Numba:高性能计算的高生产率
在这篇文章中,笔者将向你介绍一个来自Anaconda的Python编译器Numba,它可以在CUDA-capable GPU或多核cpu上编译Python代码。Python通常不是一种编译语言,你可能想知道为什么要使用Python编译器。答案当然是:运行本地编译的代码要比运行动态的、解译的代码快很多倍。Numba允许你为Python函数指定类型签名,从而在运行时启用编译(这就是“Just-in-Time”,即时,也可以说JIT编译)。Numba动态编译代码的能力意味着你不会因此而抛弃Python的灵活性。这是向提供高生产率编程和高性能计算的完美结合迈出的一大步。
使用Numba可以编写标准的Python函数,并在CUDA-capable GPU上运行它们。Numba是为面向数组的计算任务而设计的,很像大家常用的NumPy库。在面向数组的计算任务中,数据并行性对于像GPU这样的加速器是很自然的。Numba了解NumPy数组类型,并使用它们生成高效的编译代码,用于在GPU或多核CPU上执行。所需的编程工作可以很简单,就像添加一个函数修饰器来指示Numba为GPU编译一样。例如,在下面的代码中,@ vectorize decorator会生成一个编译的、矢量化的标量函数在运行时添加的版本,这样它就可以用于在GPU上并行处理数据数组。
要在CPU上编译和运行相同的函数,我们只需将目标更改为“CPU”,它将在编译水平上带来性能,在CPU上向量化C代码。这种灵活性可以帮助你生成更可重用的代码,并允许你在没有GPU的机器上开发。
import numpy as npfrom numba import vectorize@vectorize(['float32(float32, float32)'], target='cuda')def Add(a, b):return a + b# Initialize arraysN = 100000
A = np.ones(N, dtype=np.float32)
B = np.ones(A.shape, dtype=A.dtype)
C = np.empty_like(A, dtype=A.dtype)
# Add arrays on GPU
C = Add(A, B)
关于Python 的GPU-Accelerated库
CUDA并行计算平台的优势之一是其可用的GPU加速库的阔度。Numba团队的另一个项目叫做pyculib,它提供了一个Python接口,用于CUDA cuBLAS(dense linear algebra,稠密线性代数),cuFFT(Fast Fourier Transform,快速傅里叶变换),和cuRAND(random number generation,随机数生成)库。许多应用程序都能够通过使用这些库获得显著的加速效果,而不需要编写任何特定于GPU的代码。例如,下面的代码使用“XORWOW”伪随机数生成器在GPU上生成100万个均匀分布的随机数。
import numpy as npfrom pyculib import rand as curandprng = curand.PRNG(rndtype=curand.PRNG.XORWOW)rand = np.empty(100000)prng.uniform(rand)print rand[:10]CUDA Python的高并行性
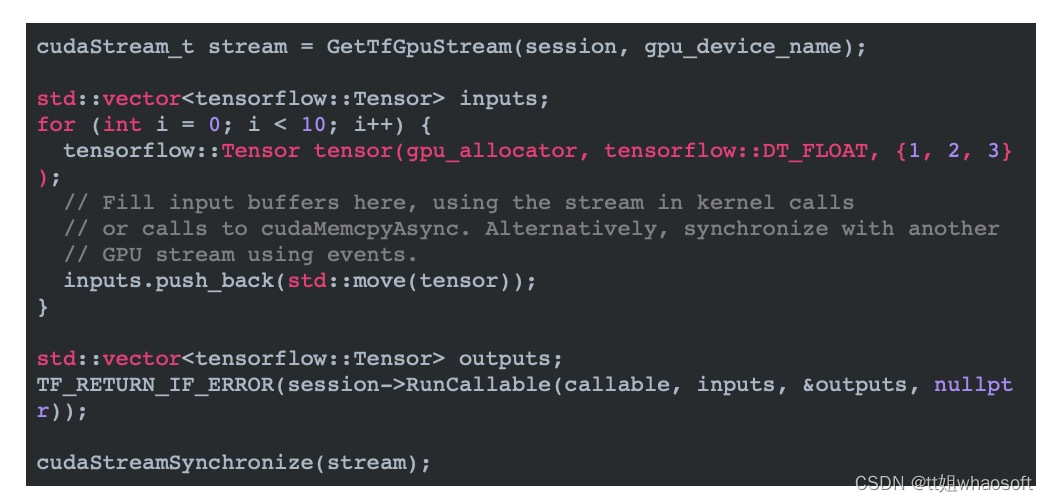
Anaconda(原名Continuum Analytics)认识到,在某些计算上实现大的速度需要一个更具表现力的编程接口,它比库和自动循环矢量化更详细地控制并行性。因此,Numba有另一组重要的特性,构成了其非正式名称“CUDA Python”。Numba公开了CUDA编程模型,正如CUDA C/ C++,但是使用纯python语法,这样程序员就可以创建自定义、调优的并行内核,而不会放弃python带来的便捷和优势。Numba的CUDA JIT(通过decorator或函数调用可用)在运行时编译CUDA Python函数,专门针对你所使用的类型,它的CUDA Python API提供了对数据传输和CUDA流的显式控制,以及其他特性。
下面的代码示例演示了一个简单的Mandelbrot设置内核。请注意,mandel_kernel函数使用Numba提供的cuda.threadIdx,cuda.blockIdx,cuda.blockDim和cuda.gridDim架构来计算当前线程的全局X和Y像素索引。与其他CUDA语言一样,我们通过插入在括号内一个“执行配置”(CUDA-speak用于线程数和线程块启动内核),在函数名和参数列表之间中: mandel_kernel[griddim, blockdim](-2.0, 1.0, -1.0, 1.0, d_image, 20)。你还可以看到使用to_host和to_device API函数来从GPU中复制数据。
Mandelbrot的例子将在Github上持续更新。
@cuda.jit(device=True)def mandel(x, y, max_iters):"""Given the real and imaginary parts of a complex number,determine if it is a candidate for membership in the Mandelbrotset given a fixed number of iterations."""c = complex(x, y)z = 0.0jfor i in range(max_iters):z = z*z + cif (z.real*z.real + z.imag*z.imag) >= 4:return ireturn max_iters@cuda.jitdef mandel_kernel(min_x, max_x, min_y, max_y, image, iters):height = image.shape[0]width = image.shape[1]pixel_size_x = (max_x - min_x) / widthpixel_size_y = (max_y - min_y) / heightstartX = cuda.blockDim.x * cuda.blockIdx.x + cuda.threadIdx.xstartY = cuda.blockDim.y * cuda.blockIdx.y + cuda.threadIdx.ygridX = cuda.gridDim.x * cuda.blockDim.x;gridY = cuda.gridDim.y * cuda.blockDim.y;for x in range(startX, width, gridX):real = min_x + x * pixel_size_xfor y in range(startY, height, gridY):imag = min_y + y * pixel_size_yimage[y, x] = mandel(real, imag, iters)gimage = np.zeros((1024, 1536), dtype = np.uint8)blockdim = (32, 8)griddim = (32,16)start = timer()d_image = cuda.to_device(gimage)mandel_kernel[griddim, blockdim](-2.0, 1.0, -1.0, 1.0, d_image, 20)d_image.to_host()dt = timer() - startprint "Mandelbrot created on GPU in %f s" % dtimshow(gimage)
在一台带有NVIDIA Tesla P100 GPU和Intel Xeon E5-2698 v3 CPU的服务器上,这个CUDA Python Mandelbrot代码运行的速度比纯Python版本快1700倍。1700倍似乎有些不切实际,但请记住,我们正在比较编译的、并行的、GPU加速的Python代码来解释CPU上的单线程Python代码。

今天开始使用Numba吧
Numba为Python开发人员提供了一种简单的进入GPU加速计算的方法,并提供了一种使用越来越复杂的CUDA代码的方法,其中至少有新语法和术语。你可以从简单的函数decorator开始实现自动编译函数,或者使用pyculib的强大的CUDA库。当你提高对并行编程概念的理解时,当你需要对于并行线程的有表现力且灵活的控制时,CUDA可以在不需要你第一天就完全了解的情况下使用。
Numba是一个BSD认证的开源项目,它本身严重依赖于LLVM编译器的功能。Numba的GPU后端使用了基于LLVM的NVIDIA编译器SDK。CUDA库周围的pyculib包装器也是开源且经过BSD认证的。
要开始使用Numba,第一步是下载并安装Anaconda Python发行版,这是一个“完全免费的、用于大规模数据处理、预测分析和科学计算的Python发行版”,其中包括许多流行的软件包(Numpy、Scipy、Matplotlib、iPython等)和“conda”,这是一个强大的包管理器。一旦您安装了Anaconda,通过键入conda安装numba cudatoolkit pyculib,安装所需的CUDA包。然后在ContinuumIO github存储库中查看CUDA的Numba教程。笔者建议你在Anaconda的博客上查看Numba的帖子。
Nvidia的CUDA 架构为我们提供了一种便捷的方式来直接操纵GPU 并进行编程,但是基于
C语言的CUDA实现较为复杂,开发周期较长。而python 作为一门广泛使用的语言,具有
简单易学、语法简单、开发迅速等优点。作为第四种CUDA支持语言,相信python一定会
在高性能计算上有杰出的贡献–pyCUDA。
pyCUDA特点
pyCUDA工作流程
调用的基本例子
包含内容
pyCUDA特点
CUDA完全的python实现
编码更为灵活、迅速、自适应调节代码
更好的鲁棒性,自动管理目标生命周期和错误检测
包含易用的工具包,包括基于GPU的线性代数库、reduction和scan,添加了快速傅里叶变换包和线性代数包LAPACK
完整的帮助文档Wiki
pyCUDA的工作流程
具体的调用流程如下:开始
编写python程序
python程序检查?
调用pyCUDA编译CUDA 源码并上传GPU
编译正确?
PyCUDA’s numpy进行数据读入处理
数据读入处理成功?
输出GPU 加速处理结果
结束
调用基本例子
import pycuda.autoinit
import pycuda.driver as drv
import numpyfrom pycuda.compiler import SourceModule
mod = SourceModule("""
__global__ void multiply_them(float *dest, float *a, float *b)
{const int i = threadIdx.x;dest[i] = a[i] * b[i];
}
""")multiply_them = mod.get_function("multiply_them")a = numpy.random.randn(400).astype(numpy.float32)
b = numpy.random.randn(400).astype(numpy.float32)dest = numpy.zeros_like(a)
multiply_them(drv.Out(dest), drv.In(a), drv.In(b),block=(400,1,1), grid=(1,1))print dest-a*b补充内容:对于GPU 加速python还有功能包,例如处理图像的pythonGPU加速包—— pyGPU
以及专门的GPU 加速python机器学习包—— scikitCUDA
GPU入门
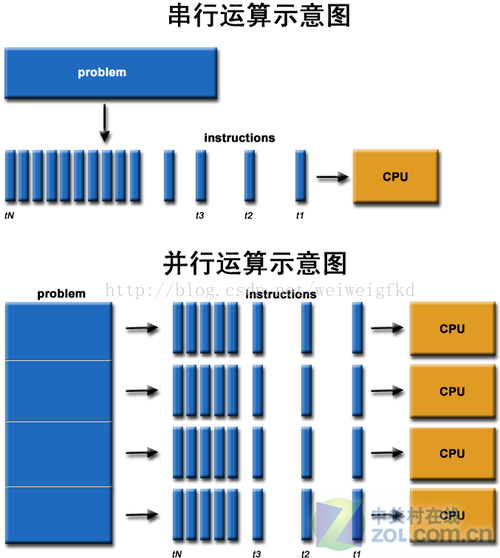
现在GPU编程正变得越来越流行,由于CPU串行执行的局限性,程序如果在GPU上运行,则可真正做到多线程,并发执行,极大减少运行时间,这对于分秒必争的科学计算,以及新兴的人工智能领域都带来了极大的便利。 目前,GPU编程以NVIDIA的CUDA平台为主,支持四种语言C、C++、Fortran(PGI)以及Python。目前CUDA的最新版本已经达到7.5,具体配置可以看官方指导和其它教程,这里不做具体介绍。 下面我们具体来看Python的GPU编程。 我的显卡是GeForce GT 740M,安装CUDA7.5,使用Python2.7搭配相关库。 首先我们要引入一些必要的包 from numbapro import cuda 是cuda包是必须导入的,否则不能使用GPU。 引入之后就可以调用cuda对象了。例如,创建一个一维网格
tx = cuda.threadIdx.x
bx = cuda.blockIdx.x
bw = cuda.blockDim.x
i = tx + bx * bw
array[i] = something(i)也可以简化成
i = cuda.grid(1)
array[i] = something(i)上面两段代码实现的功能是一样的。
接下来我们了解一下CUDA Stream的操作 CUDA流是对CUDA设备的命令队列,通过特殊的流,CUDA API可以变为异步,这也意味着请求肯在队列结束前返回。存储器传送指令和内核调用都可以使用CUDA流。 下面我们来看示例:
stream = cuda.stream()
devary = cuda.to_device(an_array, stream=stream)
a_cuda_kernel[griddim, blockdim, stream](devary)
cuda.copy_to_host(an_array, stream=stream)
# 在an_array中的数据可能尚未就绪
stream.synchronize()
# an_array中的数据已经就绪另一种语法是使用Python环境
stream = cuda.stream()
with stream.auto_synchronize():devary = cuda.to_device(an_array, stream=stream)a_cuda_kernel[griddim, blockdim, stream](devary)devary.copy_to_host(an_array, stream=stream)
# an_array中的数据已经就绪接下来是关于共享内存: 为了达到最大性能,CUDA内核需要使用共享内存用于缓存数据,CUDA编译器支持使用cuda.shared.array(shape, dtype)方法用来指定使用内核中的对象。 下面看一个例子
bpg = 50
tpb = 32
n = bpg * tpb@jit(argtypes=[float32[:,:], float32[:,:], float32[:,:]], target='gpu')
def cu_square_matrix_mul(A, B, C):sA = cuda.shared.array(shape=(tpb, tpb), dtype=float32)sB = cuda.shared.array(shape=(tpb, tpb), dtype=float32)tx = cuda.threadIdx.xty = cuda.threadIdx.ybx = cuda.blockIdx.xby = cuda.blockIdx.ybw = cuda.blockDim.xbh = cuda.blockDim.yx = tx + bx * bwy = ty + by * bhacc = 0.for i in range(bpg):if x < n and y < n:sA[ty, tx] = A[y, tx + i * tpb]sB[ty, tx] = B[ty + i * tpb, x]cuda.syncthreads()if x < n and y < n:for j in range(tpb):acc += sA[ty, j] * sB[j, tx]cuda.syncthreads()if x < n and y < n:C[y, x] = acc以上就是python GPU编程的入门介绍。
