关注公众号,发现CV技术之美
▊ 写在前面
检索与自然语言查询相关的视频内容对于有效处理互联网规模的数据集起着关键作用。现有的大多数文本到视频检索方法都没有充分利用视频中的跨模态线索。此外,它们以有限或没有时间信息的方式聚合每帧视觉特征。
在本文中,作者提出了一种多模态Transformer(MMT)来对视频中的不同模态进行联合编码,从而允许它们中的每一帧关注其他模态。此外,Transformer架构还用于对时间信息进行编码和建模。通过实验表明,本文提出的多模态Transformer能够在多个数据集上实现SOTA的视频检索性能。
▊ 1. 论文和代码地址

Multi-modal Transformer for Video Retrieval
论文地址:https://arxiv.org/abs/2007.10639
代码地址:https://github.com/gabeur/mmt
▊ 2. Motivation
视频是目前最受欢迎的媒体形式之一,因为它能够捕捉动态事件,并自然地吸引人类的视觉和听觉感官。在线视频平台在推动这种媒体形式方面发挥着重要作用。
然而,如果不能有效地访问这些平台上数十亿小时的视频,例如通过查询检索相关内容,那么这些平台上的视频将无法使用。
在本文中,作者解决了文本到视频和视频到文本的检索任务。在文本到视频的检索任务中,给定一个文本形式的查询,目标是检索能够最好描述它的视频。
实际上,给定文本-视频对的测试集,模型的目标是为每个文本查询提供所有候选视频的排名,以便与文本查询相关联的视频的排名尽可能高。另一方面,视频到文本检索的任务侧重于在文本候选集合中找到最能描述查询视频的候选文本。
检索问题的一种常见方法是相似性学习,即学习衡量两个元素(查询和候选元素)相似性的函数。然后,可以根据与查询的相似性对所有候选对象进行排序。为了执行该排序,文本以及视频被表示在公共多维嵌入空间中,其中相似性可以被计算为其相应表示的点积。这里的关键问题是如何学习文本和视频的精确表示,以建立相似性估计。

文本的学习表征问题已经得到了广泛的研究,可用于对文本进行编码。与这些进步相反,学习有效的视频表示仍然是一个挑战,这也是本文工作的重点。视频数据不仅在外观上有所不同,而且在运动、音频、叠加文本、语音等方面也有所不同。
因此,利用好跨模态关系是构建有效视频表示的关键 。如上图所示,从所有组成模态中联合提取的线索比单独处理每个模态更具信息性。
最近的视频检索工作并没有充分利用这种跨模态高层语义。视频表示的另一个挑战是它的时间性。由于难以处理视频的可变持续时间,目前的方法通常通过聚合视频中不同时刻提取的描述来丢弃长期时间信息。作者认为,这些时间信息对视频检索任务非常重要。
综上所述,作者提出了多模态Transformer来解决视频数据中的时间和多模态挑战。它执行的任务是处理在视频中不同时刻从不同模态中提取的特征,并将它们聚集在一个紧凑的表示中。
基于Transformer架构,本文的多模态transformer利用自注意力机制收集视频中发生的事件的跨模态和时间线索。作者将本文的多模态Transformer集成到一个跨模态框架中,该框架充分利用了文本和视频信息,并估计了它们的相似性。
▊ 3. 方法
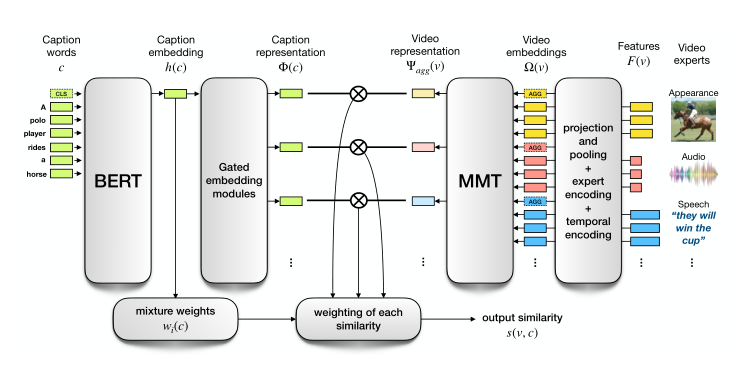
本文的总体方法依赖于学习函数来计算两个元素(文本和视频)之间的相似性,如上图所示。然后,作者根据文本到视频(或视频到文本)检索中与查询文本(或视频)的相似性,对数据集中的所有视频(或文本)进行排序。
换句话说,给定n个视频文本对的数据集,目标是学习视频和文本之间的相似性函数。如果,那么返回一个高的相似度值;否则返回一个低的相似度值。
3.1 Video representation
视频级表示由本文提出的多模态Transformer(MMT)来计算。MMT遵循Transformer编码器的结构。它由堆叠的自注意力层和全连接层组成。MMT的输入() 是一组嵌入,所有嵌入都具有相同的。每个特征都同时嵌入了特征的语义、模态和时间信息。该输入可以表示为下面的公式:
Features
为了从视频数据中的不同模态中学习有效的表示,作者从称为“专家”的视频特征提取器开始。与以前的方法相比,MMT学习了一种利用专家之间的跨模态和长期时间关系的联合表示。
作者使用N个预训练的专家。每个专家都是为特定任务训练的模型,然后用于从视频中提取特征。对于一个视频v,每个专家提取K个特征的序列。
专家提取的特征编码了视频的语义。每个专家输出特征为。为了将不同的专家特征投影到一个公共维度中,作者学习了N个FC层(每个专家一个)来将所有特征投影到中。
Transformer编码器为其每个特征输入生成嵌入,从而为一个专家生成了多个嵌入。为了获得每个专家的唯一嵌入,作者定义了一个聚合嵌入,它将收集专家的信息并将其上下文化。
作者使用所有相应专家特征的最大池化聚合(max-pooling aggregation)初始化此嵌入,得到。然后,视频编码器的输入特征序列采用以下形式:
Expert embeddings
为了处理跨模态信息,MMT需要确定它所关注的专家。因此,作者学习了N个的嵌入来区分不同专家的嵌入。因此,视频编码器的专家嵌入序列采用以下形式:
Temporal embeddings
视频中的特征具有时序的信息,考虑到最大持续时间为秒的视频,作者学习了个维度为的嵌入特征。在时间范围内提取的每个专家特征将嵌入。此外,作者还学习了另外两个时间嵌入和,用来编码聚合特征和未知时态信息特征。视频编码器的时间嵌入序列采用以下形式:
Multi-modal Transformer
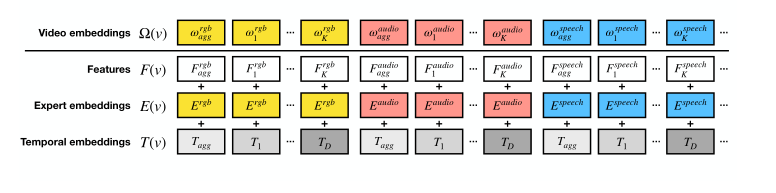
如上图所示,视频嵌入()为特征、专家和时间嵌入的和,这个也是MMT的输入特征,即:
MMT将其输入上下文化并生成视频表示。在输出时,作者只保留的每个专家的聚合特征:
与collaborative gating机制相比,本文的MMT的优势有两个方面:首先,输入嵌入不是简单地在一个步骤中进行调整,而是通过多个注意力头的几个层次进行迭代优化。
其次,作者提供了所有时刻的提取特征,以及一个描述从视频中提取特征时刻的时间编码。由于其自注意力模块,本文的多模态Transformer的每一层都能够处理所有输入嵌入,从而提取视频中发生的事件在多个模态上的语义。
3.2 Caption representation
作者分两个阶段计算文本表示:首先,作者获得了文本的嵌入,然后使用一个函数将其投影到不同的空间,即◦。对于嵌入函数h,作者使用了预训练的BERT模型。
具体地说,作者从BERT的[CLS]输出中提取文本嵌入。为了使文本表示的大小与视频的大小相匹配,学习的函数可以作为多个门控嵌入模块,以匹配不同的视频专家。因此,文本嵌入可以表示为。
3.3 Similarity estimation
最终的视频文本相似性为每个专家视频文本相似性的加权和,如下所示:
其中表示第i个专家的权重。这个权重由在文本表示上施加线性层,并用Softmax实现:
其中表示线性层的权重,使用加权和的原因是,文本可能无法统一描述视频中的所有模态。例如,在一段视频中,一个穿着红色衣服的人正在唱歌剧,文本“一个穿着红色衣服的人”没有提供与音频相关的信息。相反,“有人在唱歌”的文本应该侧重于计算与音频模态的相似度。
3.4 Training
作者采用了bi-directional max-margin ranking loss来计算损失函数:
其中为batch大小,为视频和文本之间的相似性得分。该损失强制匹配的视频文本对的相似性比不匹配的相似性至少高出。
▊ 4.实验
4.1. Pretraining
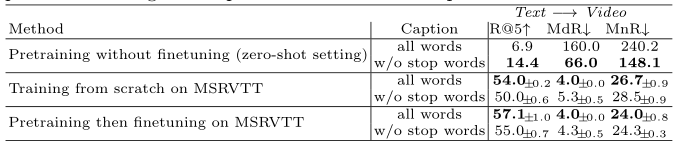
上表展示了在HowTo100M上预训练和在MSRVTT上微调的结果,可以看出,预训练对于性能的提升有促进作用。

