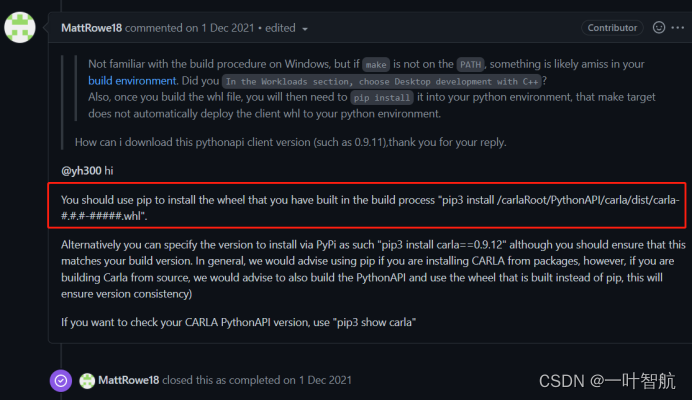
本人当初刚接触java的时候一说到hash算法或者hashCode也是蛋蛋疼,两只都疼

后来花了整整一天时间来研究hash,搞懂后发现其实也不难理解,时隔一年突然想起来,写篇博客记录下;
以前我莫得选择,现在我想搞懂hash,搞懂算法,做大做强,再创辉煌!
本文会围绕以下几个点来讲:
什么是hashCode?
hashCode和equals的关系
剖析hashMap的hash算法(重点)
为什么会有hashCode
先抛一个结论
hashCode的设计初衷是提高哈希容器的性能
抛开hashCode,现在让你对比两个对象是否相等,你会怎么做?
thisObj == thatObj
thisObj.equals(thatObj)
我想不出第三种了,而且这两种其实没啥大的区别,object的equals()方法底层也是==,jdk1.8 Object类的第148行;
public boolean equals(Object obj) {return (this == obj);}
为什么有了equals还要有hashCode?上面说了,hashCode的设计初衷是提高哈希容器的性能,equals的效率是没有hashCode高的,不信的可以自己去试一下;
像我们常用的HashMap、HashTable等,某些场景理论上讲是可以不要hashCode的,但是会牺牲很多性能,这肯定不是我们想看到的;
什么是hashCode
知道hashCode存在的意义后,我们来研究下hashCode,看下长什么样
对象调用hashCode方法后,会返回一串int类型的数字码
Car car = new Car();
log.info("对象的hashcode:{}", car.hashCode());
log.info("1433223的hashcode:{}", "1433223".hashCode());
log.info("郭德纲的hashcode:{}", "郭德纲".hashCode());
log.info("小郭德纲的hashcode:{}", "小郭德纲".hashCode());
log.info("彭于晏的hashcode:{}", "彭于晏".hashCode());
log.info("唱跳rap篮球的hashcode:{}", "唱跳rap篮球".hashCode());
运行结果
对象的hashcode:357642
1433223的hashcode:2075391824
郭德纲的hashcode:36446088
小郭德纲的hashcode:738530585
彭于晏的hashcode:24125870
唱跳rap篮球的hashcode:-767899628 ##因为返回值是int类型,有负数很正常
可以看出,对象的hashcode值跟对象本身的值没啥联系,比如郭德纲和小郭德纲,虽然只差一个字,它们的hashCode值没半毛钱关系~
hashCode和equals的关系
java规定:
如果两个对象的hashCode()相等,那么他们的equals()不一定相等。
如果两个对象的equals()相等,那么他们的hashCode()必定相等。
还有一点,重写equals()方法时候一定要重写hashCode()方法,不要问为什么,无脑写就行了,会省很多事
hash算法
前面都是铺垫,这才是今天的主题
我们以HashMap的hash算法来看,个人认为这是很值得搞懂的hash算法,设计超级超级巧妙
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
这是hashMap的hash算法,我们一步一步来看
(h = key.hashCode()) ^ (h >>> 16)
hashCode就hashCode嘛,为啥还要>>>16,这个 ^ 又是啥,不着急一个一个来说
hashMap我们知道默认初始容量是16,也就是有16个桶,那hashmap是通过什么来计算出put对象的时候该放到哪个桶呢
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
上面是hashmap的getNode方法,对hashmap源码有兴趣的同学自行研究,我们今天主要看这一句:(n - 1) & hash
也就是说hashmap是通过数组长度-1&key的hash值来计算出数组下标的,这里的hash值就是上面(h = key.hashCode()) ^ (h >>> 16)计算出来的值
不要慌不要慌不要慌,看不懂没关系,我们现在总结下目前的疑问
为什么数组长度要 - 1,直接数组长度&key.hashCode不行吗
为什么要length-1 & key.hashCode计算下标,而不是用key.hashCode % length
为什么要^运算
为什么要>>>16
先说结论
数组长度-1、^运算、>>>16,这三个操作都是为了让key在hashmap的桶中尽可能分散
用&而不用%是为了提高计算性能
我们先看下如果数组长度不-1和不进行>>>16运算造成的结果,知道了结果我们后面才来说为什么,这样子更好理解
log.info("数组长度不-1:{}", 16 & "郭德纲".hashCode());
log.info("数组长度不-1:{}", 16 & "彭于晏".hashCode());
log.info("数组长度不-1:{}", 16 & "李小龙".hashCode());
log.info("数组长度不-1:{}", 16 & "蔡徐鸡".hashCode());