我们以FFT 为例,
看看究竟如何利用GPU进行加速。 先看示例代码,然后进行讲解。
import sys
import numpy as np
from scipy.signal import fftconvolve
from scipy import misc, ndimage
from matplotlib import pyplot as plt
from numbapro.cudalib import cufft
from numbapro import cuda, vectorize
from timeit import default_timer as timer@vectorize(['complex64(complex64, complex64)'], target='gpu')
#目标平台是64位机器且拥有GPU
def vmult(a, b):return a * bdef best_grid_size(size, tpb):bpg = np.ceil(np.array(size, dtype=np.float) / tpb).astype(np.int).tolist()return tuple(bpg)def main():# 构建过滤器laplacian_pts = '''-4 -1 0 -1 -4-1 2 3 2 -10 3 4 3 0-1 2 3 2 -1-4 -1 0 -1 -4'''.split()laplacian = np.array(laplacian_pts, dtype=np.float32).reshape(5, 5)# 构建图像try:filename = sys.argv[1]image = ndimage.imread(filename, flatten=True).astype(np.float32)except IndexError:image = misc.lena().astype(np.float32)print("Image size: %s" % (image.shape,))response = np.zeros_like(image)response[:5, :5] = laplacian# CPUts = timer()cvimage_cpu = fftconvolve(image, laplacian, mode='same')te = timer()print('CPU: %.2fs' % (te - ts))# GPUthreadperblock = 32, 8blockpergrid = best_grid_size(tuple(reversed(image.shape)), threadperblock)print('kernel config: %s x %s' % (blockpergrid, threadperblock))# cuFFT系统,触发器初始化.# 对于小数据集来说,效果更明显.# 不应该计算这里浪费的时间cufft.FFTPlan(shape=image.shape, itype=np.complex64, otype=np.complex64)# 开始GPU运行计时ts = timer()image_complex = image.astype(np.complex64)response_complex = response.astype(np.complex64)d_image_complex = cuda.to_device(image_complex)d_response_complex = cuda.to_device(response_complex)cufft.fft_inplace(d_image_complex)cufft.fft_inplace(d_response_complex)vmult(d_image_complex, d_response_complex, out=d_image_complex)cufft.ifft_inplace(d_image_complex)cvimage_gpu = d_image_complex.copy_to_host().real / np.prod(image.shape)te = timer()print('GPU: %.2fs' % (te - ts))# 绘制结果plt.subplot(1, 2, 1)plt.title('CPU')plt.imshow(cvimage_cpu, cmap=plt.cm.gray)plt.axis('off')plt.subplot(1, 2, 2)plt.title('GPU')plt.imshow(cvimage_gpu, cmap=plt.cm.gray)plt.axis('off')plt.show()if __name__ == '__main__':main()看看运行结果:

时间对比:
Image size: (512L, 512L)
CPU: 0.66s
kernel config: (16, 64) x (32, 8)
GPU: 0.09s
[Finished in 61.4s]1.导入的包
-
Numpy提供常见的数学函数,包含许多有用的数学库
-
Scipy是python下的数值计算库,和Numpy一样是科学计算不可或缺的库
-
Matplotlib是用以绘制二维图形的Python模块
-
Numbapro是CUDA提供的专用库
-
timeit是计时工具
