深入理解 Java 中的 hashCode
- 一、hashCode 方法
- 二、为什么重写 equals 方法的时候必须重写 hashCode 方法?
一、hashCode 方法
Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,Object 类中就包含了 hashCode() 方法:
// Java 1.8
public native int hashCode();// Java 9
@HotSpotIntrinsicCandidate
public native int hashCode();
意味着所有的类都会有一个 hashCode() 方法,该方法会返回一个 int 类型的值。由于 hashCode() 方法是一个本地方法(native 关键字修饰的方法,用 C/C++ 语言实现,由 Java 调用),意味着 Object 类中并没有给出具体的实现。
在 Java 9 中,hashCode() 方法被 @HotSpotIntrinsicCandidate 注解修饰,说明它在 HotSpot 虚拟机中有一套高效的实现,是基于 CPU 指令的。
那就有一个问题:为什么 Object 类需要一个 hashCode() 方法呢?
在 Java 中,hashCode() 方法的主要作用就是为了配合哈希表使用的。
哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。其中用到的算法叫做哈希,就是把任意长度的输入变换成固定长度的输出,该输出就是哈希值。像 Java 中的 HashSet、Hashtable、HashMap 都是给予哈希表的具体实现。其中,HashMap 就是最典型的代表。
我们可以想象一下,如果没有哈希表,但是又需要一个这样的数据结构,它里面存放的数据是不允许重复的,该怎么办呢?
显然,我们想到的方法就是使用 equals() 方法进行逐个比较,但是如果数据量异常大,采用 equals() 方法进行逐个对比的效率一定非常非常低,所以,最好的解决方案就是哈希表。
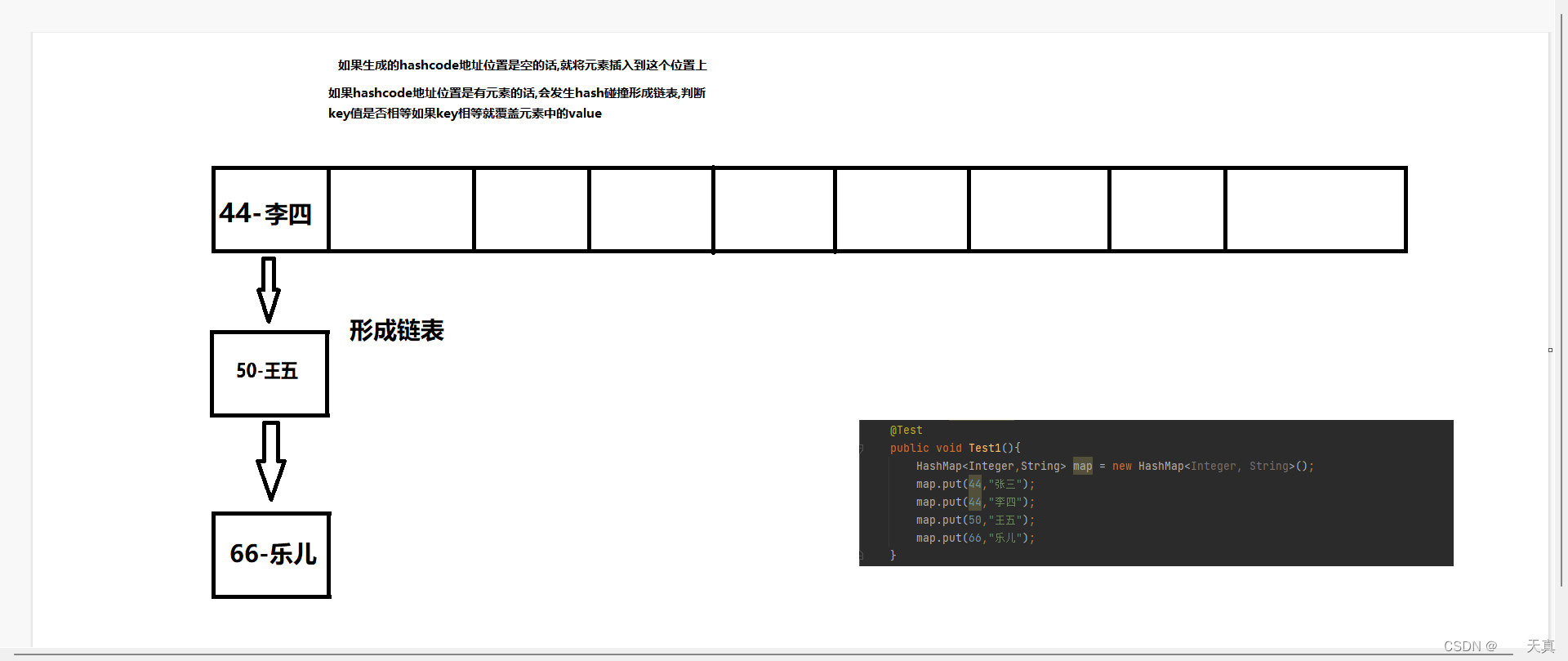
☆☆☆ 就拿 HashMap 来说,当我们要在它里面添加对象时,先调用这个对象的 hashCode() 方法得到对应的哈希值,然后将哈希值和对象一起放到 HashMap 中。当我们要再添加一个新的对象时会执行这么几个步骤:
- 获取对象的哈希值;
- 与之前已经存在的哈希值进行比较,如果不相等,直接存进去;
- 如果有相等的,再调用 equals() 方法进行对象之间的比较。如果相等,不存储;如果不相等,说明哈希冲突,增加一个链表存放新的对象(如果链表的长度大于 8,转为红黑树处理)。
这么一套流程下来,调用 equals() 方法的频率就大大降低了。也就是说,只要哈希算法足够的高效,把发生哈希冲突的频率降到最低,哈希表的效率就特别的高。
先来看一下 HashMap 的哈希算法:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
它会先调用对象的 hashCode() 方法,然后对该值进行右移运算,然后再进行异或运算。
通常来说,String 会用来作为 HashMap 的键进行哈希运算,所以,再来看一下 String 的 hashCode() 方法:
public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {hash = h = isLatin1() ? StringLatin1.hashCode(value): StringUTF16.hashCode(value);}return h;
}public static int hashCode(byte[] value) {int h = 0;int length = value.length >> 1;for (int i = 0; i < length; i++) {h = 31 * h + getChar(value, i);}return h;
}
虽然不是特别清除具体里面做了什么操作,但是可以看出来,经过这么一系列复杂的运算,再加上这样的设计,哈希冲突的概率可能已经降到了最低了。
但是,从理论上来讲,两个不同的对象通过 hashCode() 方法计算后的值可能相同。所以,不能使用 hashCode() 方法来判断两个对象是否相等,必须要通过 equals() 方法来判断。
也就是说:
- 如果两个对象调用 equals() 方法得到的结果为 true,调用 hashCode() 方法得到的结果必定相等;
