《Cross-Modal and Hierarchical Modeling of Video and Text》(2018 ECCV)
这篇文章主要介绍了一个叫做分层序列嵌入(Hierarchical Sequence Embedding, HSE)的通用模型,其作用是对不同模态的数据进行分层建模并利用…
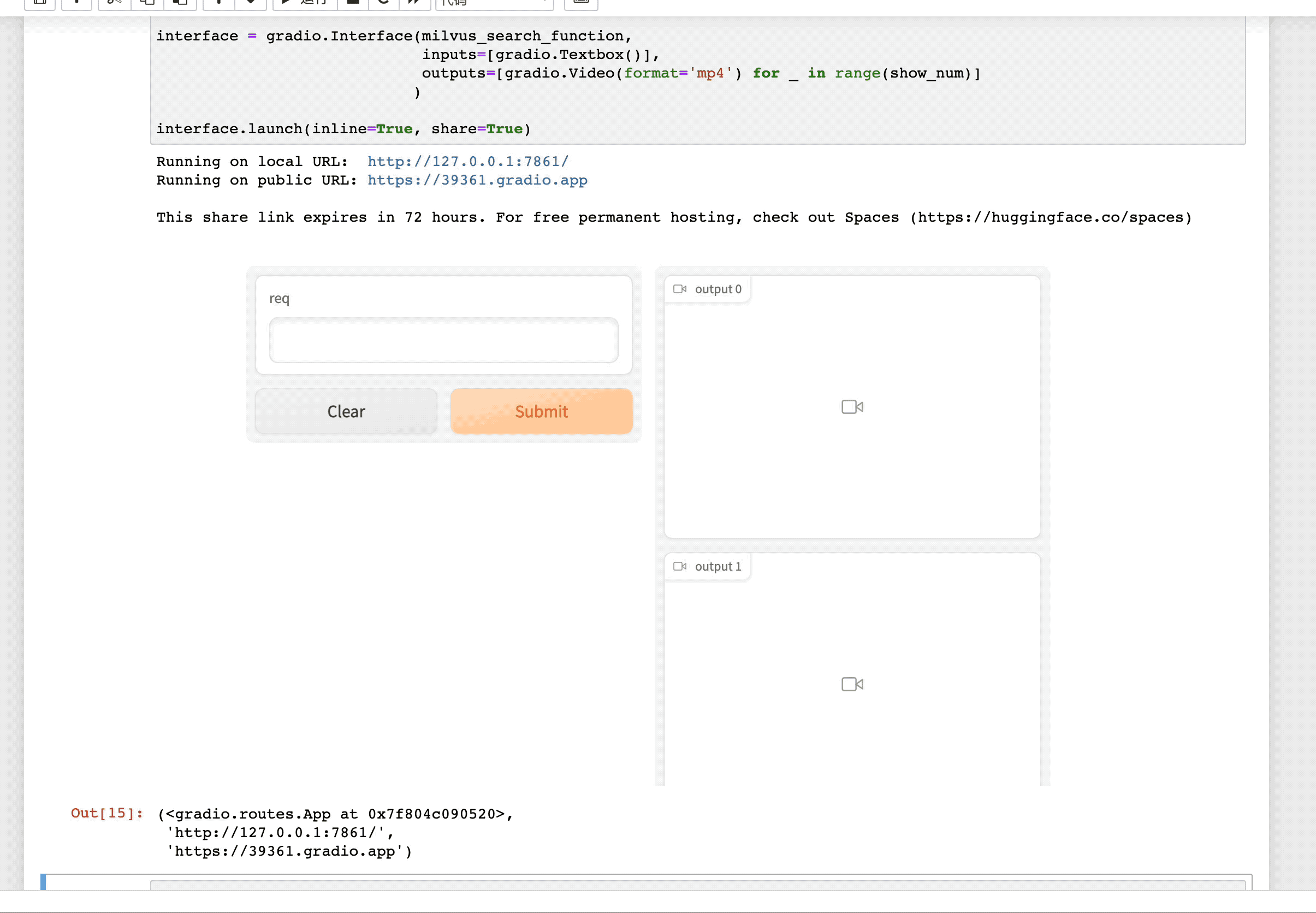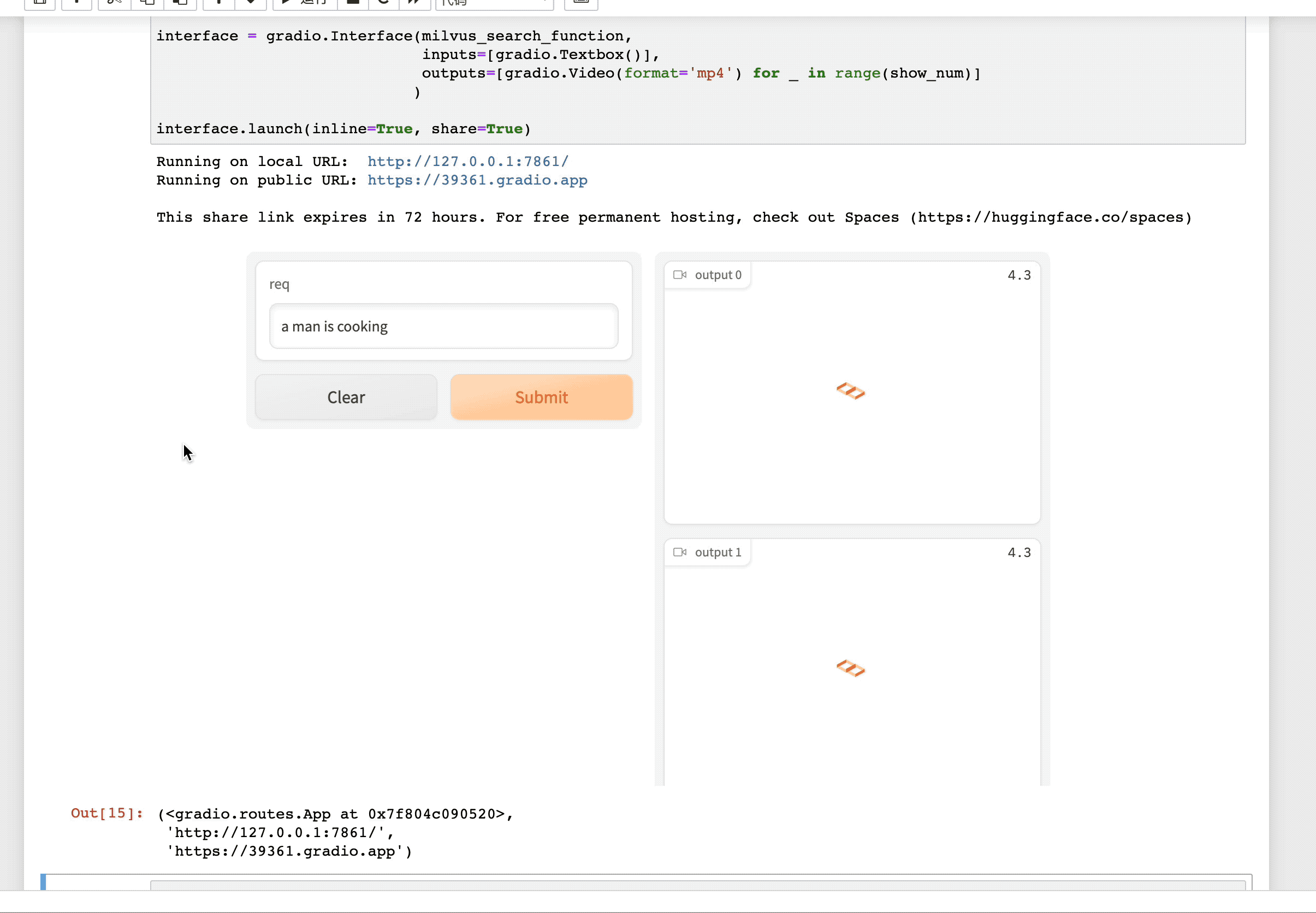