2.首先程序提供了一个测试数据集并进行转化,对于CPU部分,直接调用Scipy中的fftconvolve函数计算出结果,而GPU则主要调用了numbapro中cufft库,具体使用参考官方文档。
3.计算出结果后绘图展示,主要使用matplotlib的方法,只需设置plt对象并传入参数即可。
以上在代码中有详细注释,不一样展开。总的来说,使用GPU还是得参考官方的文档,并结合Python编程,才能解决复杂的问题并达到良好的效果。
第三篇
相信如果你使用过Python Numpy包,一定了解NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。它专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。 但是由于复杂的计算,Numpy的计算效率难免受到影响,因此我们对它进行了许多优化,用于优化的包有PyPy、Numba 与 Cython,而NumbaPro就是建立在Numba和cuda基础上的高级优化方法。 下面我们一起来看。 使用NumbaPro,我们可以对Numpy中的方法进行优化,使Python代码可以动态编译为机器码,并在运行中加载,使得GPU充分发挥多线程的优势。针对GPU,Numbapro也可以自动完成工作,并优化GPU体系结构的代码。另外,基于CUDA API编写的Python代码也可以有效地利用硬件。 说了这么多,下面就让我们从简单的示例开始学习。
from numbapro import vectorize
@vectorize(['float32(float32, float32)'], target='cpu')
def sum(a, b):return a + b 如果需要使用GPU来运行,只需要将第二行改成@vectorize(['float32(float32, float32)'], target='gpu')
对于更复杂的操作,可以使用Just-In-Time (JIT)来编译。
from numbapro import cuda@cuda.jit('void(float32[:], float32[:], float32[:])')
def sum(a, b, result):i = cuda.grid(1) # 等价于threadIdx.x + blockIdx.x * blockDim.xresult[i] = a[i] + b[i]# 调用: sum[grid_dim, block_dim](big_input_1, big_input_2, result_array)下面继续看一个具体的应用:
import numpy as np
import math
import time
from numba import *
from numbapro import cuda
from blackscholes_numba import black_scholes, black_scholes_numba
#import logging; logging.getLogger().setLevel(0)RISKFREE = 0.02
VOLATILITY = 0.30A1 = 0.31938153
A2 = -0.356563782
A3 = 1.781477937
A4 = -1.821255978
A5 = 1.330274429
RSQRT2PI = 0.39894228040143267793994605993438@cuda.jit(argtypes=(double,), restype=double, device=True, inline=True)
def cnd_cuda(d):K = 1.0 / (1.0 + 0.2316419 * math.fabs(d))ret_val = (RSQRT2PI * math.exp(-0.5 * d * d) *(K * (A1 + K * (A2 + K * (A3 + K * (A4 + K * A5))))))if d > 0:ret_val = 1.0 - ret_valreturn ret_val@cuda.jit(argtypes=(double[:], double[:], double[:], double[:], double[:],double, double))
def black_scholes_cuda(callResult, putResult, S, X,T, R, V):
# S = stockPrice
# X = optionStrike
# T = optionYears
# R = Riskfree
# V = Volatilityi = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.xif i >= S.shape[0]:returnsqrtT = math.sqrt(T[i])d1 = (math.log(S[i] / X[i]) + (R + 0.5 * V * V) * T[i]) / (V * sqrtT)d2 = d1 - V * sqrtTcndd1 = cnd_cuda(d1)cndd2 = cnd_cuda(d2)expRT = math.exp((-1. * R) * T[i])callResult[i] = (S[i] * cndd1 - X[i] * expRT * cndd2)putResult[i] = (X[i] * expRT * (1.0 - cndd2) - S[i] * (1.0 - cndd1))def randfloat(rand_var, low, high):return (1.0 - rand_var) * low + rand_var * highdef main (*args):OPT_N = 4000000iterations = 10if len(args) >= 2:iterations = int(args[0])callResultNumpy = np.zeros(OPT_N)putResultNumpy = -np.ones(OPT_N)stockPrice = randfloat(np.random.random(OPT_N), 5.0, 30.0)optionStrike = randfloat(np.random.random(OPT_N), 1.0, 100.0)optionYears = randfloat(np.random.random(OPT_N), 0.25, 10.0)callResultNumba = np.zeros(OPT_N)putResultNumba = -np.ones(OPT_N)callResultNumbapro = np.zeros(OPT_N)putResultNumbapro = -np.ones(OPT_N)time0 = time.time()for i in range(iterations):black_scholes(callResultNumpy, putResultNumpy, stockPrice,optionStrike, optionYears, RISKFREE, VOLATILITY)time1 = time.time()print("Numpy Time: %f msec" %((1000 * (time1 - time0)) / iterations))time0 = time.time()for i in range(iterations):black_scholes_numba(callResultNumba, putResultNumba, stockPrice,optionStrike, optionYears, RISKFREE, VOLATILITY)time1 = time.time()print("Numba Time: %f msec" %((1000 * (time1 - time0)) / iterations))time0 = time.time()blockdim = 1024, 1griddim = int(math.ceil(float(OPT_N)/blockdim[0])), 1stream = cuda.stream()d_callResult = cuda.to_device(callResultNumbapro, stream)d_putResult = cuda.to_device(putResultNumbapro, stream)d_stockPrice = cuda.to_device(stockPrice, stream)d_optionStrike = cuda.to_device(optionStrike, stream)d_optionYears = cuda.to_device(optionYears, stream)time1 = time.time()for i in range(iterations):black_scholes_cuda[griddim, blockdim, stream](d_callResult, d_putResult, d_stockPrice, d_optionStrike,d_optionYears, RISKFREE, VOLATILITY)d_callResult.to_host(stream)d_putResult.to_host(stream)stream.synchronize()time2 = time.time()dt = (time1 - time0) * 10 + (time2 - time1)print("numbapro.cuda time: %f msec" % ((1000 * dt) / iterations))delta = np.abs(callResultNumpy - callResultNumba)L1norm = delta.sum() / np.abs(callResultNumpy).sum()print("L1 norm: %E" % L1norm)print("Max absolute error: %E" % delta.max())delta = np.abs(callResultNumpy - callResultNumbapro)L1norm = delta.sum() / np.abs(callResultNumpy).sum()print("L1 norm (Numbapro): %E" % L1norm)print("Max absolute error (Numbapro): %E" % delta.max())if __name__ == "__main__":import sysmain(*sys.argv[1:])运行结果是:
Numpy Time: 1178.500009 msec
Numba Time: 424.500012 msec
numbapro.cuda time: 138.099957 msec可以看出,该程序是通过引入cuda对象并使用即时编译方法进行加速。 比较发现运行时间发现,运用numbapro方式加速效果明显。
总结:
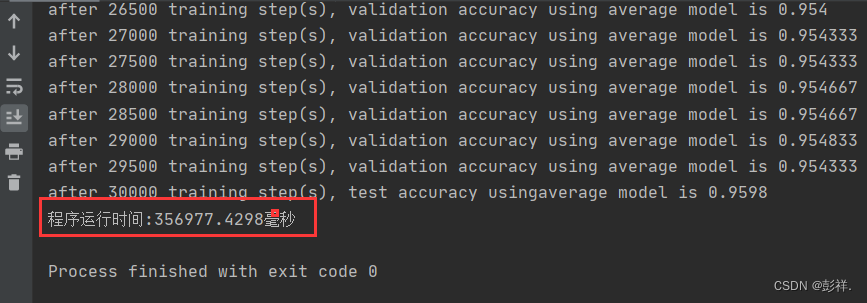
1.可以通过GPU编写数据并行处理的程序来加快处理速度。
2.可以使用CUDA库,例如cuRAND, cuBLAS, cuFFT 3.Python CUDA程序也可以最大化的使用硬件资源。
其他链接:
https://dask.org/
https://anaconda.org/talley/repo?type=conda&label=main