原文来自公众号 无界社区mixlab 链接如下:
https://mp.weixin.qq.com/s/zRqt9OL6G1s3UZY1AJR9ag
关系图谱地址 https://shadowcz007.github.io/text2kg/
本文是对原文进行的复现,现将具体的实现过程记录如下。
#####一. 语料准备
- 延禧攻略剧本
- 延禧攻略小说
- 剧中人物名称
######1.爬取延禧攻略剧本
要获取原始语料的通用办法就是利用爬虫技术对相应的内容进行爬取,由于本次爬取的内容比较简单,不需要考虑网址去重、增量爬取等比较难的问题,因此没有必要选取 scrapy 这种重量级的工具,直接用 request + BeautifulSoup 就足以应付了,代码如下:
# -*- coding: utf-8 -*-
# Author:gaozhengjie
# Blog:https://www.jianshu.com/u/02877dbc2662
# E-mail:gaozhengj@foxmail.com
# Python Version:3.6.1
# Time:2018/8/29
# Description:爬取延禧攻略剧本,并保存在本地import urllib.request
from bs4 import BeautifulSoup# 延禧攻略小说的URL
url = 'http://www.pingyaoji.com/yanqing/yxgljb/'
res = urllib.request.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
character_list = soup.select('ul')[3]# 开始捕捉具体页面的信息
content = ''
for each_li in character_list.select('.title'):res = urllib.request.urlopen('http://www.pingyaoji.com' + each_li.get('href'))soup = BeautifulSoup(res, "html.parser")content = content + soup.select('p')[0].getText()with open(u'延禧攻略剧本.txt', 'w', encoding='utf-8') as fp:fp.write(content)
######2. 爬取延禧攻略小说
小说和剧本均来源于同一个网站,其网页结构均一样,因此代码中只需要修改对应的网址和保存的文件名字即可。
# -*- coding: utf-8 -*-
# Author:gaozhengjie
# Blog:https://www.jianshu.com/u/02877dbc2662
# E-mail:gaozhengj@foxmail.com
# Python Version:3.6.1
# Time:2018/8/29
# Description:爬取延禧攻略小说,并保存在本地import urllib.request
from bs4 import BeautifulSoup# 延禧攻略小说的URL
url = 'http://www.pingyaoji.com/yanxigonglue/?tdsourcetag=s_pctim_aiomsg'
res = urllib.request.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
character_list = soup.select('ul')[3]# 开始捕捉具体页面的信息
content = ''
for each_li in character_list.select('.title'):res = urllib.request.urlopen('http://www.pingyaoji.com' + each_li.get('href'))soup = BeautifulSoup(res, "html.parser")content = content + soup.select('p')[0].getText()with open(u'延禧攻略小说', 'w', encoding='utf-8') as fp:fp.write(content)
######3. 剧中人物名称

上面这个截图就取自于前面我提供的网址里面显示的延禧攻略演员表,这个相比前两个来说,我采用的方法就很简单粗暴了。因为这本身就是一个表格,我直接将其复制到了 Excel 表格中进行处理,复制过去的内容会变成一列,剧中名称和真实名称会交替出现,如下图所示,在这种情况下,如何获取剧中角色的名称呢,可以参考此文 使用Excel隔行选取的3种小技巧。
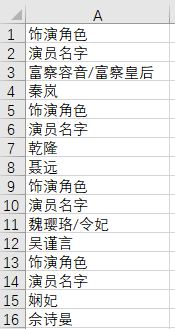
最后别忘记两件事:
- 将里面的 “饰演角色” 和 “演员名字” 删掉;
- 将 “/” 中的内容进行分割,这是同一个人物的不同称呼,当然我们还需要对这些称呼进行完善,部分结果如下图所示。在此感谢 小昕同学 不辞劳苦帮忙完善的角色名称表!