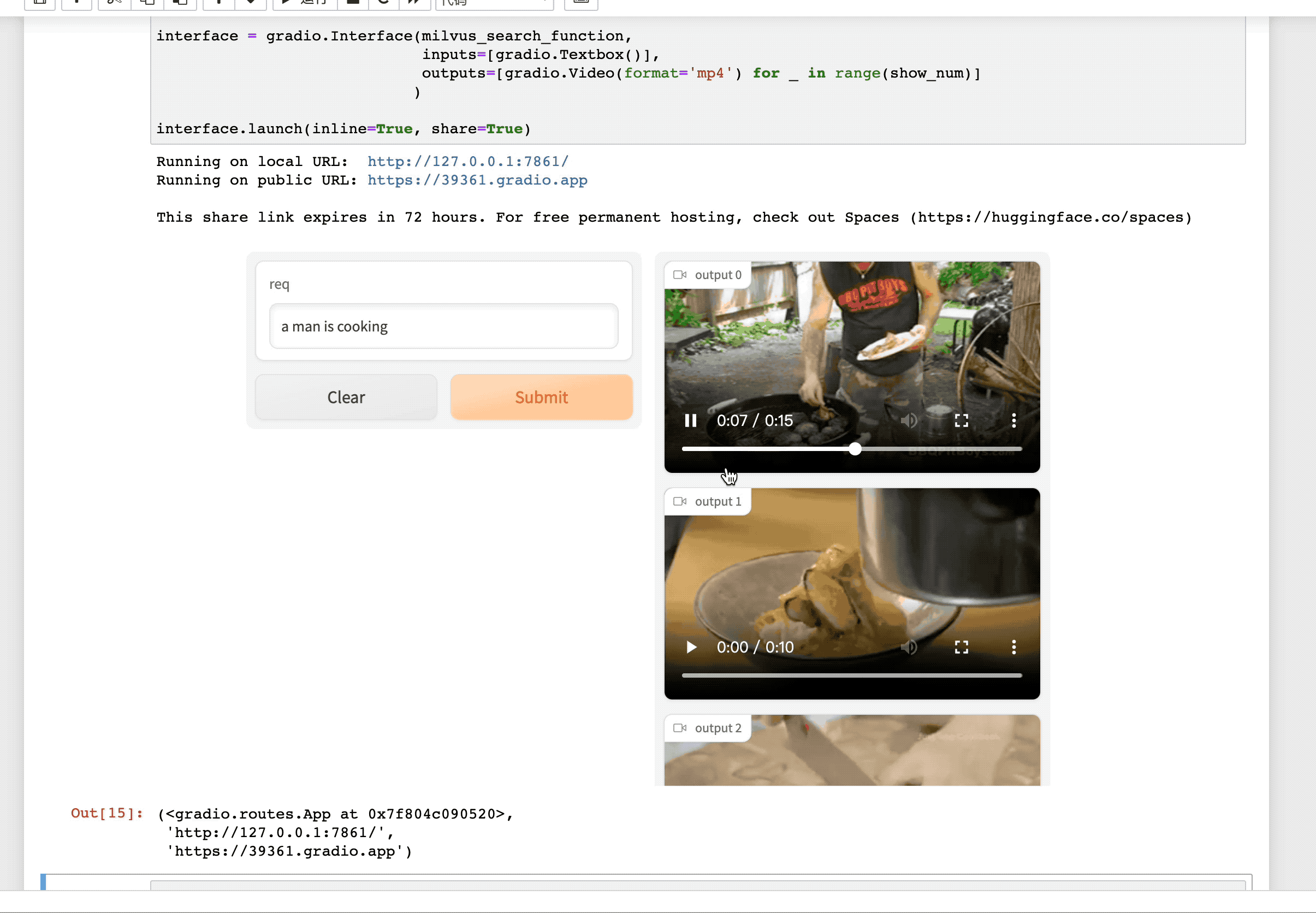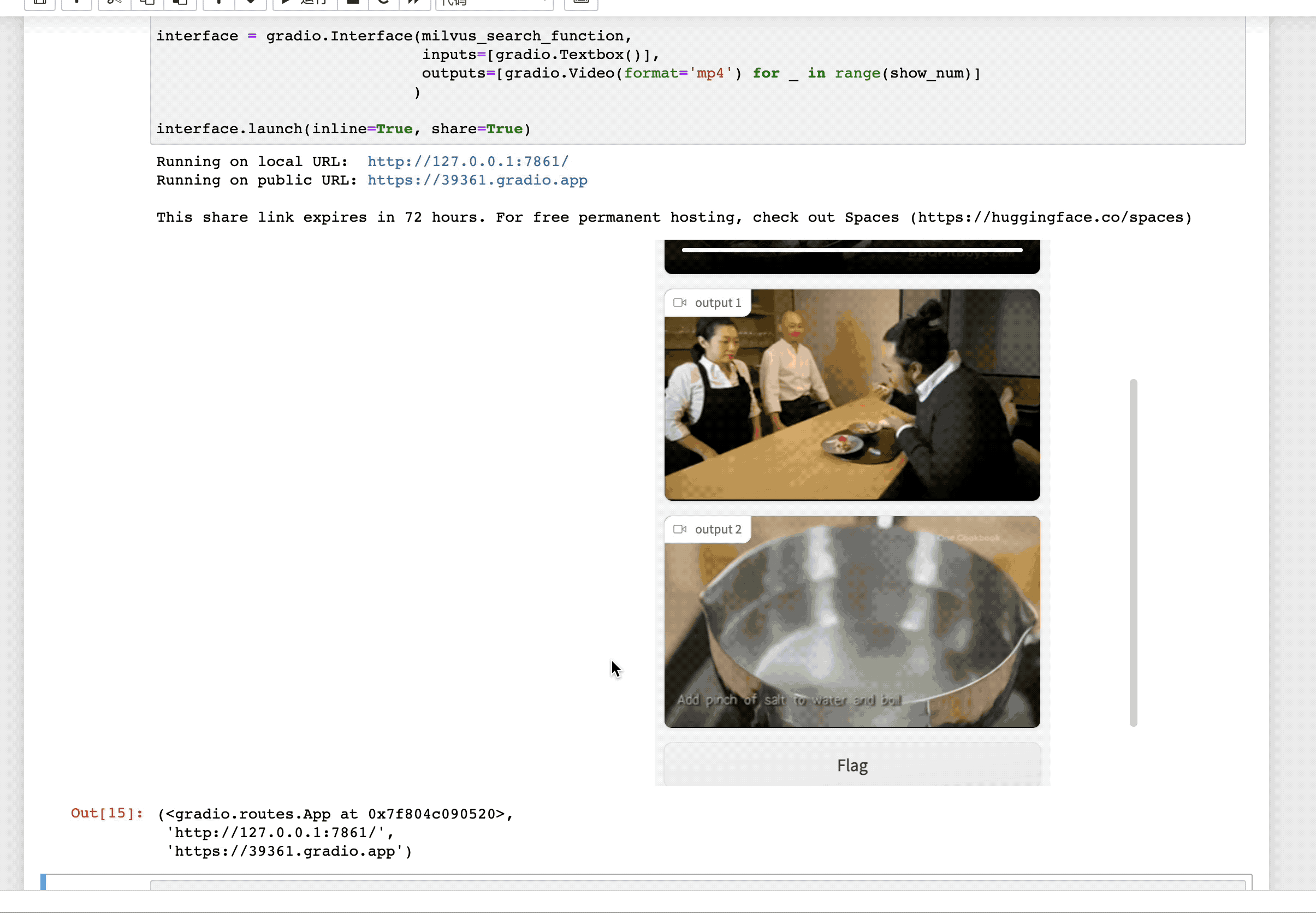
论文:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
GitHub:https://github.com/ArrowLuo/CLIP4Clip 学习是一种行动反射,
不是为了晓得些“知识”,
要切己体察,代入自己,…
