第一范式、第二范式、第三范式
参考了https://www.zhihu.com/question/24696366
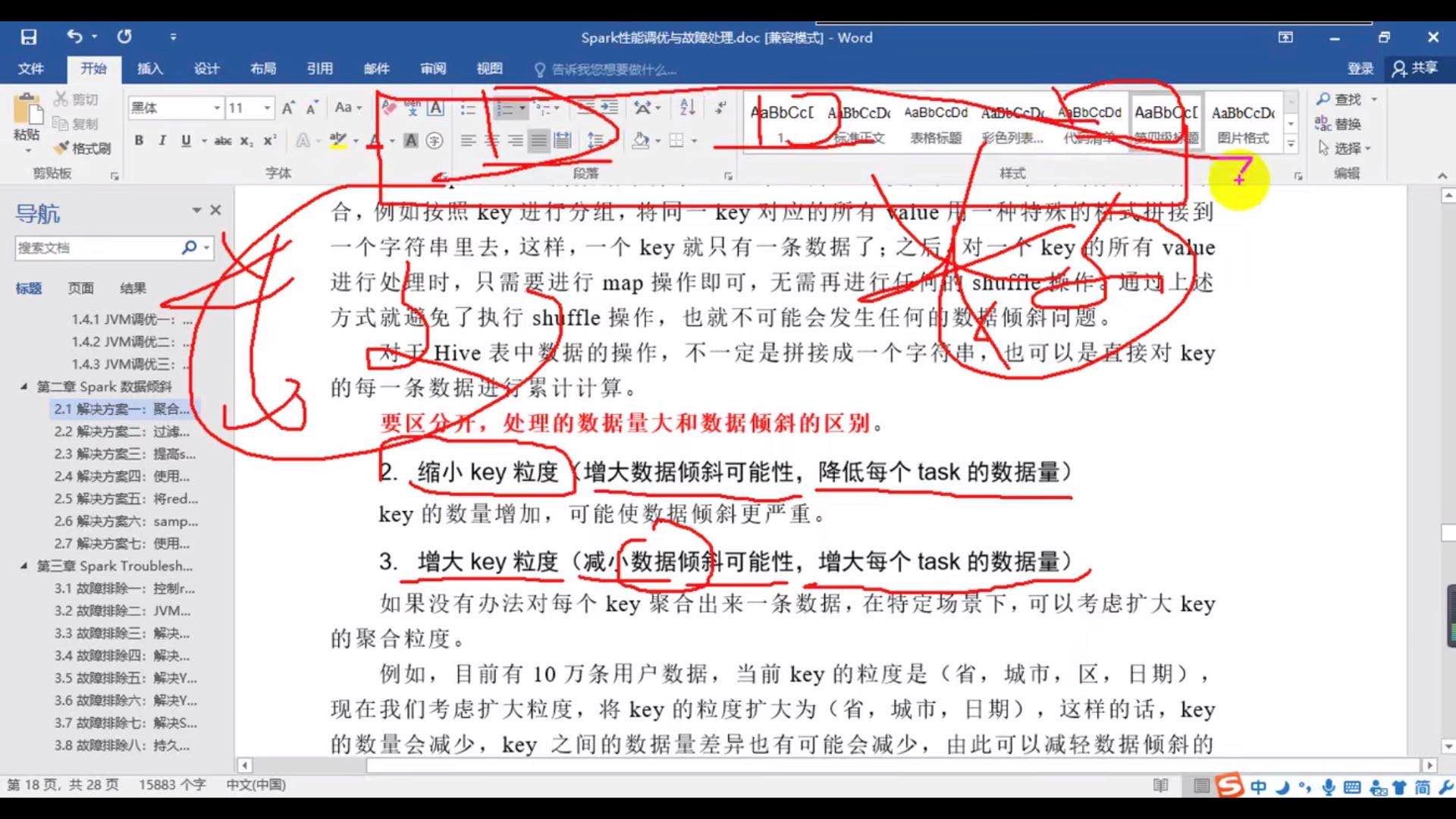
https://www.cnblogs.com/lca1826/p/6601395.html
基础知识
实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,比如说“老师与学校的关系”。
属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
第一范式
第一范式列不能再分。
第二范式
第二范式建立在第一范式的基础上,非主属性完全依赖于码。
简单说:消除部分依赖。
(什么是码?) 表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。主码可以包含多个属性。
要理解第二第三范式需要理解完全函数依赖、部分函数依赖、传递函数依赖。
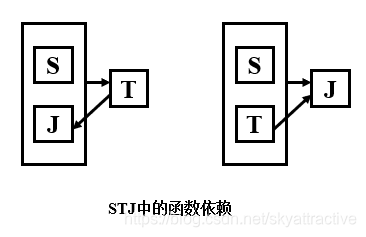
完全函数依赖
定义:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
比如通过学号->姓名
部分函数依赖
定义:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。
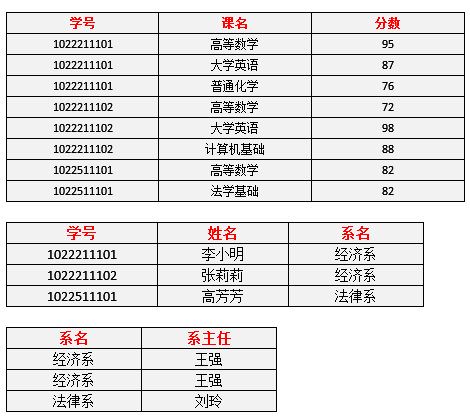
需要借用知乎刘慰教师的例子用一下,自己也理解了很长时间。
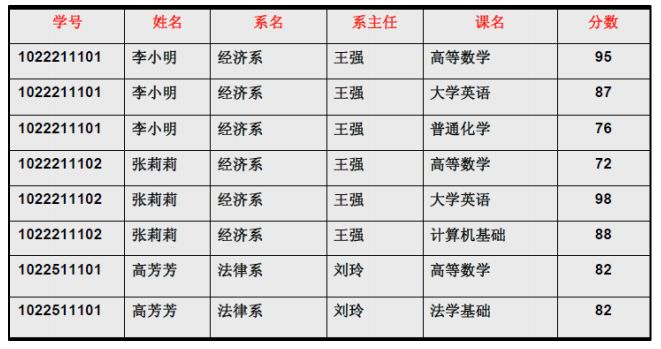
码用(学号+课程),为什么要加课程呢?因为不同课程成绩是通过学号查不出来的。
不过用(学号+课程)当作码是不是有些问题?
