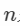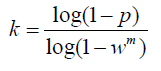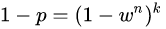1、算法概述:
RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
2、算法思想描述:
RANSAC基本思想描述如下:
①考虑一个最小抽样集的势为n的模型(n为初始化模型参数所需的最小样本数)和一个样本集P,集合P的样本数#(P)>n,从P中随机抽取包含n个样本的P的子集S初始化模型M;
②余集SC=P\S中与模型M的误差小于某一设定阈值t的样本集以及S构成S*。S*认为是内点集,它们构成S的一致集(Consensus Set);
③若#(S*)≥N,认为得到正确的模型参数,并利用集S*(内点inliers)采用最小二乘等方法重新计算新的模型M*;重新随机抽取新的S,重复以上过程。
④在完成一定的抽样次数后,若未找到一致集则算法失败,否则选取抽样后得到的最大一致集判断内外点,算法结束。
3、算法的基本假设:
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
参考http://www.cnblogs.com/xrwang/archive/2011/03/09/ransac-1.html
给定两个点p1与p2的坐标,确定这两点所构成的直线,要求对于输入的任意点p3,都可以判断它是否在该直线上。初中解析几何知识告诉我们,判断一个点在直线上,只需其与直线上任意两点点斜率都相同即可。实际操作当中,往往会先根据已知的两点算出直线的表达式(点斜式、截距式等等),然后通过向量计算即可方便地判断p3是否在该直线上。
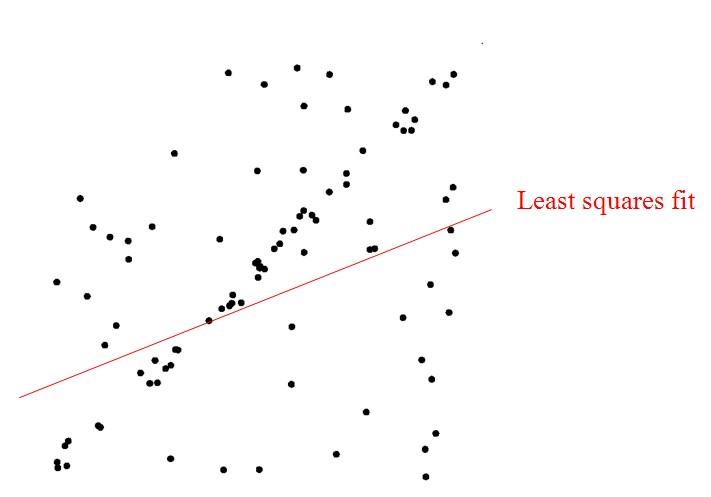
生产实践中的数据往往会有一定的偏差。例如我们知道两个变量X与Y之间呈线性关系,Y=aX+b,我们想确定参数a与b的具体值。通过实验,可以得到一组X与Y的测试值。虽然理论上两个未知数的方程只需要两组值即可确认,但由于系统误差的原因,任意取两点算出的a与b的值都不尽相同。我们希望的是,最后计算得出的理论模型与测试值的误差最小。大学的高等数学课程中,详细阐述了最小二乘法的思想。通过计算最小均方差关于参数a、b的偏导数为零时的值。事实上,在很多情况下,最小二乘法都是线性回归的代名词。
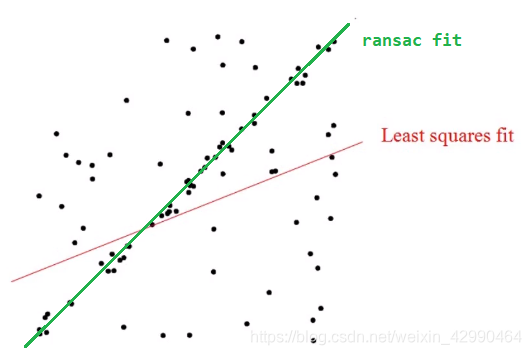
遗憾的是,最小二乘法只适合与误差较小的情况。试想一下这种情况,假使需要从一个噪音较大的数据集中提取模型(比方说只有20%的数据时符合模型的)时,最小二乘法就显得力不从心了。例如下图,肉眼可以很轻易地看出一条直线(模式),但算法却找错了。

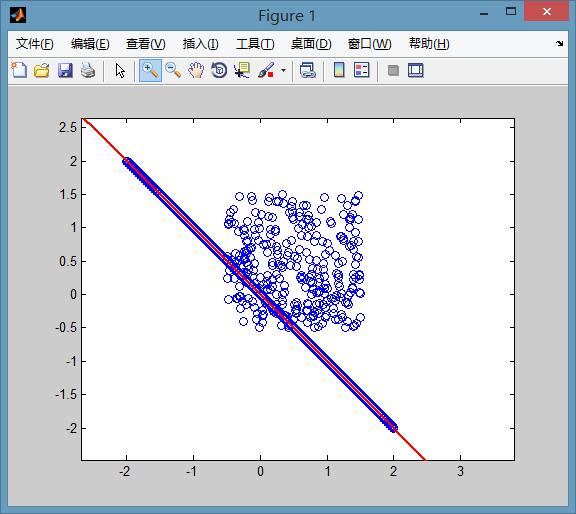
RANSAC算法的输入是一组观测数据(往往含有较大的噪声或无效点),一个用于解释观测数据的参数化模型以及一些可信的参数。RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
整个过程可参考下图:

5、算法
生产实践中的数据往往会有一定的偏差。例如我们知道两个变量X与Y之间呈线性关系,Y=aX+b,我们想确定参数a与b的具体值。通过实验,可以得到一组X与Y的测试值。虽然理论上两个未知数的方程只需要两组值即可确认,但由于系统误差的原因,任意取两点算出的a与b的值都不尽相同。我们希望的是,最后计算得出的理论模型与测试值的误差最小。大学的高等数学课程中,详细阐述了最小二乘法的思想。通过计算最小均方差关于参数a、b的偏导数为零时的值。事实上,在很多情况下,最小二乘法都是线性回归的代名词。
遗憾的是,最小二乘法只适合与误差较小的情况。试想一下这种情况,假使需要从一个噪音较大的数据集中提取模型(比方说只有20%的数据时符合模型的)时,最小二乘法就显得力不从心了。例如下图,肉眼可以很轻易地看出一条直线(模式),但算法却找错了。
RANSAC算法的输入是一组观测数据(往往含有较大的噪声或无效点),一个用于解释观测数据的参数化模型以及一些可信的参数。RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
- 有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
- 用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
- 如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
- 然后,用所有假设的局内点去重新估计模型(譬如使用最小二乘法),因为它仅仅被初始的假设局内点估计过。
- 最后,通过估计局内点与模型的错误率来评估模型。
- 上述过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
整个过程可参考下图:
5、算法
5.1、伪代码的表示形式
伪码形式的算法如下所示:
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数(如果没有找到好的模型,返回null)
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
RANSAC算法的可能变化包括以下几种:
(1)如果发现了一种足够好的模型(该模型有足够小的错误率),则跳出主循环。这样可能会节约计算额外参数的时间。
(2)直接从maybe_model计算this_error,而不从consensus_set重新估计模型。这样可能会节约比较两种模型错误的时间,但可能会对噪声更敏感。
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数(如果没有找到好的模型,返回null)
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
RANSAC算法的可能变化包括以下几种:
(1)如果发现了一种足够好的模型(该模型有足够小的错误率),则跳出主循环。这样可能会节约计算额外参数的时间。
(2)直接从maybe_model计算this_error,而不从consensus_set重新估计模型。这样可能会节约比较两种模型错误的时间,但可能会对噪声更敏感。
5.2、关于算法的源代码,Ziv Yaniv曾经写一个不错的C++版本,我在关键处增补了注释:
C代码 
- #include
<math.h> - #include
"LineParamEstimator.h" -
- LineParamEstimator::LineParamEstimator(double
delta) : m_deltaSquared(delta*delta) {} -
-
- void
LineParamEstimator::estimate(std::vector<Point2D *> &data, -
std::vector<double> ¶meters) - {
-
parameters.clear(); -
if(data.size()<2) -
return; -
double nx = data[1]->y - data[0]->y; -
double ny = data[0]->x - data[1]->x;// 原始直线的斜率为K,则法线的斜率为-1/k -
double norm = sqrt(nx*nx + ny*ny); -
-
parameters.push_back(nx/norm); -
parameters.push_back(ny/norm); -
parameters.push_back(data[0]->x); -
parameters.push_back(data[0]->y); - }
-
-
- void
LineParamEstimator::leastSquaresEstimate(std::vector<Point2D *> &data, -
std::vector<double> ¶meters) - {
-
double meanX, meanY, nx, ny, norm; -
double covMat11, covMat12, covMat21, covMat22; // The entries of the symmetric covarinace matrix -
int i, dataSize = data.size(); -
-
parameters.clear(); -
if(data.size()<2) -
return; -
-
meanX = meanY = 0.0; -
covMat11 = covMat12 = covMat21 = covMat22 = 0; -
for(i=0; i<dataSize; i++) { -
meanX +=data[i]->x; -
meanY +=data[i]->y; -
-
covMat11 +=data[i]->x * data[i]->x; -
covMat12 +=data[i]->x * data[i]->y; -
covMat22 +=data[i]->y * data[i]->y; -
