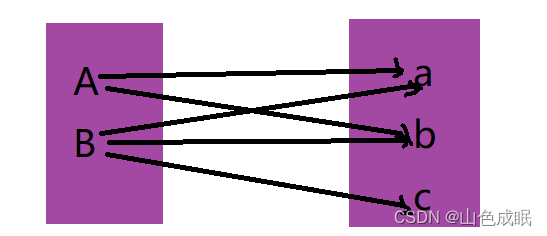
共现,顾名思义 ,共同出现。共现分析有多种,比如分析参考文献、作者、词汇对(关键词)、作者机构等同时出现的情况,分析两者之间的密切联系。
在科研中貌似出现最多的是共词分析,即根据词汇在同一篇论文中共同出现的次数来确定联系,根据词频分析或者聚类分析可以找出词语之间的联系,从而更好地找出文章的主题。还 可以基于某一领域多篇文章的关键词,利用词频分析、聚类分析、关联分析等揭示主题间的依存关系,从而找出该领域的研究热点或者主题的发展演变。
词汇之间的度量不像数学中的向量,计算欧式距离即可,因此要想办法转化为向量,从而计算相似度(欧式距离、余弦相似度),在共现分钟中,我们采用的是共现矩阵,一般是通过词汇对同时出现的 频数来刻画。以下面例子说明:
I like the star.
I like to go shopping.
| 词汇 | I | like | the | star | to | go | shopping |
|---|---|---|---|---|---|---|---|
| I | 0 | 2 | 1 | 0 | 1 | 0 | 0 |
| like | 2 | 0 | |||||
| the | 1 | 1 | 0 | ||||
| star | 0 | 1 | 1 | 0 | |||
| to | 1 | 1 | 0 | 0 | 0 | ||
| go | 0 | 1 | 0 | 0 | 1 | 0 | |
| shopping | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
首先我们需要将两个句子构成 一个词袋{I like the star to go shopping} 然后以此建立矩阵分析词汇对共同出现的次数,这时候需要确定窗口长度 (给度量词汇对共同出现一个限制,超过该窗口长度便不再认为共同出现),这时候设定窗口长度为5,即选定的中心词左右长度为2,2个词以内认为共同出现。这时候利用词频可构建上述共现矩阵。
其实共现矩阵中的行|列可以作为该词的词向量,当然这时候需要大样本量来训练但是这会涉及到一个问题,所涉及的样本量越多,词向量的维度也会随之增大(向量长,维数灾难),向量稀疏性高(向量内积均等于0/两个词语的词向量多数正交,不易分类),向量不够稳健。若用此来构建词向量这时候可以采用的一个方法是利用奇异值分解降为低维向量。
利用词频构造词向量缺乏考虑词汇间的语义关系,语言的博大精深,不能只考虑字面。word2vec可以解决此问题,有时间再详细解释。
本来想基于知网的关键词进行研究,在爬虫时总有些问题,于是转变策略,研究了最近热门剧《冰糖炖雪梨》的人物关系。
基于小说做了个词云图,贴个代码
import requests
import os
import json
import time
import random
from wordcloud import WordCloud, ImageColorGenerator
from os import path
#from scipy.misc import imread
import matplotlib.pyplot as plt
from matplotlib.pyplot import imread
import jieba
import numpy
# 添加自己的词库分词
def add_word(list):for items in list:jieba.add_word(items)
d = path.dirname(__file__)# 获取当前文件路径
def jiebaclearText(text):my_words_list = ['黎语冰','棠雪'] # 在结巴的词库中添加新词add_word(my_words_list)mywordlist = []stopwords_path ='E:\Python\爬虫学习\stopwords1893.txt' # 停用词词表seg_list = jieba.cut(text, cut_all=False)liststr="/ ".join(seg_list)f_stop = open(stopwords_path)try:f_stop_text = f_stop.read( )f_stop_text=str(f_stop_text)finally:f_stop.close( )f_stop_seg_list=f_stop_text.split('\n')for myword in liststr.split('/'):if not(myword.strip() in f_stop_seg_list) and len(myword.strip())>1:mywordlist.append(myword)return ''.join(mywordlist)
def set_background(back_coloring_path):#设置生成词云图的背景图片back_coloring = imread(path.join(d, back_coloring_path)) # 设置背景图片return back_coloring
def create_word_cloud(text_jieba,back_coloring):font_path = 'D:\Documents\simkai.ttf' # 为matplotlib设置中文字体路径没# 设置词云属性wc = WordCloud(font_path=font_path, # 设置字体collocations=False,#去重background_color="white", # 背景颜色max_words=2000, # 词云显示的最大词数mask=back_coloring, # 设置背景图片max_font_size=100, # 字体最大值random_state=42,width=1000, height=860, margin=2, # 设置图片默认的大小,但是如果使用背景图片的话,那么保存的图片大小将会按照其大小保存,margin为词语边缘距离)wc.generate(text_jieba)
# 生成词云, 可以用generate输入全部文本(wordcloud对中文分词支持不好,建议启用中文分词),也可以我们计算好词频后使用generate_from_frequencies函数plt.figure()# 以下代码显示图片plt.imshow(wc)plt.axis("off")plt.show()# 绘制词云wc.to_file(path.join(d, imgname1)) # 保存图片,保存到该文件夹下,且为图片命名
if __name__ == '__main__':stopwords = {}#isCN = 1 # 默认启用中文分词text_path ='BTDXL.txt' # 设置要分析的文本路径back_coloring_path = 'E:\Python\爬虫学习\heart2.jpg' # 设置背景图片路径text = open(path.join(d, text_path),encoding='utf-8').read()text_jieba = jiebaclearText(text)imgname1 = "jdDefautColors.png" # 保存的图片名字1(只按照背景图片形状)back_coloring =set_background(back_coloring_path)create_word_cloud(text_jieba,back_coloring)
回归正题,分析人物的关系
1.先建立人物名单,做个人物字典,nr为词性