(学号+课程)->姓名,但是学号->姓名
(学号+课程)->系名,但是学号->系名
(学号+课程)->系主任,但是学号->系主任
这个就是部分依赖,说实话我看定义一脸懵逼。
要是上面那张表符合第二范式。需要将表拆分为两张表。
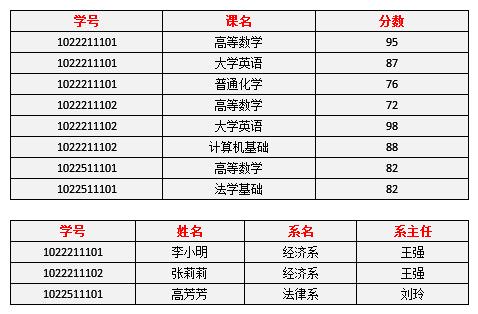
一张是 学号、课程、分数表
另外一张是 学号、姓名、系名、系主任表
传递函数依赖
设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
https://blog.csdn.net/rl529014/article/details/48391465
采用这位大佬的例子
在关系R(学号 ,宿舍, 费用)中,(学号)->(宿舍),宿舍!=学号,(宿舍)->(费用),费用!=宿舍,所以符合传递函数的要求
第三范式
满足第二范式的条件下不存在传递函数依赖。
要满足第三范式,在分成两张表的时候第二张表还是有问题?
学号->系名,系名->系主任 传递依赖。
需要将系名和系主任另外新建一张表。
总结:
第一范式:简单说 列不能再分
第二范式:简单说 建立在第一范式基础上,消除部分依赖
第三范式:简单说 建立在第二范式基础上,消除传递依赖。
码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
BCNF范式
https://www.2cto.com/database/201404/290140.html
BCNF是3NF的改进形式
一个满足BCNF的关系模式的条件:
1.所有非主属性对每一个码都是完全函数依赖。
2.所有的主属性对每一个不包含它的码,也是完全函数依赖。
3.没有任何属性完全函数依赖于非码的任何一组属性。
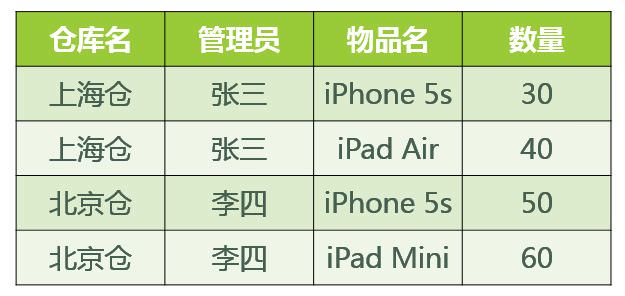
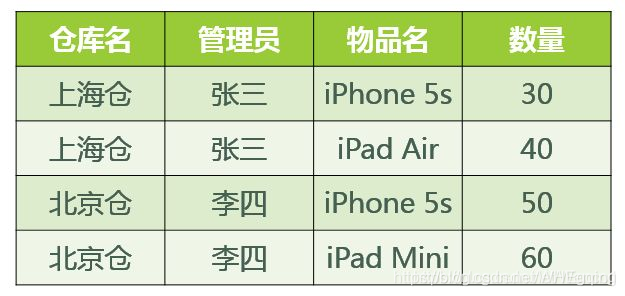
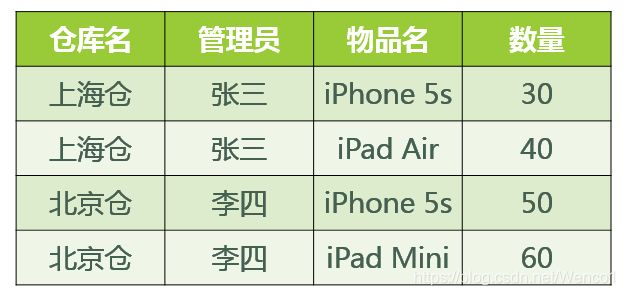
如上表
(仓库名,管理员)->(物品名,数量)
(管理员,物品名)->(仓库名,数量)
但是(仓库名)->(管理员) 不满足第二条
所以需要改成两种表:
第一张:仓库名,管理员
第二张:仓库名,物品名,数量