《Multilevel Language and Vision Integration for Text-to-Clip Retrieval》(2018 CVPR)
这篇文章引入了一个多层的模型,输入一个描述某个动作的查询语句,就可以从一段没有经过修剪的视频中找出对应的片段。
首先是第一个阶段…
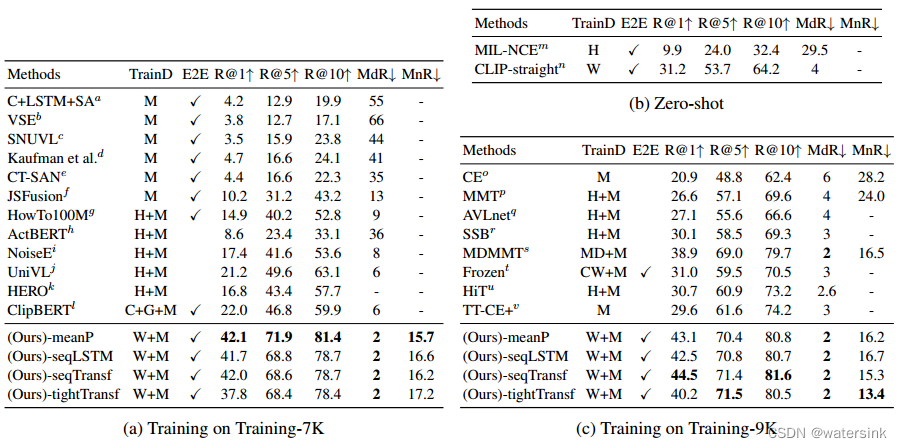
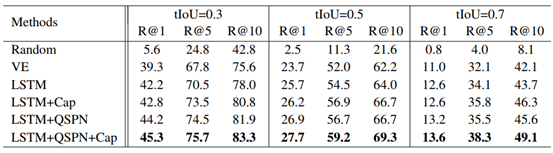
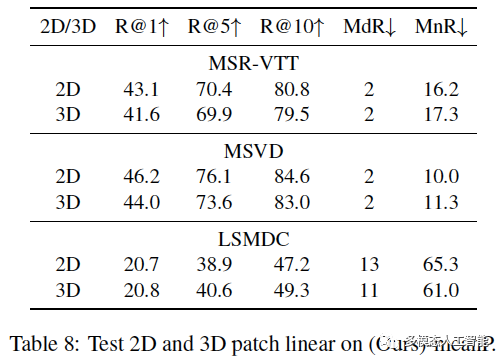
Luo, Huaishao, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan and Tianrui Li. “CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval.” ArXiv abs/2104.08860 (2021). 1. Abstract
视频文本检索在多模态研究中起着至关重要的作用,…