我们在安装tensorflow-gpu后,其运行时我们可以选定使用gpu来进行加速训练,这无疑会帮助我们加快训练脚步。
(注意:当我们的tensorflow-gpu安装后,其默认会使用gpu来训练)
之前博主已经为自己的python环境安装了tensorflow-gpu,详情参考:
Tensorflow安装
安装完成后,我们以BP神经网络算法实现手写数字识别这个项目为例
首先先对BP神经网络的原理进行简单理解
BP神经网络实现手写数字识别
# -*- coding: utf-8 -*-"""
手写数字识别, BP神经网络算法
"""
# -------------------------------------------
'''
使用python解析二进制文件
'''
import numpy as np
import struct
import random
import tensorflow as tf
from sklearn.model_selection import train_test_splitimport os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 强制使用cpu
import time
T1 = time.clock()
class LoadData(object):def __init__(self, file1, file2):self.file1 = file1self.file2 = file2# 载入训练集def loadImageSet(self):binfile = open(self.file1, 'rb') # 读取二进制文件buffers = binfile.read() # 缓冲head = struct.unpack_from('>IIII', buffers, 0) # 取前4个整数,返回一个元组offset = struct.calcsize('>IIII') # 定位到data开始的位置imgNum = head[1] # 图像个数width = head[2] # 行数,28行height = head[3] # 列数,28bits = imgNum*width*height # data一共有60000*28*28个像素值bitsString = '>' + str(bits) + 'B' # fmt格式:'>47040000B'imgs = struct.unpack_from(bitsString, buffers, offset) # 取data数据,返回一个元组binfile.close()imgs = np.reshape(imgs, [imgNum, width*height])return imgs, head# 载入训练集标签def loadLabelSet(self):binfile = open(self.file2, 'rb') # 读取二进制文件buffers = binfile.read() # 缓冲head = struct.unpack_from('>II', buffers, 0) # 取前2个整数,返回一个元组offset = struct.calcsize('>II') # 定位到label开始的位置labelNum = head[1] # label个数numString = '>' + str(labelNum) + 'B'labels = struct.unpack_from(numString, buffers, offset) # 取label数据binfile.close()labels = np.reshape(labels, [labelNum]) # 转型为列表(一维数组)return labels, head# 将标签拓展为10维向量def expand_lables(self):labels, head = self.loadLabelSet()expand_lables = []for label in labels:zero_vector = np.zeros((1, 10))zero_vector[0, label] = 1expand_lables.append(zero_vector)return expand_lables# 将样本与标签组合成数组[[array(data), array(label)], []...]def loadData(self):imags, head = self.loadImageSet()expand_lables = self.expand_lables()data = []for i in range(imags.shape[0]):imags[i] = imags[i].reshape((1, 784))data.append([imags[i], expand_lables[i]])return datafile1 = r'train-images.idx3-ubyte'