- 如果两个对象调用 hashCode() 方法得到的结果不相等,调用 equals() 方法得到的结果必定不相等。
- 如果两个对象调用 equals() 方法得到的结果为 false,调用 hashCode() 方法得到的结果可能相等;
- 如果两个对象调用 hashCode() 方法得到的结果相等,调用 equals() 方法得到的结果不一定相等。
举个例子!
不重写 equals() 方法:
/*** 员工类** @author qiaohaojie* @date 2023/3/15 22:03*/
public class Employee {private int age;private String name;public Employee(Integer age, String name) {this.age = age;this.name = name;}@Overridepublic String toString() {return super.toString().substring(18) + "{" +"age=" + age +", name='" + name + '\'' +'}';}
}
/*** Java中的hashCode方法** @author qiaohaojie* @date 2023/3/14 21:42*/
public class HashCodeTest {public static void main(String[] args) {Employee employee1 = new Employee(23,"青花椒");Employee employee2 = new Employee(23,"青花椒");System.out.println(employee1); // Employee@5a07e868{age=23, name='青花椒'}System.out.println(employee2); // Employee@76ed5528{age=23, name='青花椒'}Map<Employee, Integer> map = new HashMap<>();map.put(employee1, 99);System.out.println(map.get(employee2)); // null}
}
重写 equals() 方法:
/*** 员工类** @author qiaohaojie* @date 2023/3/15 22:03*/
public class Employee {private int age;private String name;public Employee(Integer age, String name) {this.age = age;this.name = name;}@Overridepublic String toString() {return super.toString().substring(18) + "{" +"age=" + age +", name='" + name + '\'' +'}';}@Overridepublic boolean equals(Object o) {Employee employee = (Employee) o;return age == employee.age &&Objects.equals(name, employee.name);}
}
/*** Java中的hashCode方法** @author qiaohaojie* @date 2023/3/14 21:42*/
public class HashCodeTest {public static void main(String[] args) {Employee employee1 = new Employee(23,"青花椒");Employee employee2 = new Employee(23,"青花椒");System.out.println(employee1); // Employee@5a07e868{age=23, name='青花椒'}System.out.println(employee2); // Employee@76ed5528{age=23, name='青花椒'}Map<Employee, Integer> map = new HashMap<>();map.put(employee1, 99);System.out.println(map.get(employee2)); // null}
}
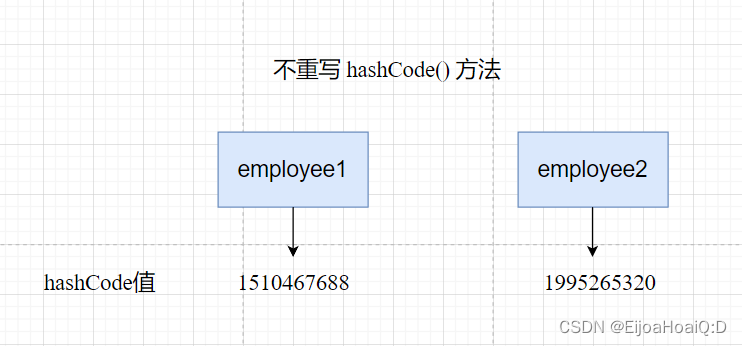
显然,两个的结果是相同的(都未null)。原因就在于重写 equals() 方法的时候没有重写 hashCode() 方法,而在默认情况下,hashCode() 方法是一个本地方法,会返回对象的存储地址,而 put() 中的 employee1 和 map.get(employee2) 中的对象是两个对象,所以它们的存储地址一定是不同的。
HashMap 的 get() 方法会调用 hash(key.hashCode()) 计算对象的哈希值,虽然两个不同的 hashCode() 结果经过 hash() 方法计算后有可能得到相同的结果,但是这种概率是非常非常小的,所以就导致了 map.get(employee2) 无法得到预期值 99。
这个问题怎么解决呢?重写 hashCode() 方法:
@Override
public int hashCode() {return Objects.hash(age, name);
}
重写 hashCode() 方法后,测试结果:
/*** Java中的hashCode方法** @author qiaohaojie* @date 2023/3/14 21:42*/
public class HashCodeTest {public static void main(String[] args) {Employee employee1 = new Employee(23,"青花椒");Employee employee2 = new Employee(23,"青花椒");System.out.println(employee1); // Employee@2484ddd{age=23, name='青花椒'}System.out.println(employee2); // Employee@2484ddd{age=23, name='青花椒'}Map<Employee, Integer> map = new HashMap<>();map.put(employee1, 99);System.out.println(map.get(employee2)); // 99}
}
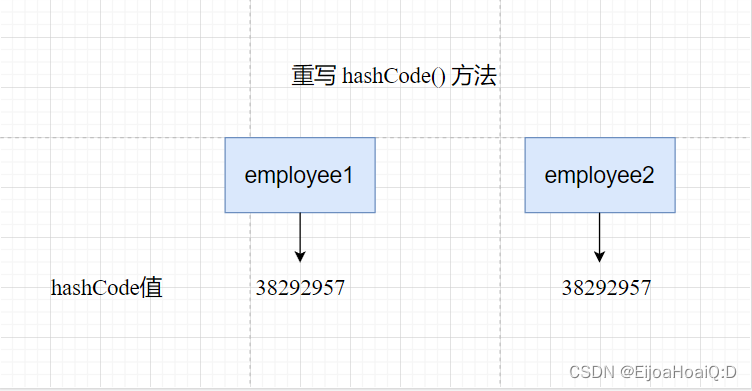
这样就得到了预期的结果 99。
Objects 类的 hash() 方法可以针对不同数量的参数生成新的 hashCode() 值:
// Objects 类的第127~129行
public static int hash(Object... values) {return Arrays.hashCode(values);
}// Arrays 类的第4139~4149行
public static int hashCode(Object a[]) {if (a == null)return 0;int result = 1;for (Object element : a)result = 31 * result + (element == null ? 0 : element.hashCode());return result;
}
其中归纳出的数学公式如下(n为字符串长度):
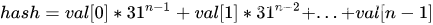
注意(我也不太懂,看人家是这样说的):31 是个奇质数,不大也不小,一般质数都非常适合哈希计算,偶数相当于位移运算,容易溢出,造成数据信息丢失。
这就意味着,当 age 和 name 相同的情况下,会得到相同的哈希值。所以,map.get(employee2) 就会返回预期结果 99。
《Java 变成思想》中有这么一段话用来描述 hashCode() 方法:
设计 hashCode() 时最重要的因素就是:无论何时,对同一个对象调用 hashCode() 都应该生成同样的值。如果在将一个对象用 put() 方法添加进 HashMap 时产生一个 hashCode() 值,而用 get() 方法取出时却产生了另外一个 hashCode() 值,那么就无法重新取得该对象了。所以,如果你的 hashCode() 方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode() 就会生成一个不同的哈希值,相当于产生了一个不同的键。
也就是说,如果在重写 hashCode() 和 equals() 方法时,对象中某个字段容易发生变化,那么最好舍弃这些字段,以免产生不可预期的结果。
二、为什么重写 equals 方法的时候必须重写 hashCode 方法?
