1.变分推断简称VI,是一种确定性近似推断方法
2.基于平均场理论的VI是假设q(z)可以分解为M个独立qi
3.采取坐标上升法可以求解VI问题
4.VI有两个局限:假设太强,同时积分也不一定能算
5.为了解决积分不能算问题,考虑采取随机梯度法进行求解,这就有SGVI
6.变分L(Φ)关于q(z)的梯度通过期望相联系,这个期望通过蒙特卡洛采样来近似
7.由于期望有个log符号,采样需要很多样本,且方差很大
8.通过重参数化技巧解决方差大的问题,主要思想是把z的随机成分去掉,转移到一个确定性分布p(ε)
变分推断,英文Variational Inference,简称VI,是一种近似推断的方法,属于确定性近似。它跟EM算法都是求解隐变量后验分布的算法,在EM算法中,隐变量z和未知参数θ是分开的,在变分推断里面,它们合并在一起,依然用z代替。
因此,其推导过程与EM算法差不多,建议读者先熟悉小编在文章EM算法的推导过程。
公式推导
展开对数似然函数:
两边同时乘以q(z),
做积分与恒等转换:
红色部分就是我们在EM算法提到的ELBO,这里我们称为变分,记做L(q);蓝色部分为KL散度,恒大于等于0.
在EM算法中我们介绍过,E步本质是求隐变量后验分布p(z|x),如果没办法得到该后验,一种思想是使得q(z)去逼近p(z|x):
这样就能让KL散度为0,那么求解变分的最大值,就是似然对数的最大值。因此,优化问题变为:
下面我们就求解q(z).
第一步我们利用了统计物理学的平均场理论的思想,假设q(z)可以分解为M个独立的qi:
求解的想法是先固定其他M-1个分量,只求解其中一个qj,重复M次,就得到所有的q(z).
展开L(q):
代入qi,对于红色部分:
对于蓝色部分:
注:倒数第二个等号化简过程如下
合并起来,得到:
这样,变分推断问题转化为一个最优问题:
最大L(q)的解是满足:
这个解是基于平均场理论假设的结果.
公式求解
我们基于上一节的结果求解其参数,展开最优解公式:
利用坐标上升迭代法可以求解各个参数:
每轮更新上面1-m个参数,直至L(q)收敛。
这个基于平均场假设的模型有很大的局限性,主要体现在:
-
假设太强,Z非常复杂的情况下,假设不适用
-
期望中的积分,可能无法计算
SGVI
从Z到 X的过程叫做生成过程或译码,反过来叫推断过程或编码过程,基于平均场的变分推断可以导出坐标上升的算法,但是这个假设在一些情况下假设太强,同时积分也不一定能算。
优化方法除了坐标上升,还有梯度上升的方式,我们希望通过梯度上升来得到变分推断的另一种算法。这里采取随机梯度法,结合变分推断,导出来的算法叫随机梯度变分推断,英文是Stochastic Gradient Variational Inference,简写SGVI.
为了方便推导,我们假定q(z)是有关Φ参数的概率分布:
那么,变分L(q)改写成:
最优化问题是:
我们直接对它求梯度:
蓝色部分等于0是因为:
继续化简L(Φ)梯度:
这样,变分关于q(z)的梯度通过期望相联系。这个期望可以通过蒙特卡洛采样来近似,从⽽得到梯度,然后利⽤梯度上升的⽅法来得到参数
但是由于求和符号中存在⼀个对数项,于是直接采样的方差很大(high variance),需要采样的样本⾮常多。
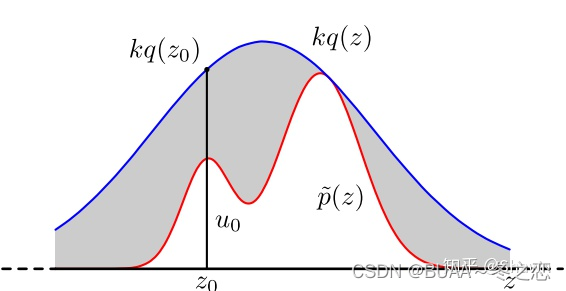
为了解决⽅差太⼤的问题,我们采⽤重参数化技巧( Reparameterization Trick) .
考虑z~Φ之间的随机关系,我们把z的随机成分去掉,转移到一个确定性分布p(ε):
于是有:
代入变分L(Φ)公式:
最后,通过蒙特卡洛采样近似:
得到梯度更新值: