AVS任务也是跨模态检索中的一种,即对于给定的句子,尝试在视频库中检索出语义相关的内容。而跨模态相关的文章,博主已经在其他跨模态检索的文章中介绍过了。Ad-hoc和传统的视频检索任务不太一样,如它的名字ad-hoc一样,这其实属于推荐中的两者形态:
- ad hoc。类似于书籍检索。数据相对稳定不变,而查询千变万化。
- routing。类型与新闻推荐。用户兴趣稳定不变,但数据不断变化。
一般的跨模态会有预定义语义标签,而AVS任务只能通过建模用户的 查询意图, 所以某种程度上它的难度更偏向于相似度匹配问题。
ASV主要有两种处理思路,一是基于concept/keyword这种概念,二是基于特征。接下来本文将从这两个方面进行整理。
基于概念一般需要做三个步骤:显式的概念–匹配—选择。
- 从查询句子中提取一个或多个关键字。
- 选择与关键字相关的一个或多个概念分类器。
- 对于每个测试视频序列,通过集成来自多个概念分类器的分数来计算查询短语的分数。
[IVCNZ2018] Latent Concept Extraction for Zero-shot Video Retrieval
这篇文章对于文本概念的处理是:
- 大量预先训练的概念分类器来提高查询中出现的单词的覆盖率,尝试把复杂的查询也变成多个概念的组合。
- 引入自然语言处理技术,即使没有与关键字对应的概念分类器,也能够找到可替换的概念分类器,进一步提高词的覆盖率。
但是对于某些词的效果仍然很槽糕,虽然继续增加概念分类器的变化是一个解决方案,但不可能涵盖所有关键字。所以
- 能找到关于未知关键字的潜在概念分类器吗?
- 能用现有概念分类器的组合来表示查询短语吗?
于是基于特征的方法就开始流行了。将输入都映射到同一语义空间,再进行匹配与对比。

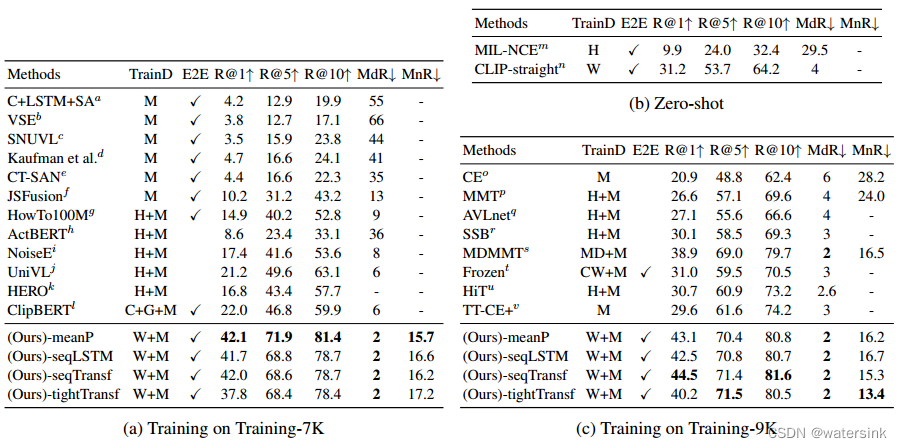
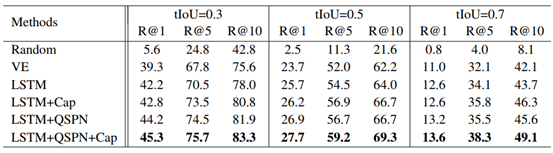
[MM2019] W2VV++: Fully Deep Learning for Ad-hoc Video Search
以往的AVS任务需要显式的概念建模(如对象、动作、场景)、匹配和选择,这份工作完全基于深度学习而不需要建模概念。同时W2VV发现对文本的多种建模要比一种有效,而W2VV++是基于此的升级版。模型结构如上图:
- 文本端bow+w2v+GRU进行多种得到特征。
- 视频端均匀采样帧后用ResNeXt-101+ResNet-152得到特征
- 然后Triple loss。
class W2VV_MS(Base_model):def __init__(self, opt, we_weights=None):n_layers = opt.n_text_layers#只支持lstm和gru的文本计算assert (opt.rnn_style in ['lstm', 'gru']), "not supported LSTM style (%s)" % lstm_style#构建模型print("Building model...")#输入词到rnnmain_input = Input(shape=(opt.sent_maxlen,))#再分别用 bow, word2vec 或者word hashing来嵌入句子特征auxiliary_input = Input(shape=(n_layers[0],))if we_weights is None: #如果有预训练的结果we = Embedding(opt.vocab_size, opt.embed_size)(main_input)else: #没有就再Embeddingwe = Embedding(opt.vocab_size, opt.embed_size, trainable=True, weights = [we_weights])(main_input)we_dropout = Dropout(opt.dropout)(we)#lstm_out = LSTM(lstm_size, return_sequences=False, unroll=True, consume_less='gpu', init='glorot_uniform')(we_dropout)if opt.rnn_style == 'lstm':lstm_out = LSTM(opt.rnn_size, return_sequences=False, unroll=True, dropout=opt.dropout, recurrent_dropout=opt.dropout)(we_dropout)elif opt.rnn_style == 'gru':lstm_out = GRU(opt.rnn_size, return_sequences=False, unroll=True, dropout=opt.dropout, recurrent_dropout=opt.dropout)(we_dropout)x = concatenate([lstm_out, auxiliary_input], axis=-1) #拼接主特征和辅助特征for n_neuron in range(1,len(n_layers)-1): #再用mlp抽象一下x = Dense(n_layers[n_neuron], activation=opt.hidden_act, kernel_regularizer=l2(opt.l2_p))(x)x = Dropout(opt.dropout)(x)output = Dense(n_layers[-1], activation=opt.hidden_act, kernel_regularizer=l2(opt.l2_p))(x)self.model = Model(inputs=[main_input, auxiliary_input], outputs=output)self.model.summary()def predict_one(self, text_vec, text_vec_2):text_embed_vec = self.model.predict([np.array([text_vec]), np.array([text_vec_2])])return text_embed_vec[0]def predict_batch(self, text_vec_batch, text_vec_batch_2):text_embed_vecs = self.model.predict([np.array(text_vec_batch), np.array(text_vec_batch_2)])return text_embed_vecs
code: https://github.com/danieljf24/w2vv
[MM2020] A W2VV++ Case Study with Automated and Interactive Text-to-Video Retrieval
把上述文本侧的表示继续升级成了bow-w2v-bert。
code: https://github.com/li-xirong/w2vvpp

[ICMR2020] Attention Mechanisms, Signal Encodings and Fusion Strategies for Improved Ad-hoc Video Search with Dual Encoding Networks
视频侧和文本侧也是多种级别的表示方法。特别的地方在于使用了两种不同的注意力机制,目的是在每种模态中突出时间位置,以更好的进行文本和视觉表示。
来看一下对于视频的多级别表示的操作代码:
class Video_multilevel_encoding(nn.Module):""""""def __init__(self, opt):super(Video_multilevel_encoding, self).__init__()self.rnn_output_size = opt.visual_rnn_size * 2self.dropout = nn.Dropout(p=opt.dropout)self.visual_norm = opt.visual_normself.concate = opt.concate#用 BiGRU来编码特征self.rnn = nn.GRU(opt.visual_feat_dim, opt.visual_rnn_size, batch_first=True, bidirectional=True)#1-d的CNN层self.convs1 = nn.ModuleList([nn.Conv2d(1, opt.visual_kernel_num, (window_size, self.rnn_output_size), padding=(window_size - 1, 0))for window_size in opt.visual_kernel_sizes])#视觉投影层self.visual_mapping = MFC(opt.visual_mapping_layers, opt.dropout, have_bn=True, have_last_bn=True)def forward(self, videos):"""抽取视频表示特征."""videos, videos_origin, lengths, vidoes_mask = videos# Level 1. 用平均池化来编码全局特征org_out = videos_origin# Level 2. 用biGRU编码时间感知gru_init_out, _ = self.rnn(videos)mean_gru = Variable(torch.zeros(gru_init_out.size(0), self.rnn_output_size)).cuda()for i, batch in enumerate(gru_init_out): #也需要池化mean_gru[i] = torch.mean(batch[:lengths[i]], 0)gru_out = mean_grugru_out = self.dropout(gru_out)# Level 3. 编码局部特征vidoes_mask = vidoes_mask.unsqueeze(2).expand(-1, -1, gru_init_out.size(2)) # (N,C,F1)gru_init_out = gru_init_out * vidoes_maskcon_out = gru_init_out.unsqueeze(1)con_out = [F.relu(conv(con_out)).squeeze(3) for conv in self.convs1]con_out = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in con_out]con_out = torch.cat(con_out, 1)con_out = self.dropout(con_out)# 拼接到一起if self.concate == 'full': # level 1+2+3features = torch.cat((gru_out, con_out, org_out), 1)elif self.concate == 'reduced': # level 2+3features = torch.cat((gru_out, con_out), 1)# 投影到共同空间features = self.visual_mapping(features)if self.visual_norm:features = l2norm(features)return features
code:: https://github.com/bmezaris/AVS_dual_encoding_attention_network

[MM2020] Interpretable Embedding for Ad-Hoc Video Search
不通过概念的方法虽然取得了很好的效果,但是这种将特征直接嵌入联合空间的做法不可解释,所以本文将特征嵌入和概念解释集成到一个神经网络中,用于统一的双任务学习,以让嵌入与语义概念列表相关联,作为对视频内容的解释。
- 任务1:视觉-文本嵌入。
- 任务2:多标签概念分类。
同时由于视频内容是多视角的,内容可以根据讨论主题中感兴趣的主题或上下文从不同的角度进行叙述。而且即使从一个角度来看,也有多种方法使用不同的单词来表达相同的语义,所以在caption中没出现的不一定就是错的,可能只是没有提到。所以作者提出一个新的BCE loss,分为两个部分:
- 正常的算caption的词和视频语义概念之间的多标签loss。
- 其他没有提到/激活的词的loss,并且给与较高的权重用来平衡以扩大语义概念。
数据集
- IACC.3
- MSR-VTT
- TGIF
- TRECVID 20xx
有一个github供下载数据集:https://github.com/li-xirong/avs