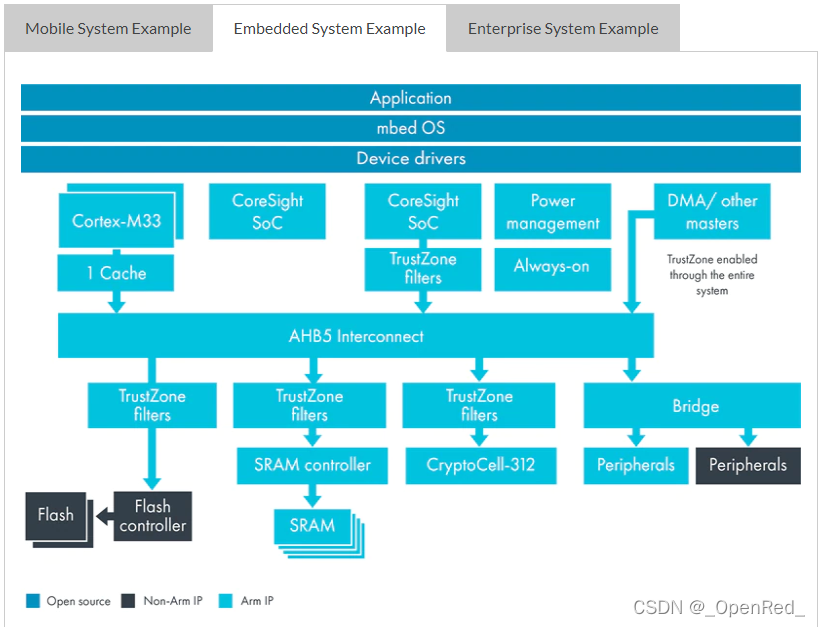
本文介绍如何编写一个config文件,config.pbtxt文件中包含哪些可以配置的参数,这些参数又会对triton server产生什么影响。
必须指定的模型参数
- platform/backend:模型要在什么backend上面运行,可以用两种参数指定,一个是platform,一个是backend,对于某些模型,两个参数二选一即可,某些模型必须从中选一个指定,具体的规则如下:

图中TensorRT,onnx RT,PyTorch三种模型可以platform或者backend随便指定一个即可;对于Tensorflow,platform平台是必须指定的,backend平台是可选的;对于OpenVINO、python、DALI,backend是必须指定的 - max batch size 模型执行推理最大的batch是多少,这个参数主要是限制推理中模型参数不会超过模型显存,或者gpu内存,保证推理服务不会因为爆显存而挂掉
- input and output:指定输入输出名称
特别的,当模型是由TensorRT、Tensorflow、onnx生成的,且设置strict-model-config=false时,可以不需要config.pbtxt文件。
配置文件示例说明

- 配置1:
指定platform:
max batch size = 8:注意,若max batch size大于0,默认网络的batch大小可以是动态调整的,在网络输入维度dims参数可以不指定batch大小。
输入输出参数:包括名称、数据类型、维度 - 配置2:
指定platform:
max batch size = 0:此时,这个维度不支持可变长度,网络输入维度dims参数必须显式指定每个维度的大小,这里也可以设置batch大于0,比如维度【2,3,224,224】。
输入输出参数:包括名称、数据类型、维度 - 配置3:
指定platform:pytorch_libtorch
max batch size = 8:这个维度支持可变长度。
输入输出参数:
包括名称、数据类型、**格式、**维度。
对于pytorch_libtorch的模型,不包含输入输出的具体信息,因此,对于输入输出名称,有特殊的格式:字符串+两个下划线+数字,必须是这种结构。
若模型支持可变维度,则可变的维度可以设置为-1。 - 配置4:
reshape应用:
max batch size = 0:维度不包含batch维度,但是若模型要求包含这个维度,就可以使用reshape,将其reshape成[1,3,224,224],就可以满足应用需求
可选的配置参数
除上述参数,配置文件中还可以设置其他参数。
1. version_policy:配置版本信息
model repository可以包含多个多个版本模型,因此,在配置文件中可以设定具体执行哪个模型。

如上图所示,version_policy可以有3种配置
All:表示model repository中所有模型都可以加载,若使用该配置,执行的时候model repository中所有模型都会加载。
Latest:只执行最新的版本,最新指版本数字最大的,若使用该配置,则只选择最新的模型加载。
Specific:执行指定版本。若使用该配置,需设定指定的版本号,加载时只加载指定的相应版本。
2. Instance_group:它对应triton一个重要的feature:concurrent model inference,就是在一个Triton server上对同一个模型开启多个execution instance,可以并行的在GPU上执行,从而提高GPU的利用率,增加模型的吞吐。

Instance_group:表示运行在同一设备上的一组model instance。
count:指定每个设备上的instance数量
kind:定义设备类型,可以是cpu,也可以是GPU
gpus:定义使用哪个GPU,若不指定,默认会在每一个GPU上都运行。
Instance_group中可以指定多个group 运行在多个设备上。
3. scheduling and batching:定义Triton应使用哪种调度测量来调度客户端的请求。调度策略也是Triton一个非常重要的feature,它也可以提高GPU的利用率,增加模型的吞吐。因为如果推理的batchsize越大,GPU的利用率越高。
Triton有多种调度器:
-
default scheduler:默认scheduler,若不对这个参数做设置,则执行默认测量。不做batching,即模型送进来的batch是多少,则推理的batch就设定多少。

-
dynamic batcher:它可以在服务端将多个batchsize比较小的request组合成一个batchsize大的input tensor,从而提升GPU利用率,增加吞吐。它只对stateless 模型有效,对于streaming视频音频流处理模型不适用(需要使用sequence模型)。它有两个关键参数需要指定:
1)preferred_batch_size:期望达到的batchsize大小,可以是一个数,也可以是一个数组,通常会在里面设置多个值。
2)max_queue_delay_microseconds:单位是微秒,打batch的时间限制,超过该时间会停止batch,超过该时间会将以打包的batch送走。
3)其他高级设置:preserve ordering:确保输出的顺序和请求送进来的顺序一致。
priority_level:可以设置优先级,
queue policy:设置排队的策略,比如时限超时则停止推理

-
sequence batcher:处理sequence请求。能够保证同一个streaming序列的请求送到同一个model instance执行,从而能够保证model instance的状态。

-
ensemble scheduler:可以组合不同的模块,形成一个pipeline
4. optimization policy
Triton中提供两种优化方式:分别针对onnx模型和tensorflow模型,可以使用下图的设置开启tensorrt加速。具体可以设置名称、tensorrt加速的精度等。

5. model warmup
有些模型在刚初始化的短时间内,执行推理时性能是不太稳定的,可能会比较慢,所以需要一个热身的过程使得推理趋于稳定。
Triton通过指定model warmup字段去定义热身过程。字段内可以指定batchsize大小、请求是如何生成的,比如随机数生成,还有数据维度、数据类型等。这样,Triton刚刚加载某个模型时候,会向模型发送热身请求。model在warmup过程中,Triton无法对外提供服务,导致模型加载较慢,完成后,client端才能使用模型推理