原文:https://blog.csdn.net/weiweigfkd/article/details/23051255
GPU加速技术&原理介绍
1、GPU&CPU
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。与CPU不同,GPU是专门为处理图形任务而产生的芯片。从这个任务定位上面来说,不仅仅在计算机的显卡上面,在手机、游戏机等等各种有多媒体处理需求的地方都可以见到GPU的身影。
在GPU出现之前,CPU一直负责着计算机中主要的运算工作,包括多媒体的处理工作。CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。但是如此设计的CPU在多媒体处理中的缺陷也显而易见:多媒体计算通常要求较高的运算密度、多并发线程和频繁地存储器访问,而由于X86平台中CISC(Complex Instruction Set Computer)架构中暂存器数量有限,CPU并不适合处理这种类型的工作。以Intel为代表的厂商曾经做过许多改进的尝试,从1999年开始为X86平台连续推出了多媒体扩展指令集——SSE(Streaming SIMD Extensions)的一代到四代版本,但由于多媒体计算对于浮点运算和并行计算效率的高要求,CPU从硬件本身上就难以满足其巨大的处理需求,仅仅在软件层面的改并不能起到根本效果。
对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像——也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。
因此CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。而GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。
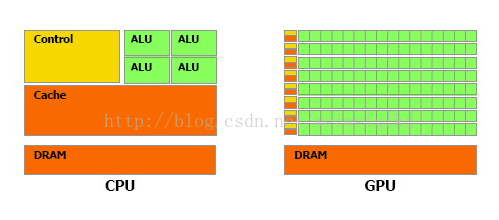
图1:CPU和GPU架构
随着计算机多媒体计算需求的持续发展,1999年Nvidia向市场推出了史上第一款GPU:Geforece 256(图2)。开启了GPU计算的历史。

图2:Nvidia Geforce256
2、GPU加速的原理
GPU一推出就包含了比CPU更多的处理单元,更大的带宽,使得其在多媒体处理过程中能够发挥更大的效能。例如:当前最顶级的CPU只有4核或者6核,模拟出8个或者12个处理线程来进行运算,但是普通级别的GPU就包含了成百上千个处理单元,高端的甚至更多,这对于多媒体计算中大量的重复处理过程有着天生的优势。下图展示了CPU和GPU架构的对比。
图3:CPU和GPU对比
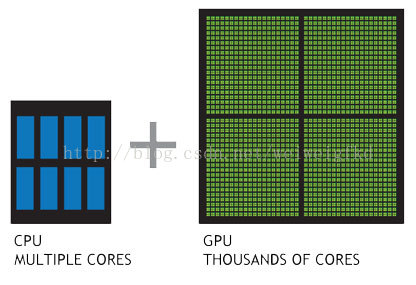
从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU 则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。
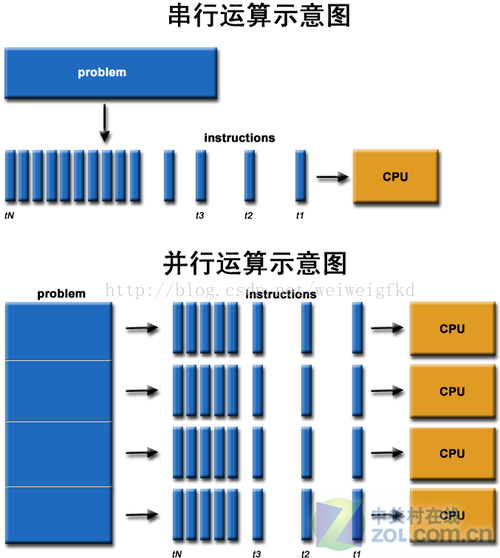
图4:串行和并行计算
通过上图我们可以较为容易地理解串行运算和并行运算之间的区别。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。
举个生活中的例子来说,你要点一份餐馆的外卖,CPU型餐馆用一辆大货车送货,每次可以拉很多外卖,但是送完一家才能到下一家送货,每个人收到外卖的时间必然很长;而GPU型餐馆用十辆小摩托车送货,每辆车送出去的不多,但是并行处理的效率高,点餐之后收货就会比大货车快很多。
下面一段视频也直观地展示了CPU和GPU处理效率上的区别。
http://v.youku.com/v_show/id_XNjY3MTY4NjAw.html