#####二. 数据处理
######1. 分词
- jieba 分词
- 停用词表
- 由角色名称构成的用户自定义词典,以此确保分词的时候能将人物名称提取出来
# -*- coding: utf-8 -*-
# Author:gaozhengjie
# Blog:https://www.jianshu.com/u/02877dbc2662
# E-mail:gaozhengj@foxmail.com
# Python Version:3.6.1
# Time:2018/8/29
# Description:对延禧攻略的文本进行去停用词和分词处理import jieba
import jieba.analyse
import openpyxl# jieba.analyse.set_stop_words('.\\stopwords.txt')
stopwords_file = 'stopwords.txt' # 停用词表
stopwords_set = open(stopwords_file, 'r', encoding='utf-8').read().split('\n') # 导入停用词表
stopwords = [word.strip() for word in stopwords_set]
name_list = open('name_dict.txt', 'r', encoding='GBK').read().split('\n')
jieba.load_userdict(name_list)text = open(u'延禧攻略小说.txt', 'r', encoding='utf-8').read()
word_cut = jieba.cut(text, cut_all=False) # 精确模式,返回的结构是一个可迭代的genertor
word_list = list(word_cut) # genertor转化为list,每个词unicode格式
word_set = []
for word in word_list:word = word.strip()if word not in stopwords and word != '' and not word.isdigit(): # 去停用词# if word >= u'\u4e00' and word <= u'\u9fa5': # 判断是否是汉字word_set.append(word)
word_str = ' '.join(word_set)
# 对别称进行替换并保存分词后的结果
wb = openpyxl.load_workbook('延禧攻略人物名称.xlsx')
sheet = wb[wb.sheetnames[0]]
for i in range(1, sheet.max_row+1):for j in range(2, sheet.max_column+1):if sheet.cell(row=i,column=j).value != None:word_str = word_str.replace(sheet.cell(row=i,column=j).value, sheet.cell(row=i,column=1).value)
open(u'延禧攻略小说分词结果.txt', 'w', encoding='utf-8').write(' '.join(word_set))
######2. 训练 Word2Vec 模型
关于 Word2Vec 的介绍,可以查看公众号中的原文,关于 gensim 中的 word2vec 模型的简单使用,可以参考博文 word2vec的应用----使用gensim来训练模型
from gensim.models import word2vec#加载分此后的文本,使用的是Ttext2Corpus类
sentences = word2vec.Text8Corpus(u'延禧攻略剧本和小说分词结果.txt')#训练模型,部分参数如下
model = word2vec.Word2Vec(sentences, size = 100, hs = 1, min_count = 1, window = 3)# 模型的保存与载入
model.save(u'延禧攻略小说.model')
######3. 处理数据
本模块主要涵盖以下任务:
- 关系图谱中人物的图标有大小之分,越核心的人物的图标越大,关于如何界定人物的重要性呢,本文采用 TF-IDF 方法来计算人物的重要性,将其 TF-IDF 值作为图标的 size 的基准值。对于频率实在太低的边缘性人物,本文直接为其设定了 size 的下界为 1,以此避免图标太小根本看不见的情况。
result.append({"name": i[0], "value": i[1], "symbolSize": max(i[1]*30, 1)}) - 通过设定阈值,计算出每个人物的近邻集合,近邻即是与谁的关系比较接近
- 先将所有人物按照频率降序排列,然后将所有人物依次遍历计算一遍相似度,找到相似人集合,以此建立 source → target 有向关系图
- 将数据构造成 json 格式,然后存储于本地文件夹中,方便前端进行调用
需要注意的是
json 格式中的引号是双引号,而非单引号,同时,一定要用 json.dumps() 方法进行将字符串转换成 json 格式,否则前端的关系图谱无法正常显示。关于python如何解析和转换json数据的可以参看我之前的博文 用Python解析json数据。
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import gensim
import jsonfp = open(u'延禧攻略剧本和小说分词结果.txt', 'r', encoding='utf-8').read()
corpus = [fp]vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重name_dict = {}
with open('name.txt', 'r', encoding='GBK') as fp:for each_name in fp.readlines():name = each_name.strip()try:index = word.index(name)except ValueError as error:pass
# print("无对应的名称", each_name.strip())else:frequency = weight[0,word.index(name)]
# print(name, frequency)name_dict[name] = frequencysort_list = sorted(name_dict.items(),key = lambda x:x[1],reverse = True)# 计算每个节点的信息
result = []
for i in name_dict.items():result.append({"name": i[0], "value": i[1], "symbolSize": max(i[1]*30, 1)})# 接下来主要是处理 source → target 的关系
# 主要需要计算人物之间的相似度
model = gensim.models.Word2Vec.load(u'延禧攻略小说.model')
link = []
for i in range(0,len(sort_list)-1):for j in range(i+1, len(sort_list)):try:if model.similarity(sort_list[i][0], sort_list[j][0]) > 0.9:link.append({"source": sort_list[i][0], "target": sort_list[j][0]})except KeyError as error:passwith open('node_info.txt', 'w', encoding='utf-8') as fp:fp.write(json.dumps(result))
with open('edge_info.txt', 'w', encoding='utf-8') as fp:fp.write(json.dumps(link))
#####前端显示
采用的前端数据可视化框架是 echarts
要显示人物关系图,需要注意以下几个问题:
- json 数据通过 ajax 访问本地文件进行加载,此时需要配置服务器才能进行访问,所幸的是 python 自带的有 http.server ,使用起来非常方便,只需要一行命令即可启动服务器,然后在浏览器中访问即可。
python -m http.server
<!DOCTYPE html>
<html style="height: 100%">
<head><meta charset="utf-8"><!-- 引入 ECharts 文件 --><script src="echarts.min.js"></script><script src="jquery-3.2.1.min.js"></script><script src="http://echarts.baidu.com/gallery/vendors/echarts/extension/dataTool.js"></script>
</head>
<body style="height: 100%; margin: 0">
<div id="container" style="height: 100%; width: 100%"></div><script type="text/javascript">$.ajax({type: "GET",url: "/data/node_info.txt",dataType: "text",success: function (data) {data = eval(data)console.log(data);node_info = data;},error: function (err) {alert("节点信息读取错误");}});$.ajax({type: "GET",url: "/data/edge_info.txt",dataType: "text",success: function (data) {data = eval(data)console.log(data);edge_info = data;},error: function (err) {alert("边信息读取错误");}});var dom = document.getElementById("container");var myChart = echarts.init(dom);var app = {};option = null;app.title = '力引导布局';myChart.showLoading();$.get('/data/les-miserables.gexf', function (xml) {myChart.hideLoading();var graph = echarts.dataTool.gexf.parse(xml);option = {title: {},tooltip: {},legend: [{data: categories.map(function (a) {return a.name;})}],animation: false, // 是否开启动画series: [{type: 'graph',layout: 'force',data: node_info,links: edge_info,roam: true,label: {normal: {position: 'right', // 标签位置show: true, // 显示标签// showContent: true}},force: {initLayout: 'circular',// layoutAnimation: false,repulsion: 100 //排斥力},draggable: true, // 允许拖拽focusNodeAdjacency: true, // 在鼠标移到节点上的时候突出显示节点以及节点的边和邻接节点emphasis: { // 设置高亮图形样式lineStyle: {width: 3},itemStyle: {color: 'black',}},roam: true, // 开启鼠标缩放和平移漫游edgeLength: 10,}]};myChart.setOption(option);}, 'xml');;if (option && typeof option === "object") {myChart.setOption(option, true);}
</script>
</body>
</html>
#####参考文章
- word2vec的应用----使用gensim来训练模型
- 使用Excel隔行选取的3种小技巧
- Python3实现简单的http server
- ECharts Graph Force Demo


![关系型数据库表之间的联系[关系]详解](https://img-blog.csdnimg.cn/20210429211938955.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2NuZHMxMjM=,size_16,color_FFFFFF,t_70)