2.建立一个别名名单,做个别名字典

3.利用jieba分词将小说分词,然后返回词性,当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名,然后作同义词转换(将别名转换),统计人物出现次数,以及人物之间的联系,保存在People_edge.txt。
4.可视化
将人物关系保存为.csv文件,导入gephi软件,一款网络分析软件。在安装软件时一定要事先配置好JDK。详细解释可以看 link.
import codecs
import jieba.posseg as pseg
import jiebanames = {}# 保存人物,键为人物名称,值为该人物在全文中出现的次数
relationships = {}#保存人物关系的有向边,键为有向边的起点,值为一个字典 edge ,edge 的键为有向边的终点,值是有向边的权值
lineNames = []# 缓存变量,保存对每一段分词得到当前段中出现的人物名称
synnonymous_dict = {}
jieba.load_userdict("person.txt")#加载人物表
def synonymous_names():#获取同义名词典with codecs.open("bieming.txt", 'r', 'utf8') as f:lines = f.read().split('\r\n')for l in lines:synnonymous_dict[l.split(' ')[0]]=l.split(' ')[1]return synnonymous_dict
with codecs.open("BTDXL.txt", 'r', 'utf8') as f:for line in f.readlines():poss = pseg.cut(line) # 分词,返回词性lineNames.append([]) # 为本段增加一个人物列表for w in poss:if w.flag != 'nr' or len(w.word) < 2:continue # 当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名synnonymous = synonymous_names()if synnonymous.get(w):w = synnonymous[w]#做同义词转换lineNames[-1].append(w.word) # 为当前段的环境增加一个人物if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中names[w.word] = 0relationships[w.word] = {}names[w.word] += 1# 输出人物出现次数统计结果
# for name, times in names.items():
# print(name, times)# 对于 lineNames 中每一行,我们为该行中出现的所有人物两两相连。如果两个人物之间尚未有边建立,则将新建的边权值设为 1,
# 否则将已存在的边的权值加 1。这种方法将产生很多的冗余边,这些冗余边将在最后处理。
for line in lineNames:for name1 in line:for name2 in line:if name1 == name2:continueif relationships[name1].get(name2) is None:relationships[name1][name2] = 1else:relationships[name1][name2] = relationships[name1][name2] + 1# 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边# 为此可设置阈值为10,即当边出现10次以上则认为不是冗余with codecs.open("People_node.txt", "w", "utf8") as f:f.write("ID Label Weight\r\n")for name, times in names.items():if times > 10:f.write(name + " " + name + " " + str(times) + "\r\n")with codecs.open("People_edge.txt", "w", "utf8") as f:f.write("Source Target Weight\r\n")for name, edges in relationships.items():for v, w in edges.items():if w > 10:f.write(name + " " + v + " " + str(w) + "\r\n")
许多博客是利用代码删除非人物的节点,为了方便,其实可以运用gephi软件中的数据资料中的节点来删除。

有种蝴蝶飞舞的感觉,在故事里的主角,也因为身边的人更加精彩。
关于共现分析,更为具体的解释可见链接https://blog.csdn.net/zhaozhn5/article/details/78247517.

![关系型数据库表之间的联系[关系]详解](https://img-blog.csdnimg.cn/20210429211938955.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2NuZHMxMjM=,size_16,color_FFFFFF,t_70)