上表展示了在HowTo100M上预训练和在ActivityNet上微调的结果。
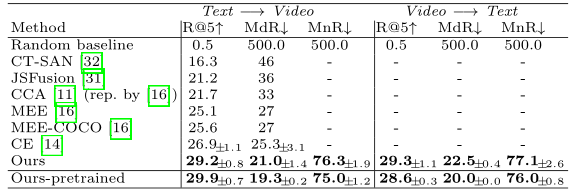
上表展示了在HowTo100M上预训练和在LSMDC上微调的结果。
4.2. Language encoder
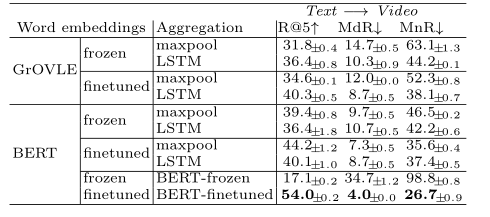
上表展示了不同本文编码器的实验结果,可以看出,BERT微调后的实验结果是最好的。不微调的BERT效果较差,这可能是因为预训练数据集和下游任务数据集的域差距较大。
4.3. Video encoder
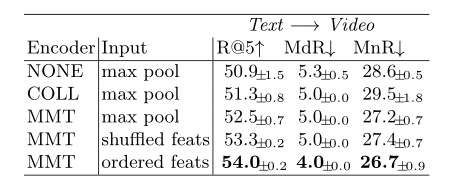
上表展示了不同输入和Encoder网络结构的实验结果。

上表展示了不同初始化专家聚合特征的实验结果。

上表展示了不同层数和head数的实验结果。
4.4. Comparison of the different experts
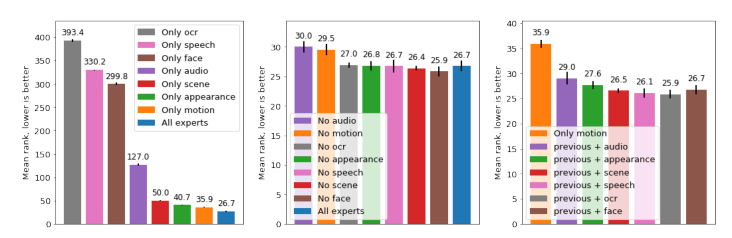
上表展示了在模型上使用不同的专家的实验结果,可以看出单独的音频专家并不能提供良好的性能,但与其他专家一起使用时,它的贡献最大,很可能是因为与其他专家相比,它提供了互补的线索。
4.5. Comparison to prior state of the art
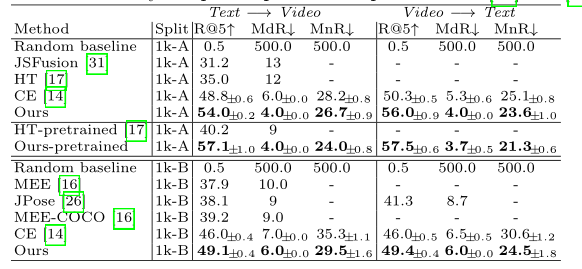

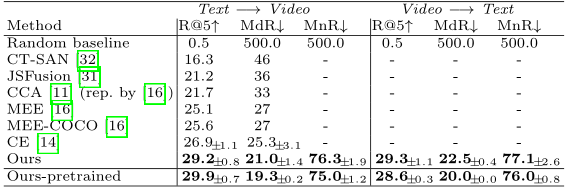
上面三个表格展示了本文方法和SOTA方法在MSR VTT、ActivityNet、LSMDC数据集上对比。可以看出,跟SOTA方法相比,本文的方法在性能上具有绝对的优势。
▊ 5. 总结
在本文中,作者提出了multi-modal transformer(多模态Transformer) ,这是一种基于transformer的结构,能够处理在不同时刻从视频中的不同模态提取的多个特征。
这利用了时间和跨模态线索,对于准确的视频表示至关重要。作者将此视频编码器与文本编码器合并到跨模态框架中,以执行视频文本检索,并在多个数据集上达到了SOTA的性能
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视频检索」交流群👇备注:检索