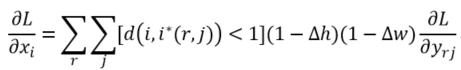文中很多内容来源于其他博客,较为详细,有需要可直接按目录跳选到自己需要的部分。
目录
简单介绍
实验比较
ROI理解
ROI Pooling
ROI Pooling理解
ROI Pooling example
ROI Pooling局限性
ROI Align理解
双线性插值法
ROI Align的反向传播
ROI Warp理解
数据获取/丢失 比较
参考博客
简单介绍
ROI Align 是何凯明在2017年的论文Mask-RCNN中提出的,该方法很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment)问题。本文将先简单对比实验效果,然后介绍分析ROI Pooling流程以及产生局限性的具体原因,和ROI Align的解决方法。
实验比较
论文Mask-RCNN中针对ROI Align和ROI Pooling的实验结果,对比可以发现ROI Align更为强大。


(c)表中基于ResNet-50-C4框架的结果中,ROI Align的分割效果明显好于ROI Pooling 和ROI Warp的效果;平均池化和最大化池化后的结果差不多,论文中多是用的平均池化的方法。
(d)表中基于ResNet-50-C5框架的实验中,使用ROI Align在检测和分割领域的AP都比ROI Pooling的结果要高;池化输入的特征图比网络输入图的缩小比例越大,则ROI Align的效果越明显(缩小32倍的AP30.9大于缩小16倍的AP30.3)。
ROI理解
RoI(Region of Interest),感兴趣区域,是从原始图像中提取的区域,用户所关注的区域。
感兴趣区域池化(也称为 RoI Pooling)是一种广泛用于使用卷积神经网络的对象检测任务的操作。例如,在单个图像中检测多辆汽车和行人。其目的是对非均匀大小的输入执行最大池化以获得固定大小的特征图(例如 7×7)。
目标检测中two-stage方法通常可以分为两个阶段:
- Region Proposal 候选区域:给定输入图像,找到可以定位对象的所有可能位置。此阶段的输出应该是对象可能位置的边界框列表。这些通常称为候选区域 region proposals 或 感兴趣区域 regions of interest(ROI)。在这一过程中常用的方法是滑动窗口和selective search选择性搜索法。
- 最终分类 Final Classification:对于前一阶段的每个候选区域,决定它是属于一个目标类还是属于背景。这里可以使用深度卷积网络。

通常在Proposal 阶段,我们必须生成很多感兴趣区域 ROI 。为什么?如果在第一阶段(Region Proposal)未检测到对象,则无法在第二阶段对其进行正确分类。这就是为什么Region Proposal具有高召回率极其重要的原因。这是通过生成大量Proposal(例如,每帧几千个)来实现的。他们中的大多数将在检测算法的第二阶段被归类为背景。
这种架构的一些问题是:
- 生成大量感兴趣区域ROI会导致性能问题。这将使实时对象检测难以实现。
- 就处理速度而言,它是次优的。
- 无法进行端到端的训练,即你不能在一次运行中训练系统的所有组件(这会产生更好的结果)
这就是ROI Pooling发挥作用的地方。
ROI Pooling
ROI Pooling理解
感兴趣区域池化(ROI Pooling)是用于对象检测任务的神经网络层。它由 Ross Girshick 于 2015 年 4 月首次于Fast RCNN中提出,它实现了训练和测试的显著加速,还保持了较高的检测精度。该层有两个输入:
- 从具有多个卷积和最大池化层的深度卷积网络获得的固定大小的特征图 feature map。
- 一个表示感兴趣区域ROI列表的 N*5 矩阵,其中 N 是 ROI 的数量。第一列代表图像索引,其余四列是区域左上角和右下角的坐标。
ROI Pooling实际上有什么作用?对于输入列表中的每个感兴趣区域ROI,它会获取与其对应的输入特征图的一部分,并将其缩放到某个预定义的大小(例如,7×7)。缩放是通过以下方式完成的:
- Dividing the region proposal into equal-sized sections (the number of which is the same as the dimension of the output)
- Finding the largest value in each section
- Copying these max values to the output buffer
- 将 region proposal 分成大小相等的section(section数量与输出的维度相同)
- 找到每个section的最大值
- 将这些最大值复制到输出缓冲区