上面有说过,Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,Object 类中就包含了这么两个方法:
public native int hashCode();public boolean equals(Object obj) {return (this == obj);
}
- hashCode() 方法:是一个本地方法,用来返回对象的哈希值(一个整数)。在 Java 程序执行期间,对同一个对象多次调用该方法返回相同的哈希值。
- equals() 方法:对于任务非空引用 x 和 y,当且仅当 x 和 y 引用的是同一个对象时,equals() 方法才返回 true。
从这些解释来看,两个方法之间好像没有任何关联,但是这两个方法的文档中海油这么两条信息:
- 第一,如果两个对象调用 equals() 方法返回的结果为 true,那么两个对象调用 hashCode() 方法返回的结果也必然相同。
- 第二,每当重写 equals() 方法时,hashCode() 方法也需要重写,以便维护上一条规约。
这是为什么呢?
hashCode() 方法的作用就是用来获取哈希值,而该哈希值的作用是用来确定对象在哈希表中的索引位置。
哈希表的典型代表就是 HashMap,它存储的是键值对,能通过 get() 方法根据键快读地检索出对应的值:
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}
这是 HashMap 的 get 方法,通过键来获取值的方法。它会调用 getNode() 方法:
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
通常情况下(没有发生哈希冲突)下,first = tab[(n - 1) & hash] 就是键对应的值。按照时间复杂度来说的话,可表示为 O(1)。
如果发生哈希冲突,也就是 if ((e = first.next) != null) {} 子句中,可以看到如果节点不是红黑树的时候,会通过 do-while 循环语句判断是否是 equals() 返回对应值。按照时间复杂度来说的话,可以表示为 O(n)。
HashMap 是通过拉链法来解决哈希冲突的,也就是如果发生哈希冲突,同一个键的坑位会放好多个值,超过 8 个值后改为红黑树,为了提高查询的效率。
显然,从时间复杂度上来看的话 O(n) 比 O(1) 的性能要差,这也正是哈希表的价值所在。
可以想一下,如果没有哈希表,但是又需要一个这样的数据结构,它里面存放的数据是不允许重复的,该怎么办呢?难道真的要使用 equals() 方法逐个进行比较吗?如果数据量特别特别的大时,性能就会很差,所以最好的解决方案还是 HashMap。
HashMap 本质上是通过数组实现的,当我们要从 HashMap 中获取某个值时,实际上时要获取数组中某个位置的元素,而位置是通过键来确定的,put() 方法存放时是存的键值对:
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}
在 put() 方法中,会将键值对放入到数组中,它会调用 putVal() 方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}
通常情况下,p = tab[i = (n - 1) & hash])就是键对应的值。而数组的索引 (n - 1) & hash 正是基于 hashCode() 方法计算得到的:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
那到底是为什么重写 equals() 方法的时候要重写 hashCode() 方法呢?
接着上文中的测试类:
/*** Java中的hashCode方法** @author qiaohaojie* @date 2023/3/14 21:42*/
public class HashCodeTest {public static void main(String[] args) {Employee employee1 = new Employee(23,"青花椒");Employee employee2 = new Employee(23,"青花椒");System.out.println(employee1); // Employee@2484ddd{age=23, name='青花椒'}System.out.println(employee2); // Employee@2484ddd{age=23, name='青花椒'}Map<Employee, Integer> map = new HashMap<>();map.put(employee1, 99);System.out.println(map.get(employee2)); // null 不重写hashCode()方法System.out.println(map.get(employee2)); // 99 重写hashCode()方法}
}
没有重写 hashCode() 方法时,两个对象的 hashCode 值:
重写 hashCode() 方法后,两个对象的 hashCode 值:
重写 hashCode() 方法时可以直接调用 Objects 类的 hash() 方法:
@Override
public int hashCode() {return Objects.hash(age, name);
}
Objects 类的 hash() 方法内部调用的是 Arrays 类的 hashCode() 方法:
public static int hash(Object... values) {return Arrays.hashCode(values);
}
Arrays 类的 hashCode() 方法是这样实现的:
public static int hashCode(Object a[]) {if (a == null)return 0;int result = 1;for (Object element : a)result = 31 * result + (element == null ? 0 : element.hashCode());return result;
}
第一次循环:
result = 31 * 1 + Integer.valueOf(23).hashCode() = 31 + 23 = 54;
第二次循环:
result = 31 * (31 * 1 + Integer.valueOf(23).hashCode()) + String(“青花椒”).hashCode() = 31 * 54 + 39291283 = 38292957;
所以,每次重写 equals() 方法时,hashCode() 方法也需要重写,就是为了保证:如果两个对象调用 equals() 方法返回的结果为 true,那么两个对象调用 hashCode() 方法返回的结果也必然相同。













![[carla入门教程]-5 使用ROS与carla通信](https://img-blog.csdnimg.cn/7f16d89b49704a998518792966cbe775.png)