} -
-
meanX/=dataSize; -
meanY/=dataSize; -
-
covMat11 -= dataSize*meanX*meanX; -
covMat12 -= dataSize*meanX*meanY; -
covMat22 -= dataSize*meanY*meanY; -
covMat21 = covMat12; -
-
if(covMat11<1e-12) { -
nx = 1.0; -
ny = 0.0; -
} -
else { //lamda1 is the largest eigen-value of the covariance matrix -
//and is used to compute the eigne-vector corresponding to the smallest -
//eigenvalue, which isn't computed explicitly. -
double lamda1 = (covMat11 + covMat22 + sqrt((covMat11-covMat22)*(covMat11-covMat22) + 4*covMat12*covMat12)) / 2.0; -
nx = -covMat12; -
ny = lamda1 - covMat22; -
norm = sqrt(nx*nx + ny*ny); -
nx/=norm; -
ny/=norm; -
} -
parameters.push_back(nx); -
parameters.push_back(ny); -
parameters.push_back(meanX); -
parameters.push_back(meanY); - }
-
-
- bool
LineParamEstimator::agree(std::vector<double> ¶meters, Point2D &data) - {
-
double signedDistance = parameters[0]*(data.x-parameters[2]) + parameters[1]*(data.y-parameters[3]); -
return ((signedDistance*signedDistance) < m_deltaSquared); - }
RANSAC寻找匹配的代码如下:
C代码
-
- template<class
T, class S> - double
Ransac<T,S>::compute(std::vector<S> ¶meters, -
ParameterEsitmator<T,S> *paramEstimator , -
std::vector<T> &data, -
int numForEstimate) - {
-
std::vector<T *> leastSquaresEstimateData ; -
int numDataObjects = data.size(); -
int numVotesForBest = -1; -
int *arr = new int[numForEstimate];// numForEstimate表示拟合模型所需要的最少点数,对本例的直线来说,该值为2 -
short *curVotes = new short[numDataObjects]; //one if data[i] agrees with the current model, otherwise zero -
short *bestVotes = new short[numDataObjects]; //one if data[i] agrees with the best model, otherwise zero -
-
-
//there are less data objects than the minimum required for an exact fit -
if(numDataObjects < numForEstimate) -
return 0; -
// 计算所有可能的直线,寻找其中误差最小的解。对于100点的直线拟合来说,大约需要100*99*0.5=4950次运算,复杂度无疑是庞大的。一般采用随机选取子集的方式。 -
computeAllChoices(paramEstimator,data,numForEstimate, -
bestVotes, curVotes, numVotesForBest, 0, data.size(), numForEstimate, 0, arr); -
-
//compute the least squares estimate using the largest sub set -
for(int j=0; j<numDataObjects; j++) { -
if(bestVotes[j]) -
leastSquaresEstimateData .push_back(&(data[j])); -
} -
// 对局内点再次用最小二乘法拟合出模型 -
paramEstimator->leastSquaresEstimate(leastSquaresEstimateData ,parameters); -
-
delete [] arr; -
delete [] bestVotes; -
delete [] curVotes; -
-
return (double)leastSquaresEstimateData .size()/(double)numDataObjects; - }
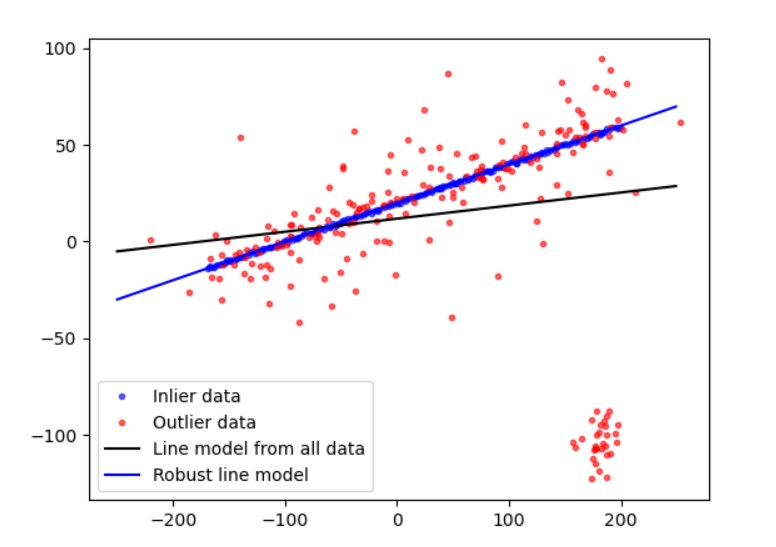
在模型确定以及最大迭代次数允许的情况下,RANSAC总是能找到最优解。经过我的实验,对于包含80%误差的数据集,RANSAC的效果远优于直接的最小二乘法。
RANSAC可以用于哪些场景呢?最著名的莫过于图片的拼接技术 。优于镜头的限制,往往需要多张照片才能拍下那种巨幅的风景。在多幅图像合成时,事先会在待合成的图片中提取一些关键的特征点。计算机视觉的研究表明,不同视角下物体往往可以通过一个透视矩(3X3或2X2)阵的变换而得到。RANSAC被用于拟合这个模型的参数(矩阵各行列的值),由此便可识别出不同照片中的同一物体。可参考下图:



另外,RANSAC还可以用于图像搜索时的纠错与物体识别定位。下图中,有几条直线是SIFT匹配算法的误判,RANSAC有效地将其识别,并将正确的模型(书本)用线框标注出来:

6、参数
我们不得不根据特定的问题和数据集通过实验来确定参数t和d。然而参数k(迭代次数)可以从理论结果推断。当我们从估计模型参数时,用p表示一些迭代过程中从数据集内随机选取出的点均为局内点的概率;此时,结果模型很可能有用,因此p也表征了算法产生有用结果的概率。用w表示每次从数据集中选取一个局内点的概率,如下式所示:
w = 局内点的数目 / 数据集的数目
通常情况下,我们事先并不知道w的值,但是可以给出一些鲁棒的值。假设估计模型需要选定n个点,wn是所有n个点均为局内点的概率;1 − wn是n个点中至少有一个点为局外点的概率,此时表明我们从数据集中估计出了一个不好的模型。 (1 − wn)k表示算法永远都不会选择到n个点均为局内点的概率,它和1-p相同。因此,
1 − p = (1 − wn)k
我们对上式的两边取对数,得出

值得注意的是,这个结果假设n个点都是独立选择的;也就是说,某个点被选定之后,它可能会被后续的迭代过程重复选定到。这种方法通常都不合理,由此推导出的k值被看作是选取不重复点的上限。例如,要从上图中的数据集寻找适合的直线,RANSAC算法通常在每次迭代时选取2个点,计算通过这两点的直线maybe_model,要求这两点必须唯一。
为了得到更可信的参数,标准偏差或它的乘积可以被加到k上。k的标准偏差定义为:

w = 局内点的数目 / 数据集的数目
通常情况下,我们事先并不知道w的值,但是可以给出一些鲁棒的值。假设估计模型需要选定n个点,wn是所有n个点均为局内点的概率;1 − wn是n个点中至少有一个点为局外点的概率,此时表明我们从数据集中估计出了一个不好的模型。 (1 − wn)k表示算法永远都不会选择到n个点均为局内点的概率,它和1-p相同。因此,
1 − p = (1 − wn)k
我们对上式的两边取对数,得出
值得注意的是,这个结果假设n个点都是独立选择的;也就是说,某个点被选定之后,它可能会被后续的迭代过程重复选定到。这种方法通常都不合理,由此推导出的k值被看作是选取不重复点的上限。例如,要从上图中的数据集寻找适合的直线,RANSAC算法通常在每次迭代时选取2个点,计算通过这两点的直线maybe_model,要求这两点必须唯一。
为了得到更可信的参数,标准偏差或它的乘积可以被加到k上。k的标准偏差定义为:
7、优点与缺点
RANSAC的优点是它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。RANSAC的缺点是它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。RANSAC的另一个缺点是它要求设置跟问题相关的阀值。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。