在1999年Nvidia推出Geforce的同时,还提出了GPGPU(GeneralPurpose GPU)的概念,即基于GPU的通用计算。CPU 包含几个专为串行处理而优化的核心,而 GPU 则由数以千计更小、更节能的核心组成,这些核心专为提供强劲的并行性能而设计。程序的串行部分在 CPU 上运行,而并行部分则在 GPU上运行。如此一来,能够最大程度地提高程序运行的效率。这就是GPU加速的基本思想。
3、GPU加速技术
当前CPU发展速度已经落后于摩尔定律,而GPU正以超过摩尔定律的速度快速发展。
在SIGGRAPH2003大会上,许多业界泰斗级人物发表了关于利用GPU进行各种运算的设想和实验模型。SIGGRAPH会议还特地安排了时间进行GPGPU的研讨交流。与此同时,在计算机进入DirectX 9 Shader Model 3.0时代,新的Shader Model在指令槽、流控制方面的显著增强使得对应GPU的可编程性能得到了大大的提升。GPGPU的研究由此进入快车道。
下面对几个值得关注的技术做简单介绍。
CUDA
为充分利用GPU的计算能力,NVIDIA在2006年推出了CUDA(ComputeUnified Device Architecture,统一计算设备架构)这一编程模型。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员现在可以使用C语言来为CUDA架构编写程序。
通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的QuadroGPU进行计算。以GeForce 8800 GTX为例,其核心拥有128个内处理器。利用CUDA技术,就可以将那些内处理器串通起来,成为线程处理器去解决数据密集的计算。而各个内处理器能够交换、同步和共享数据。
从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。
开发库是基于CUDA技术所提供的应用开发库。CUDA的1.1版提供了两个标准的数学运算库——CUFFT(离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上可以快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。
运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。
由于目前存在着多种GPU版本的NVIDIA显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。由于体系结构中硬件抽象层的存在,CUDA今后也有可能发展成为一个通用的GPGPU标准接口,兼容不同厂商的GPU产品
OpenCL
OpenCL是Open Computing Language(开放式计算语言)的简称,它是第一个为异构系统的通用并行编程而产生的统一的、免费的标准。OpenCL最早由苹果公司研发,其规范是由Khronos Group推出的。OpenCL支持由多核的CPU、GPU、Cell类型架构以及信号处理器(DSP)等其他的并行设备组成的异构系统。OpenCL的出现,使得软件开发人员编写高性能服务器、桌面计算系统以及手持设备的代码变得更加快捷。
OpenCL是一个为异构平台编写程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels (在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。其框架如下:
OpenCL平台API:平台API定义了宿主机程序发现OpenCL设备所用的函数以及这些函数的功能,另外还定义了为OpenCL应用创建上下文的函数。
OpenCL运行时API:这个API管理上下文来创建命令队列以及运行时发生的其他操作。例如,将命令提交到命令队列的函数就来自OpenCL运行时API。
OpenCL编程语言:这是用来编写内核代码的编程语言。它基于ISO C99标准的一个扩展子集,因此通常称为OpenCL C编程语言。
OpenCL由用于编写内核程序的语言和定义并控制平台的API组成,提供了基于任务和基于数据的两种并行计算机制,使得GPU的计算不在仅仅局限于图形领域,而能够进行更多的并行计算。OpenCL还是一个开放的工业标准,它可以为CPU和GPU等不同的设备组成的异构平台进行编程。OpenCL是一种语言,也是一个为并行编程而提供的框架,编程人员可以利用OpenCL编写出一个能够在GPU上执行的通用程序。在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
AMD Fusion
与Nvidia不同,AMD走了一条全新的路子:将CPU和GPU融为一体,打造了AMDFusion,即APU(Accelerated Processing Units)。这是AMD融聚未来理念的产品,它第一次将处理器和独显核心做在一个晶片上,协同计算、彼此加速,同时具有高性能处理器和最新支持DX11独立显卡的处理性能,大幅提升电脑运行效率,实现了CPU与GPU真正的融合。与传统的x86中央处理器相比, APU提出了“异构系统架构”(Heterogeneous System Architecture,HSA),即单芯片上两个不同的架构进行协同运作。以往集成图形核心一般是内置于主板的北桥中。而AMD Fusion项目则是结合现时的处理器和绘图核心,即是将处理一般事务的CPU核心、处理3D几何任务以及图形核心之扩展功能的现代GPU核心、以及主板的北桥融合到一块芯片上。这种设计允许一些应用程序或其相关链接界面来调用图形处理器来加速处理进程,例如OpenCL。
未来AMD将会在AMD APU上实现存储器统一寻址空间,使CPU和GPU进一步结合。最终的目标是要将图形处理器和中央处理器“深度集成”、“完全融合”,可根据任务类型自动分配运算任务予不同的运算单元中。
目前计算机业界认为,类似的统合技术将是未来处理器的一个主要发展方向。
4、GPU加速应用
BOINC平台的GPU加速项目
BOINC的中文全称是伯克利开放式网络计算平台(Berkeley Open Infrastructure for Network Computing),他能够把许多不同的分布式计算项目联系起来统一管理。并对计算机资源进行统一分配。BOINC目前已经成熟,多个项目已经成功运行于BOINC平台之上,如SETI@home、LHC@home、Rosetta@Home 、World Community Grid世界公共网格等。
图5:BOINC分布式计算平台
MilkyWay@home是一个基于 BOINC 平台的分布式运算项目。项目试图精确构建银河系附近星流的三维动态模型。项目的另一个目标是开发并优化分布式计算的算法。该项目在今年年初已经汇聚了超过1PetaFlops运算能力,运算速度超过了世界上第二快的超级计算机,该项目在推出后不久就提供了支持ATI显卡的运算程序。
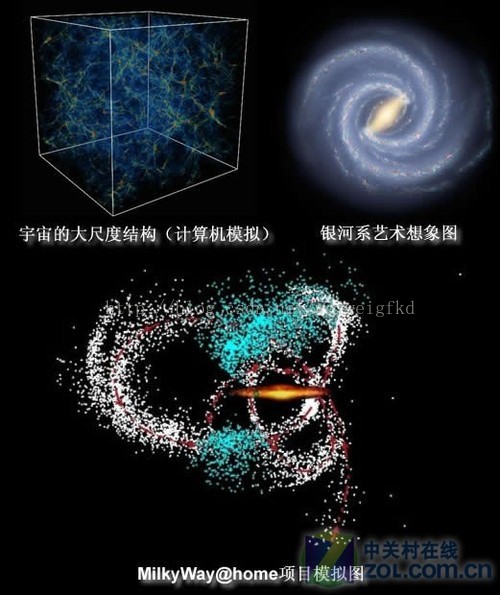
MilkyWay@home这个项目折射到计算机硬件方面,实际上就是像素对比,是对比进化算法得来的银河系演进图与真实拍得的照片的差异。它是按照进化算法先验算一个银河系在某时间断面的图,然后拿这个图跟拍摄的实际照片进行对比。Milkyway@home虽然是研究天体的项目,但这种研究算法天生具有遗传算法的特性,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;Milkyway@home提供的ATI显卡计算任务具有内在的隐并行性和更好的全局寻优能力,这个项目里更多的也不是分支嵌套,而是把算好的结果跟已知的观测结果进行比对,这样ATI GPU架构吞吐量巨大的优势就能够很好体现了。