log.info("数组长度不-1:{}", 16 & "唱跳rap篮球鸡叫".hashCode());log.info("数组长度-1但是不进行异或和>>>16运算:{}", 15 & "郭德纲".hashCode());
log.info("数组长度-1但是不进行异或和>>>16运算:{}", 15 & "彭于晏".hashCode());
log.info("数组长度-1但是不进行异或和>>>16运算:{}", 15 & "李小龙".hashCode());
log.info("数组长度-1但是不进行异或和>>>16运算:{}", 15 & "蔡徐鸡".hashCode());
log.info("数组长度-1但是不进行异或和>>>16运算:{}", 15 & "唱跳rap篮球鸡叫".hashCode());log.info("数组长度-1并且进行异或和>>>16运算:{}", 15 & ("郭德纲".hashCode()^("郭德纲".hashCode()>>>16)));
log.info("数组长度-1并且进行异或和>>>16运算:{}", 15 & ("彭于晏".hashCode()^("彭于晏".hashCode()>>>16)));
log.info("数组长度-1并且进行异或和>>>16运算:{}", 15 & ("李小龙".hashCode()^("李小龙".hashCode()>>>16)));
log.info("数组长度-1并且进行异或和>>>16运算:{}", 15 & ("蔡徐鸡".hashCode()^("蔡徐鸡".hashCode()>>>16)));
log.info("数组长度-1并且进行异或和>>>16运算:{}", 15 & ("唱跳rap篮球鸡叫".hashCode()^("唱跳rap篮球鸡叫".hashCode()>>>16)));
数组长度不-1:0
数组长度不-1:0
数组长度不-1:16
数组长度不-1:16
数组长度不-1:16
数组长度-1但是不进行异或和>>>16运算:8
数组长度-1但是不进行异或和>>>16运算:14
数组长度-1但是不进行异或和>>>16运算:8
数组长度-1但是不进行异或和>>>16运算:2
数组长度-1但是不进行异或和>>>16运算:14
数组长度-1并且进行异或和>>>16运算:4
数组长度-1并且进行异或和>>>16运算:14
数组长度-1并且进行异或和>>>16运算:7
数组长度-1并且进行异或和>>>16运算:13
数组长度-1并且进行异或和>>>16运算:2
一下就看出区别了哇,第一组返回的下标就只有0和16,第二组也只有2、8、14,第三组的下标就很分散,这才是我们想要的
这结合hashMap来看,前两组造成的影响就是key几乎全部怼到同一个桶里,及其不分散,用行话讲就是有太多的hash冲突,这对hashMap的性能有很大影响,hash冲突造成的链表红黑树转换那些具体的原因这里就不展开说了
而且!!
而且!!
而且!!
如果数组长度不 - 1,刚上面也看到了,会返回16这个下标,数组总共长度才16,下标最大才15,16越界了呀
原理
知道了结果,现在说说其中的玄学
1、为什么数组长度要 - 1,直接数组长度&key.hashCode不行吗?
我们先不考虑数组下标越界的问题,hashMap默认长度是16,看看16的二进制码是多少
log.info("16的二进制码:{}",Integer.toBinaryString(16));
//16的二进制码:10000,
再看看key.hashCode()的二进制码是多少,以郭德纲为例
log.info("key的二进制码:{}",Integer.toBinaryString("郭德纲".hashCode()));
//key的二进制码:10001011000001111110001000
length & key.hashCode() => 10000 & 10001011000001111110001000
位数不够,高位补0,即0000 0000 0000 0000 0000 0001 0000 &
0010 0010 1100 0001 1111 1000 1000&运算规则是第一个操作数的的第n位于第二个操作数的第n位都为1才为1,否则为0
所以结果为0000 0000 0000 0000 0000 0000 0000,即 0

冷静分析,问题就出在16的二进制码上,它码是10000,只有遇到hash值二进制码倒数第五位为1的key他们&运算的结果才不等于0,这句话好好理解下,看不懂就别强制看,去摸会儿鱼再回来看
再来看16-1的二进制码,它码是1111,同样用郭德纲这个key来举例
(length-1) & key.hashCode() => 1111 & 10001011000001111110001000
位数不够,高位补0,即0000 0000 0000 0000 0000 0000 1111 &
0010 0010 1100 0001 1111 1000 1000&运算规则是第一个操作数的的第n位于第二个操作数的第n位都为1才为1,否则为0
所以结果为0000 0000 0000 0000 0000 0000 1000,即 8
如果还看不出这其中的玄机,你就多搞几个key来试试,总之记住,限制它们&运算的结果就会有很多种可能性了,不再受到hash值二进制码倒数第五位为1才能为1的限制
2、为什么要length-1&key.hashCode计算下标,而不是用key.hashCode%length?
这个其实衍生出三个知识点
1、其实(length-1)&key.hashCode计算出来的值和key.hashCode%length是一样的
log.info("(length-1)&key.hashCode:{}",15&"郭德纲".hashCode());
log.info("key.hashCode%length:{}","郭德纲".hashCode()%16);// (length-1)&key.hashCode:8
// key.hashCode%length:8
那你可能更蒙逼了,都一样的为啥不用%,这就要说到第二个知识点
2、只有当length为2的n次方时,(length-1)&key.hashCode才等于key.hashCode%length,比如当length为15时
log.info("(length-1)&key的hash值:{}",14&"郭德纲".hashCode());
log.info("key的hash值%length:{}","郭德纲".hashCode()%15);// (length-1)&key.hashCode:8
// key.hashCode%length:3
可能又有小朋友会思考,我不管那我就想用%运算,要用魔法打败魔法,请看第三点
3、用&而不用%是为了提高计算性能,对于处理器来讲,&运算的效率是高于%运算的,就这么简单,除此之外,除法的效率也没&高
3、为什么要进行^运算,|运算、&运算不行吗?
这是异或运算符,第一个操作数的的第n位于第二个操作数的第n位相反才为1,否则为0
我们多算几个key的值出来对比
//不进行异或运算返回的数组下标
log.info("郭德纲:{}", Integer.toBinaryString("郭德纲".hashCode()));
log.info("彭于晏:{}", Integer.toBinaryString("彭于晏".hashCode()));
log.info("李小龙:{}", Integer.toBinaryString("李小龙".hashCode()));
log.info("蔡徐鸡:{}", Integer.toBinaryString("蔡徐鸡".hashCode()));
log.info("唱跳rap篮球鸡叫:{}", Integer.toBinaryString("唱跳rap篮球鸡叫".hashCode()));00001000101100000111111000 1000
00000101110000001000011010 1110
00000110001111100100010011 1000
00000111111111111100010111 0010
10111010111100100011001111 1110进行&运算,看下它们返回的数组下标,length为16的话,只看后四位即可
8
14
8
2
14//进行异或运算返回的数组下标
log.info("郭德纲:{}", Integer.toBinaryString("郭德纲".hashCode()^("郭德纲".hashCode()>>>16)));
log.info("彭于晏:{}", Integer.toBinaryString("彭于晏".hashCode()^("彭于晏".hashCode()>>>16)));
log.info("李小龙:{}", Integer.toBinaryString("李小龙".hashCode()^("李小龙".hashCode()>>>16)));
log.info("蔡徐鸡:{}", Integer.toBinaryString("蔡徐鸡".hashCode()^("蔡徐鸡".hashCode()>>>16)));
log.info("唱跳rap篮球鸡叫:{}", Integer.toBinaryString("唱跳rap篮球鸡叫".hashCode()^("唱跳rap篮球鸡叫".hashCode()>>>16)));0000001000101100000111011010 0100
0000000101110000001000001101 1110
0000000110001111100100001011 0111
0000000111111111111100001000 1101
0010111010111100101000100100 0010进行&运算,看下它们返回的数组下标,length为16的话,只看后四位即可
4
14
7
13
2很明显,做了^运算的数组下标更分散
如果还不死心,再来看几个例子
看下 ^、|、&这三个位运算的结果就知道了
log.info("^ 运算:{}", 15 & ("郭德纲".hashCode() ^ ("郭德纲".hashCode() >>> 16)));
log.info("^ 运算:{}", 15 & ("彭于晏".hashCode() ^ ("彭于晏".hashCode() >>> 16)));
log.info("^ 运算:{}", 15 & ("李小龙".hashCode() ^ ("李小龙".hashCode() >>> 16)));
log.info("^ 运算:{}", 15 & ("蔡徐鸡".hashCode() ^ ("蔡徐鸡".hashCode() >>> 16)));
//^ 运算:4
//^ 运算:14
//^ 运算:7
//^ 运算:13 log.info("| 运算:{}", 15 & ("郭德纲".hashCode() | ("郭德纲".hashCode() >>> 16)));
log.info("| 运算:{}", 15 & ("彭于晏".hashCode() | ("彭于晏".hashCode() >>> 16)));
log.info("| 运算:{}", 15 & ("李小龙".hashCode() | ("李小龙".hashCode() >>> 16)));
log.info("| 运算:{}", 15 & ("蔡徐鸡".hashCode() | ("蔡徐鸡".hashCode() >>> 16)));
//| 运算:12
//| 运算:14
//| 运算:15
//| 运算:15 log.info("& 运算:{}", 15 & ("郭德纲".hashCode() & ("郭德纲".hashCode() >>> 16)));
log.info("& 运算:{}", 15 & ("彭于晏".hashCode() & ("彭于晏".hashCode() >>> 16)));
log.info("& 运算:{}", 15 & ("李小龙".hashCode() & ("李小龙".hashCode() >>> 16)));
log.info("& 运算:{}", 15 & ("蔡徐鸡".hashCode() & ("蔡徐鸡".hashCode() >>> 16)));
//& 运算:8
//& 运算:0
//& 运算:8
//& 运算:2
现在看出来了吧,^ 运算的下标分散,具体原理在下文会说
4、为什么要>>>16,>>>15不行吗?
这是无符号右移16位,位数不够,高位补0
现在来说进行 ^ 运算中的玄学,其实>>>16和 ^ 运算是相辅相成的关系,这一套操作是为了保留hash值高16位和低16位的特征,因为数组长度(按默认的16来算)减1后的二进制码低16位永远是1111,我们肯定要尽可能的让1111和hash值产生联系,但是很显然,如果只是1111&hash值的话,1111只会与hash值的低四位产生联系,也就是说这种算法出来的值只保留了hash值低四位的特征,前面还有28位的特征全部丢失了;
因为&运算是都为1才为1,1111我们肯定是改变不了的,只有从hash值入手,所以hashMap作者采用了 key.hashCode() ^ (key.hashCode() >>> 16) 这个巧妙的扰动算法,key的hash值经过无符号右移16位,再与key原来的hash值进行 ^ 运算,就能很好的保留hash值的所有特征,这种离散效果才是我们最想要的。
上面这两段话就是理解>>>16和 ^ 运算的精髓所在,如果没看懂,建议你休息一会儿再回来看,总之记住,目的都是为了让数组下标更分散
再补充一点点,其实并不是非得右移16位,如下面得测试,右移8位右移12位都能起到很好的扰动效果,但是hash值的二进制码是32位,所以最理想的肯定是折半咯,雨露均沾
log.info(">>>16运算:{}", 15 & ("郭德纲".hashCode() ^ ("郭德纲".hashCode() >>> 16)));
log.info(">>>16运算:{}", 15 & ("彭于晏".hashCode() ^ ("彭于晏".hashCode() >>> 16)));
log.info(">>>16运算:{}", 15 & ("李小龙".hashCode() ^ ("李小龙".hashCode() >>> 16)));
log.info(">>>16运算:{}", 15 & ("蔡徐鸡".hashCode() ^ ("蔡徐鸡".hashCode() >>> 16)));
//>>>16运算:4
//>>>16运算:14
//>>>16运算:7
//>>>16运算:13log.info(">>>16运算:{}", 15 & ("郭德纲".hashCode() ^ ("郭德纲".hashCode() >>> 8)));
log.info(">>>16运算:{}", 15 & ("彭于晏".hashCode() ^ ("彭于晏".hashCode() >>> 8)));
log.info(">>>16运算:{}", 15 & ("李小龙".hashCode() ^ ("李小龙".hashCode() >>> 8)));
log.info(">>>16运算:{}", 15 & ("蔡徐鸡".hashCode() ^ ("蔡徐鸡".hashCode() >>> 8)));
//>>>8运算:7
//>>>8运算:1
//>>>8运算:9
//>>>8运算:3 log.info(">>>16运算:{}", 15 & ("郭德纲".hashCode() ^ ("郭德纲".hashCode() >>> 12)));
log.info(">>>16运算:{}", 15 & ("彭于晏".hashCode() ^ ("彭于晏".hashCode() >>> 12)));
log.info(">>>16运算:{}", 15 & ("李小龙".hashCode() ^ ("李小龙".hashCode() >>> 12)));
log.info(">>>16运算:{}", 15 & ("蔡徐鸡".hashCode() ^ ("蔡徐鸡".hashCode() >>> 12)));
//>>>12运算:9
//>>>12运算:12
//>>>12运算:1
//>>>12运算:13
搞java你是避不开hash家族的,与其逃避不如花点心思彻底搞懂!
嘤嘤嘤~ 写了整整一天终于我写完了
嘤嘤嘤~ 好害羞
嘤嘤嘤~ 好紧张








![[carla入门教程]-5 使用ROS与carla通信](https://img-blog.csdnimg.cn/7f16d89b49704a998518792966cbe775.png)