GPU加速技术&原理介绍
1、GPU&CPU
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。与CPU不同,GPU是专门为处理图形任务而产生的芯片。从这个任务定位上面来说,不仅仅在计算机的显卡上面,在手机、游戏机等等各种有多媒体处理需求的地方都可以见到GPU的身影。
在GPU出现之前,CPU一直负责着计算机中主要的运算工作,包括多媒体的处理工作。CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。但是如此设计的CPU在多媒体处理中的缺陷也显而易见:多媒体计算通常要求较高的运算密度、多并发线程和频繁地存储器访问,而由于X86平台中CISC(Complex Instruction Set Computer)架构中暂存器数量有限,CPU并不适合处理这种类型的工作。以Intel为代表的厂商曾经做过许多改进的尝试,从1999年开始为X86平台连续推出了多媒体扩展指令集——SSE(Streaming SIMD Extensions)的一代到四代版本,但由于多媒体计算对于浮点运算和并行计算效率的高要求,CPU从硬件本身上就难以满足其巨大的处理需求,仅仅在软件层面的改并不能起到根本效果。
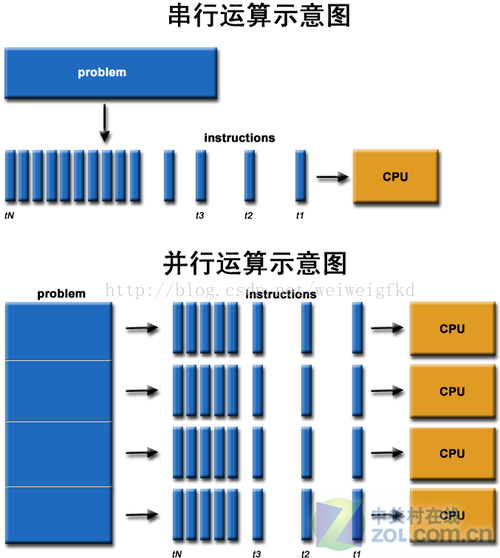
对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像——也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。
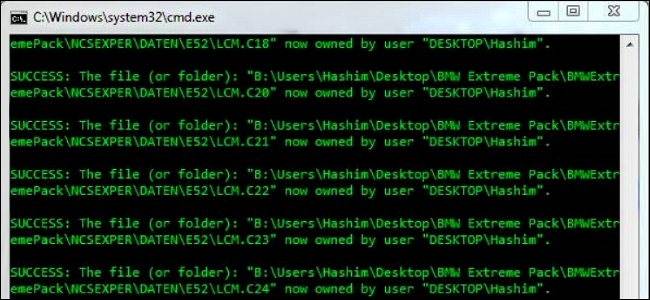
因此CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。而GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。
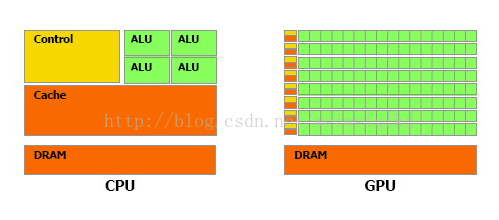
图1:CPU和GPU架构
随着计算机多媒体计算需求的持续发展,1999年Nvidia向市场推出了史上第一款GPU:Geforece 256(图2)。开启了GPU计算的历史。

图2:Nvidia Geforce256
2、GPU加速的原理
GPU一推出就包含了比CPU更多的处理单元,更大的带宽,使得其在多媒体处理过程中能够发挥更大的效能。例如:当前最顶级的CPU只有4核或者6核,模拟出8个或者12个处理线程来进行运算,但是普通级别的GPU就包含了成百上千个处理单元,高端的甚至更多,这对于多媒体计算中大量的重复处理过程有着天生的优势。下图展示了CPU和GPU架构的对比。
图3:CPU和GPU对比
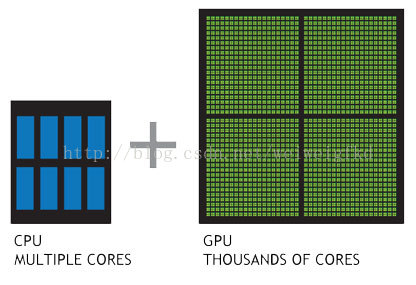
从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU 则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。