100, NVIDIA DGX-A100
ARCH= -gencode arch=compute_86,code=[sm_86,compute_86] # Tesla GA10x cards, RTX 3090/3080, NVIDIA A40, Quadro A10, Quadro A16, Quadro A40# 6、CAFFE CUDA architecture setting: going with all of them.
ARCH= -gencode arch=compute_50,code=[sm_50,compute_50] \-gencode arch=compute_52,code=[sm_52,compute_52] \-gencode arch=compute_61,code=[sm_61,compute_61] \-gencode arch=compute_70,code=[sm_70,compute_70]---------------------------------------------------
# 二、Sample nvcc gencode and arch Flags in GCC
# 1.Sample flags for generation on CUDA 9.2 for maximum compatibility with Volta cards:
-arch=sm_50 \
-gencode=arch=compute_50,code=sm_50 \
-gencode=arch=compute_52,code=sm_52 \
-gencode=arch=compute_60,code=sm_60 \
-gencode=arch=compute_61,code=sm_61 \
-gencode=arch=compute_70,code=sm_70 \
-gencode=arch=compute_70,code=compute_70# 2.Sample flags for generation on CUDA 10.1 for maximum compatibility with V100 and T4 Turing cards:
-arch=sm_50 \
-gencode=arch=compute_50,code=sm_50 \
-gencode=arch=compute_52,code=sm_52 \
-gencode=arch=compute_60,code=sm_60 \
-gencode=arch=compute_61,code=sm_61 \
-gencode=arch=compute_70,code=sm_70 \
-gencode=arch=compute_75,code=sm_75 \
-gencode=arch=compute_75,code=compute_75 # 3.Sample flags for generation on CUDA 11.0 for maximum compatibility with V100 and T4 Turing cards:
-arch=sm_52 \
-gencode=arch=compute_52,code=sm_52 \
-gencode=arch=compute_60,code=sm_60 \
-gencode=arch=compute_61,code=sm_61 \
-gencode=arch=compute_70,code=sm_70 \
-gencode=arch=compute_75,code=sm_75 \
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_80,code=compute_80# 4.Sample flags for generation on CUDA 11.0 for maximum compatibility with V100 and T4 Turing cards, but also support newer RTX 3080 and other Ampere cards:
-arch=sm_52 \
-gencode=arch=compute_52,code=sm_52 \
-gencode=arch=compute_60,code=sm_60 \
-gencode=arch=compute_61,code=sm_61 \
-gencode=arch=compute_70,code=sm_70 \
-gencode=arch=compute_75,code=sm_75 \
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_86,code=sm_86 \
-gencode=arch=compute_86,code=compute_86# 5.Sample flags for generation on CUDA 11.1 for best performance with RTX 3080 cards:
-arch=sm_80 \
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_86,code=sm_86 \
-gencode=arch=compute_86,code=compute_86 # 三、Using Cmake for TensorRT: drop the sm_ and compute_ prefixes, refer only to the compute capabilities instead
# 1.Example for Tesla V100 and Volta cards in general:
cmake <...> -DGPU_ARCHS="70"# 2.Example for NVIDIA RTX 2070 and Tesla T4:
cmake <...> -DGPU_ARCHS="75"# 3.Example for NVIDIA A100:
cmake <...> -DGPU_ARCHS="80"# 4.Example for NVIDIA RTX 3080 and A100 together:
cmake <...> -DGPU_ARCHS="80 86"
三、OpenCL 简介
异构多核处理器:一般指在CPU里集成了CPU与其他模块(GPU/DSP/FPGA)一起同步计算,因为是属于不同的设备但要一同工作,所以需要设计可以让他们协同工作。海思Hi3559A芯片架构如下:

1、OpenCL 平台模型
- Opencl的平台模型是由一个主机和若干个设备组成,也就是一个Host+多个Device的组织形式。这些设备可以是CPU、GPU、DSP、FPGA等。这种多种处理器混合的结构,就组成了异构并行计算平台。在这些Device中又包含了一个或者多个计算单元(Computing Units, CU),每个计算单元中可以包括若干个处理元件(Processing Elements, PE),内核程序(kernel)最终就在各个PE上并行运行。

2、OpenCL 执行模型
- 理解执行模型对于理解OpenCl的程序至关重要,所谓执行模型是指OpenCL程序的运行方式,OpenCL的程序包括Host程序和Kernel程序两部分。Host程序运行在主机上,Kernel程序的执行依赖于Host程序中定义的上下文。OpenCL的执行模型的核心理念就是通过主机管理运行在Kernel上的程序(一般OpenCL代码中包含多个kernel程序)。
- 由于OpenCL是数据并行的,同一时刻会在PE上同时执行同一条kernel函数,只是数据不同而已。相同时刻同时执行一条kernel,怎么区分哪个PE上跑的是什么数据?OpenCL会为每个PE执行的kernel分配index, 用于区分相同函数不同的数据,为OpenCL抽象的最小可执行单位被称为工作节点(Work Item),每个kernel执行时都会分配一个全局的工作节点 index。
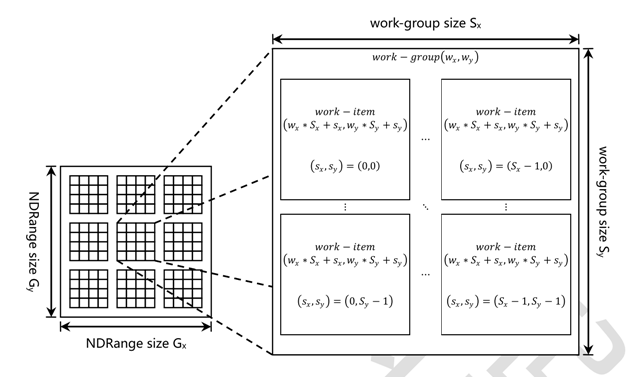
- 每个Kernel程序运行在一个工作节点上(Work Item),同时有一个索引与之对应,通过这个索引建立了Kernel程序和它所要处理的数据之间的关系。程序申请的所有处理节点构成的组合就称之为工作空间。换句话说,工作空间就是当前程序所需要的所有处理节点的集合,它可以是一维、二维和三维的,每一个work item都有一个全局的ID,称为global ID。对应的每一个运行在处理节点上的kernel程序都可以通过一个全局索引访问。
- 除了全局的工作空间外,opencl还提供了将工作空间进一步划分为工作组空间(work group)的结构,这就是工作组的由来。工作组的维度必须和工作空间的维度相同,并且共组的每个维度都可以整除工作空间的每个对应的维度。这样一来,每个工作组都有一个work group ID,每个工作组内,有多个work item,每个work item又对应有一个局部的ID,称为local ID。
- Opencl 将相同的kernel下的work-item,以相同数量的划分为work-group。也就是相同kernel下的work-group之间的work-item是相同的。opencl能够保证同一条 work-group下的work-item是并行的,但是不同的work-group下的不同work-item并不能保证并行,所以opencl只能够支持同一work-group的work-item的同步。其次work-item大小的划分是和硬件相关的,每个芯片不一样。work-item和work-group可以和硬件很好的映射起来,这是opencl抽象模型的优势之一, work-item可以映射为GPU的PE, 每个GPU有多个CU,在同一个CU下面有多个PE。在CU里面有多个调度器,可以保证在该CU下的PE能够并行运行,故可以将work-item映射为PE, work-group映射为CU。
- 注意:
1.每个GPU都有固定的处理单元,如何调度这些单元工作是程序优化的关键;
2.工作空间和工作组空间每个维度上的整除关系一定要注意。
四、参考资料
1、CUDA架构及对应编译参数
2、http://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/
3、https://en.wikipedia.org/wiki/CUDA#GPUs_supported
4、GPU 优化技术-OpenCL 介绍
5、GPU 优化技术-OpenCL 运行时 API 介绍