另一个活跃在BOINC平台上的支持GPU计算的项目是CollatzConjecture,这是一个利用联网计算机进行数学方面研究,特别是测试又称为3X+1或者HOTPO(取半或乘三加一)的考拉兹猜想的研究项目。该项目的运算目的很简单,变量只有一个n,如果它是奇数,则对它乘3再加1,如果它是偶数,则对它除以2,如此循环,最终都能够得到1。这个项目的研究目标就是寻找最大的质数。
该项目的主程序分支出现在初始段,而且所有的线程的分支几乎都是统一的,所以对于分支能力的考验是比较少的,反而它能够使几乎所有线程都同步进行这个相对简单的吞吐过程。这就决定了该项目上ATI GPU的运算速度要比NVIDIA GPU快,因为ATI所提供的硬件结构更适应于这种数据结构。
最具影响力的Folding@home项目
Folding@home是一个研究蛋白质折叠,误折,聚合及由此引起的相关疾病的分布式计算项目。我们使用联网式的计算方式和大量的分布式计算能力来模拟蛋白质折叠的过程,并指引我们近期对由折叠引起的疾病的一系列研究,找到相关疾病的发病原因和治疗方法。
Folding@home能了解蛋白质折叠、误折以及相关的疾病。目前进行中的研究有:癌症、阿兹海默症(老年失智症)、亨廷顿病、成骨不全症、帕金森氏症、核糖体与抗生素。
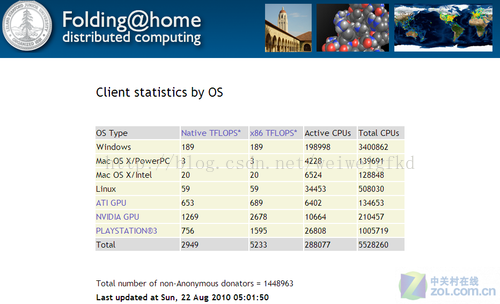
图7:不同硬件为Folding@home项目提供的运算能力
您可以在斯坦福大学官方网页上下载并运行客户端程序,随着更多志愿者的计算机加入,此项目计算的速度就越快,就会计算出蛋白质在更长时间内的折叠,距离科学家找到最终答案也就越来越近。如果蛋白质没有正确地折叠将会使人得一些病症:如阿兹海默氏症(Alzheimers)、囊肿纤维化(Cystic fibrosis)、疯牛病(Mad Cow, BSE)等, 甚至许多癌症的起因都是蛋白质的非正常折叠。
Folding@home所研究的是人类最基本的特定致病过程中蛋白质分子的折叠运动。项目的核心原理在于求解任务目标分子中每一个原子在边界条件限制下由肽键和长程力等作用所导致的运动方程,进而达到实现模拟任务目标分子折叠运动的目的。每一个原子背后都附庸这若干个方程,每一个方程都可以转换成一组简单的向量指令。同时由于长程力的影响,条件分支也随处可见,Folding@home在GPU使用量上也要大于图形编程。
图8:在分子动力学领域广泛使用的GROMACS引擎
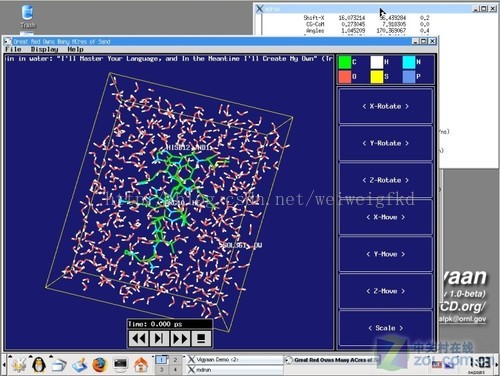
由于针对不同的系统其代码进行了高度优化,GROMACS是目前最快的分子动力学模拟软件。此外,由于支持不同的分子力场以及按照GPL协议发行,GROMACS拥有很高的可定制性。GROMACS目前最新版本为4.07,可以到官方网站下载并自行编译。GROMACS支持并行/网格计算扩展,可灵活搭配MPI规范的并行运算接口,如MPICH、MPICH2、MPILAM、DeoinMPI等。国内也有很多分子动力专业人员同样使用GROMACS做研究,GROMACS几乎成为模拟蛋白质折叠领域内的标准。
2006年9月底,ATI宣布了通用计算GPGPU架构,并得到了斯坦福大学Folding@Home项目的大力支持,加入了人类健康研究。2007年3月22日,PS3正式加入史丹佛大学分布式运算研究计划,至今已有超过百万名 PS3 玩家注册参与。NVIDIA于2008年6月宣布旗下基于G80及以上核心的显卡产品都支持该项目的通用计算,更是对分布式计算的重要贡献。
图9:Radeon HD4870显卡正在运行Folding@home项目
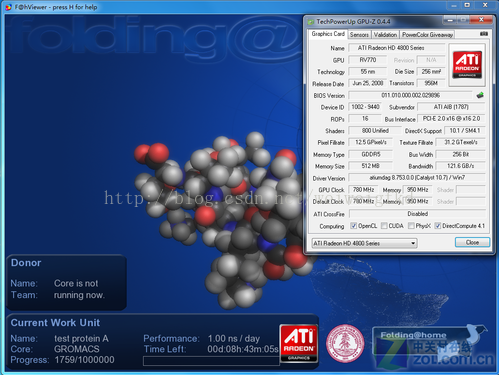