file2 = r'train-labels.idx1-ubyte'
trainingData = LoadData(file1, file2)
training_data = trainingData.loadData()
file3 = r't10k-images.idx3-ubyte'
file4 = r't10k-labels.idx1-ubyte'
testData = LoadData(file3, file4)
test_data = testData.loadData()
X_train = [i[0] for i in training_data]
y_train = [i[1][0] for i in training_data]
X_test = [i[0] for i in test_data]
y_test = [i[1][0] for i in test_data]X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.1, random_state=7)
# print(np.array(X_test).shape)
# print(np.array(y_test).shape)
# print(np.array(X_train).shape)
# print(np.array(y_train).shape)INUPUT_NODE = 784
OUTPUT_NODE = 10LAYER1_NODE = 500
BATCH_SIZE = 200
LERANING_RATE_BASE = 0.005 # 基础的学习率
LERANING_RATE_DACAY = 0.99 # 学习率的衰减率
REGULARZATION_RATE = 0.01 # 正则化项在损失函数中的系数
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均衰减率# 三层全连接神经网络,滑动平均类
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):if not avg_class:layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1)+biases1)# 没有使用softmax层输出return tf.matmul(layer1, weights2)+biases2else:layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1))+avg_class.average(biases1))return tf.matmul(layer1, avg_class.average(weights2))+avg_class.average(biases2)def train(X_train, X_validation, y_train, y_validation, X_test, y_test):x = tf.placeholder(tf.float32, [None, INUPUT_NODE], name="x-input")y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name="y-input")# 生成隐藏层weights1 = tf.Variable(tf.truncated_normal([INUPUT_NODE, LAYER1_NODE], stddev=0.1))biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))# 生成输出层weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))y = inference(x, None, weights1, biases1, weights2, biases2)global_step = tf.Variable(0, trainable=False)variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)variable_averages_op = variable_averages.apply(tf.trainable_variables())average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))cross_entropy_mean = tf.reduce_mean(cross_entropy)# L2正则化损失regularizer = tf.contrib.layers.l2_regularizer(REGULARZATION_RATE)regularization = regularizer(weights1) + regularizer(weights2)loss = cross_entropy_mean + regularization# 指数衰减的学习率learning_rate = tf.train.exponential_decay(LERANING_RATE_BASE,global_step,len(X_train)/BATCH_SIZE,LERANING_RATE_DACAY)train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)with tf.control_dependencies([train_step, variable_averages_op]):train_op = tf.no_op(name='train')correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)validation_feed = {x: X_validation, y_: y_validation}train_feed = {x: X_train, y_: y_train}test_feed = {x: X_test, y_: y_test}for i in range(TRAINING_STEPS):if i % 500 == 0:validate_acc = sess.run(accuracy, feed_dict=validation_feed)print("after %d training step(s), validation accuracy ""using average model is %g" % (i, validate_acc))start = (i * BATCH_SIZE) % len(X_train)end = min(start + BATCH_SIZE, len(X_train))sess.run(train_op,feed_dict={x: X_train[start:end], y_: y_train[start:end]})# print('loss:', sess.run(loss))test_acc = sess.run(accuracy, feed_dict=test_feed)print("after %d training step(s), test accuracy using""average model is %g" % (TRAINING_STEPS, test_acc))train(X_train, X_validation, y_train, y_validation, X_test, y_test)
T2 = time.clock()
print('程序运行时间:%s毫秒' % ((T2 - T1)*1000))
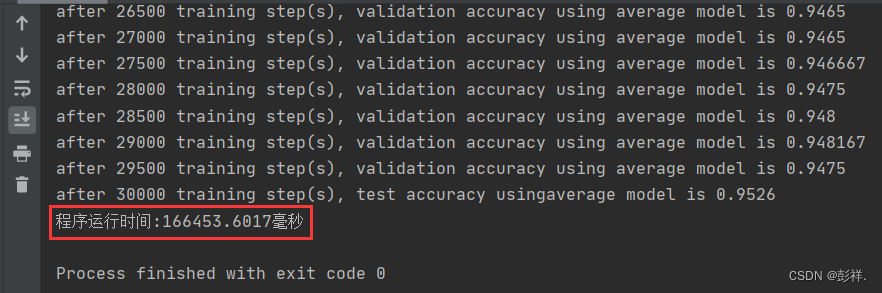
GPU运行结果
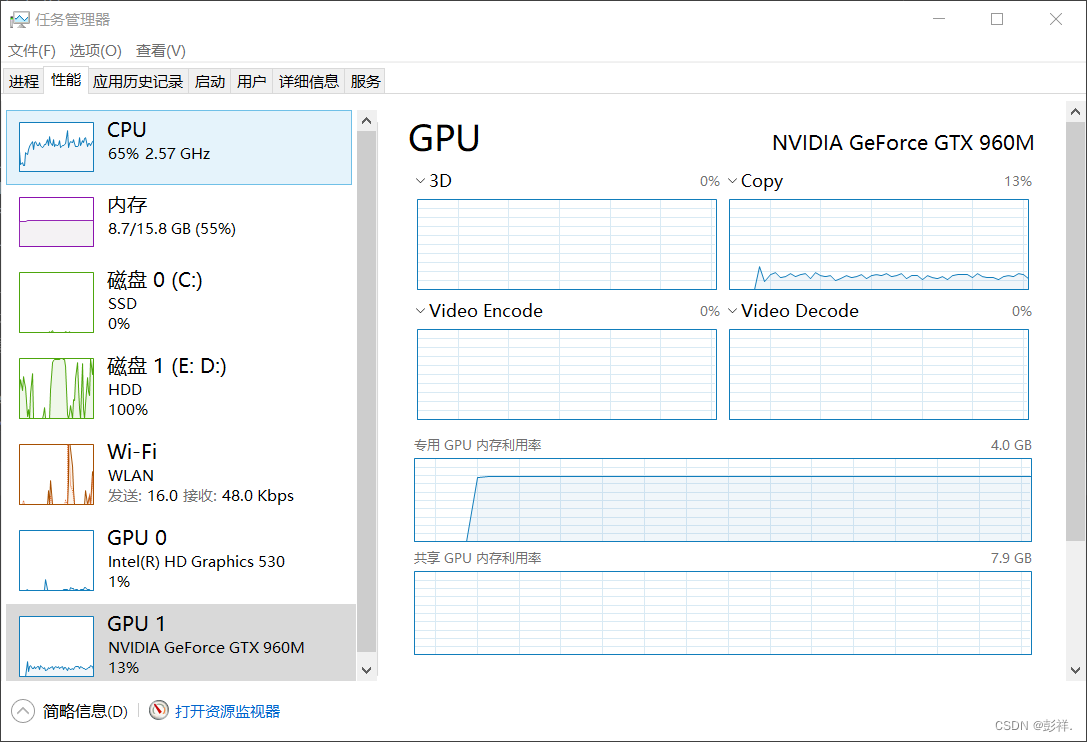
CPU运行结果
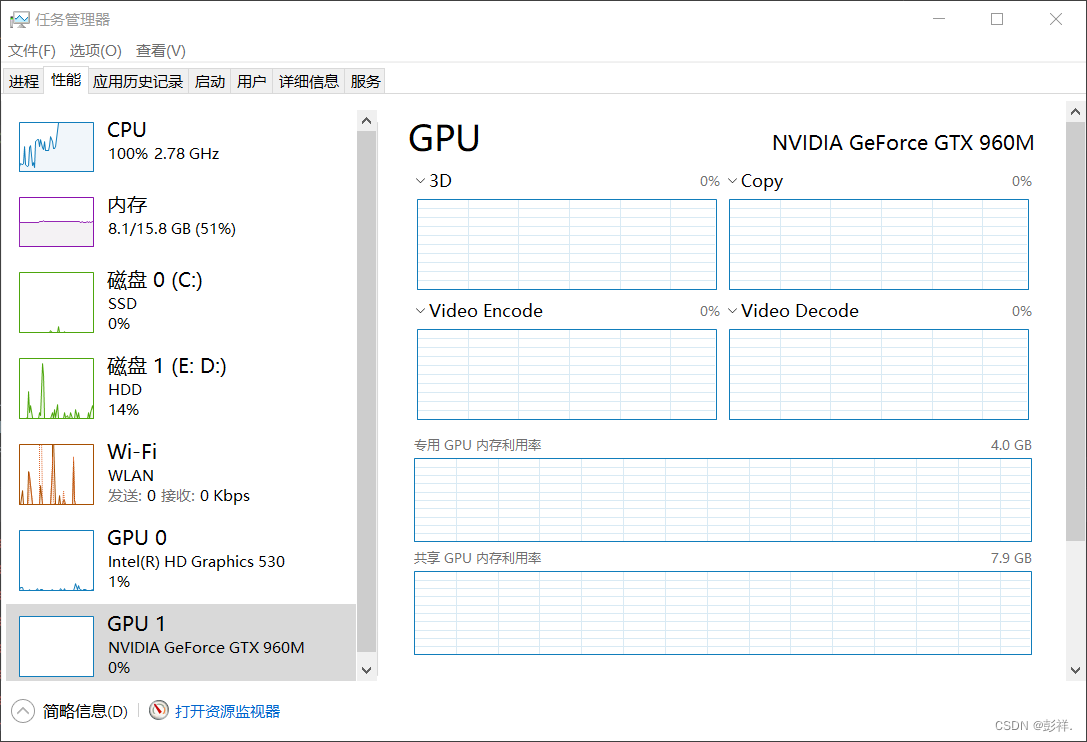
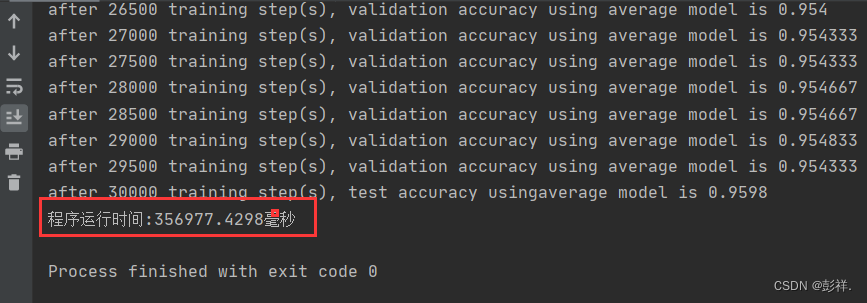
从运行结果来看,两者运行时间相差两倍
博主的显卡太拉跨了,看别人的测试两者可谓天差地别,呜呜呜,但好歹也算是有些加速效果吧,拜拜!