Folding@home在自身定位明确、成功发展的基础下,通过斯坦福大学的大力推广,已经获得了全世界广泛认同。而近期PS3和GPU的参与更是将Folding@home的运算能力推向高峰。值得一提的是NVIDIA在2008年6月果断宣布加入Folding@home项目,至今已经为该项目提供了超过2 PFlops运算能力。
目前Folding@Home已经成为全世界最有影响力和公信力的项目,同时是各大厂商和机构鼎力支持的项目,当然它毫无疑问地拥有最广大的志愿者团队——截止2010年4月18日,全球共计1,396,683人参与该项目,最近的统计显示志愿者贡献的总运算能力已经达到了5PFlops,远超现在全世界最快的超级计算机。
该项目在中国拥有约2000多名参与者,其中最强大的ChinaFolding@Home Power(Folding@Home中国力量,团队编号3213)团队已经拥有2585人,最近活跃用户200人以上,目前贡献计算量排名世界第47位,团队整体运算能力约为50到100TFLOPS。
GPU架构对于其他实例的适应性
前文提到的几种GPU计算项目,都是一些非常直接具体的科学计算项目,它们是用户直接体会GPU计算的最简单途径。除此之外,还有大量实例可以在GPU上完成运算,特别是ATI提供的这种硬件架构可以在一些特殊运算中获得极高的加速比。
比如对于那些很难解决或者不可能精确求解的问题,蒙特卡洛算法提供了一种近似的数值解决方法。蒙特卡洛仿真与生俱来的特征就是多次独立重复实验的使用,每次独立实验都有某些随机数驱动。根据大数定律,组合的实验次数越多,最后得到的平均答案就越接近于真实的答案。每次重复实验天生就具有较强的并行特征,而且它们通常由密集数操作组成,因此GPU几乎为蒙特卡洛仿真提供了一个完美的平台。
第二个要介绍的例子是使用GPU进行Nbody仿真。它在数值上近似地表示一个多体系统的演化过程,该系统中的一个体(Body)都持续地与所有其他的体相互作用。一个相似的例子是天体物理学仿真,在该仿真中,每个体代表一个星系或者一个独立运行的星系,各个体之间通过万有引力相互吸引,如图所示。在很多其他计算机科学问题中也会用到N-body仿真,例如蛋白质折叠就用到Nbody仿真计算静电荷范德华力。其他使用Nbody仿真的例子还有湍流流场仿真与全局光照计算等计算机图形学中的问题。
图10:DirectX 11 SDK Nbody Gravity测试项目
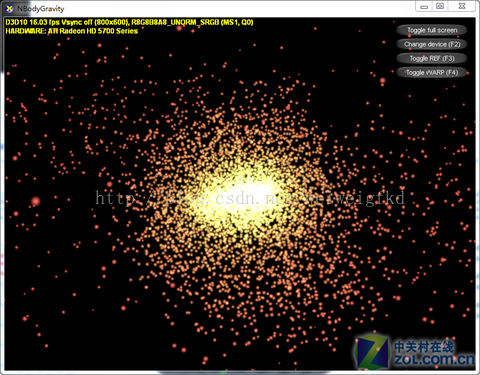
Nbody仿真问题的研究贯穿了整个计算科学的历史。在20世纪80年代,研究人员引进了分层和网格类型的算法,成功降低了计算复杂度。自从出现了并行计算机,Nbody仿真的并行化也开始被研究了。同时从CPU到GPU的现有研究成果不仅仅是为了降低运算的功耗,还可以降低分层度,节省远域计算的时间。
N Body Gravity测试具备两个显著的特点,首先是高并行度,该测试拥有大量相互碰撞的粒子,粒子之间会产生复杂而又数量较多的力量变化。同时该测试拥有较高的运算密度,GPU在处理此类问题时可以有效展现其强大的并行运算能力。在NVIDIA最初G80架构的Geforce 8800GTX GPU上每秒可以计算100多亿个引力系统的性能,这个成绩是一个经过高度优化的CPU实现的性能的50多倍。
图10:利用开源的杀毒软件ClamAV来基于GPU进行病毒检测
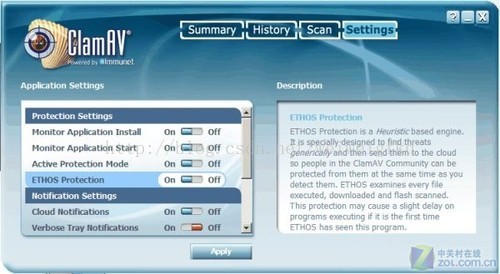
GPU还可以作为一个高速过滤器,来检验计算机病毒,这一原理和MilkyWay@home项目的像素对比有异曲同工之处。作为一个并行数据处理器,GPU擅长于处理那些具有常规的、固定大小的输入输出数据集合的算法任务。因为通过让CPU处理变长的和串行的任务,而GPU处理并行度较高的任务,可以最大限度地利用GPU进行病毒检测。GPU可以使用很少的字节来确定是否可能与数据库中的某个特征匹配,然后GPU再确认所有的匹配。