可以从一个不同大小的矩形列表中快速得到一个固定大小的对应特征图 feature map的列表。
请注意,RoI Pooling输出的维度实际上并不取决于输入特征图 feature map的大小,也不取决于候选区域 region proposal的大小。它完全取决于我们将proposal分成的section的数量。
ROI Pooling 的好处是什么?其中之一是处理速度。如果框架上有多个object proposals(通常会有很多),我们仍然可以对所有对象使用相同的输入特征图。由于在处理的早期阶段计算卷积非常昂贵,因此这种方法可以为我们节省大量时间。
ROI Pooling example
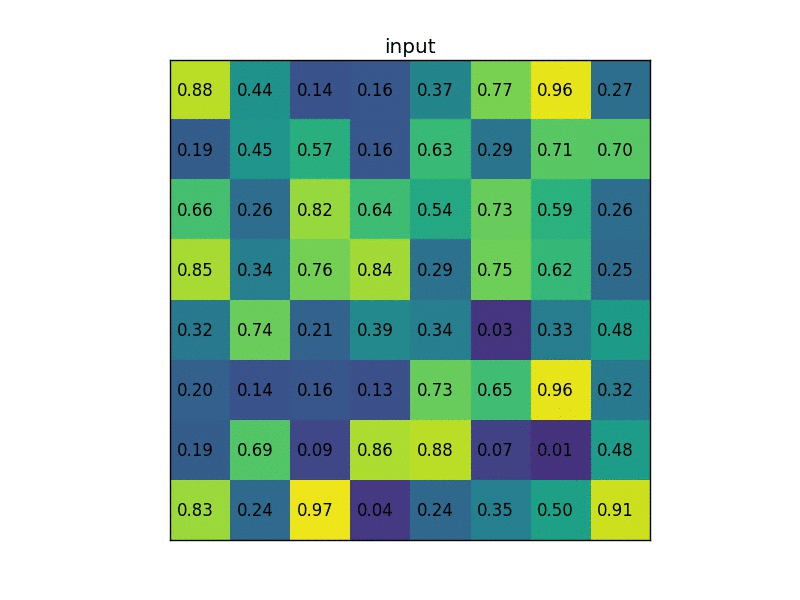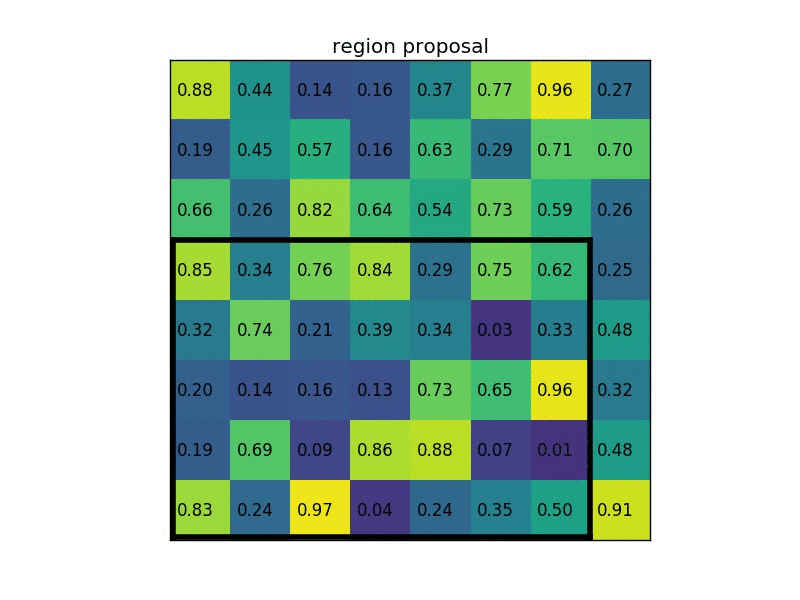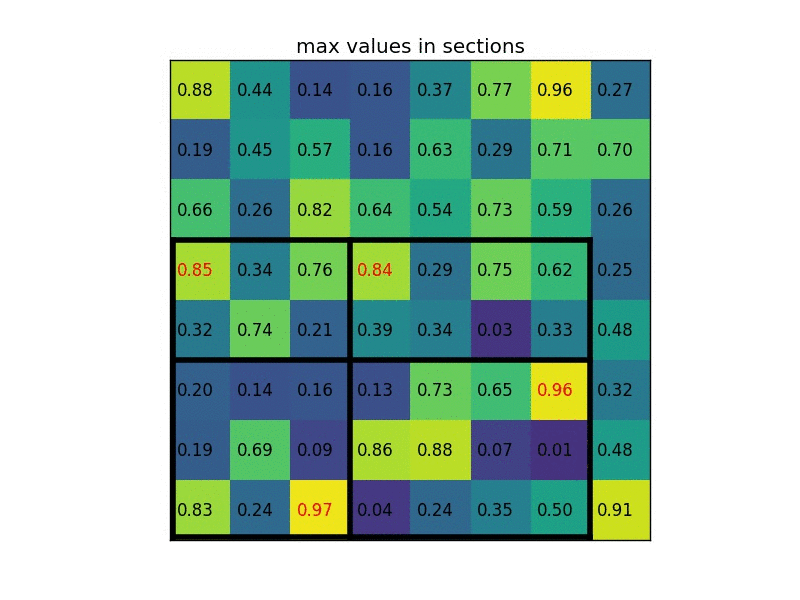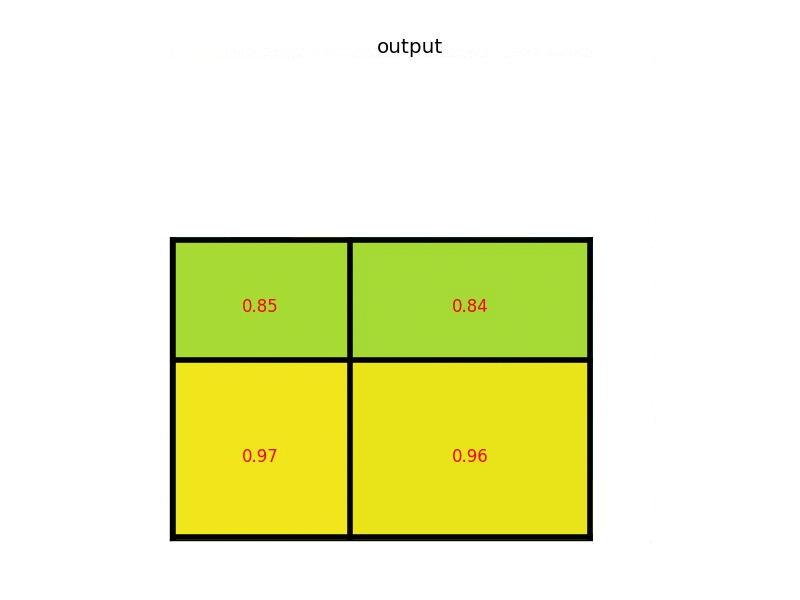
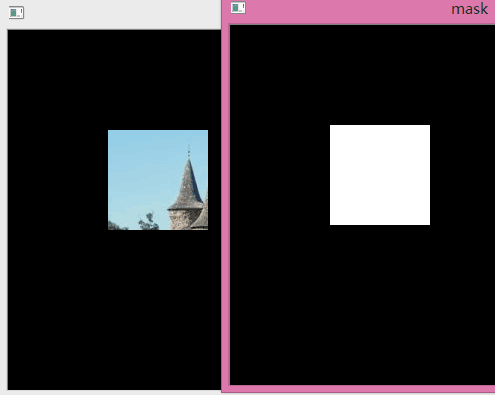
我们将在单个 8×8 特征图、一个感兴趣区域ROI和 2×2 的输出大小上执行ROI Pooling。我们的输入特征图如下所示:

假设我们还有一个region proposal(左上角,右下角坐标):(0, 3), (7, 8)。在图片中它看起来像这样:

通常情况下,每个特征图都会有多个特征图 feature map和多个proposal,该示例保持简单。
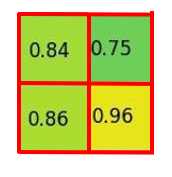
通过将其分成 (2×2) 个部分(因为输出大小为 2×2),我们得到:

请注意,感兴趣区域ROI 的大小不必完全被池化部分的数量整除(在这种情况下,我们的 RoI 是 7×5,我们有 2×2 个池化部分)。
每个部分的最大值是:

这就是感兴趣区域池化层 ROI Pooling的输出。这是我们以漂亮动画形式呈现的示例:
说明:在此案例中region proposals 是5*7大小的,在pooling之后需要得到2*2的,所以在5*7的特征图划分成2*2的时候不是等分的,行是5/2,第一行得到2,剩下的那一行是3,列是7/2,第一列得到3,剩下那一列是4。
关于 RoI Pooling 需要记住的最重要的事情是什么?
- 它用于目标检测任务
- 它允许我们重用来自卷积网络的特征图
- 它可以显着加快训练和测试时间
- 它允许以端到端的方式训练目标检测系统
ROI Pooling局限性
参考faster rcnn中的ROI Pool层,功能是将不同尺寸的ROI区域映射到固定大小的feature map上,具体可实现可参考:Faster rcnn代码理解(4) - outthinker - 博客园
两次量化,分别是:第一次在映射过程中,第二次在池化过程中。
它的缺点:由于两次量化带来的误差;
(1)将候选框边界量化为整数点坐标值。
(2)将量化后的边界区域平均分割成 k*k 个单元(bin),对每一个单元的边界进行量化。

下面我们用直观的例子具体分析一下上述区域不匹配问题。

如图所示,这是一个Faster-RCNN检测框架。
输入一张800*800的图片,图片上有一个665*665的包围框(框着一只狗)。
图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。
接下来需要把框内的特征池化7*7的大小,因此将上述包围框平均分割成7*7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。
经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。

ROI Align理解
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法。



最后,取四个像素值中最大值作为这个小区域(即:2.97*2.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成7*7大小的feature map。
ROI Align从ROI Pooling局限性的源头上进行了改进:取消量化操作,使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如图所示:

- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k*k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment (区域不能对齐) 的问题。
ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
双线性插值法
不需要进行取整操作,如果计算得到小数,也就是没有落到真实的pixel上,那么就用最近的pixel对这一点虚拟pixel进行双线性插值,得到这个“pixel”的值。
具体做法如下图所示:

- 将bbox区域按输出要求的size进行等分,很可能等分后各顶点落不到真实的像素点上
- 在每个bin中再取固定的4个点(作者实验后发现取4效果较好),也就是图二右侧的蓝色点
- 针对每一个蓝点,距离它最近的4个真实像素点的值加权(双线性插值),求得这个蓝点的值
- 一个bin内会算出4个新值,在这些新值中取max,作为这个bin的输出值
- 最后就能得到2x2的输出
它的优点:通过双线性插值避免了量化操作,保存了原始ROI的空间分布,有效避免了误差的产生。
ROI Align的反向传播
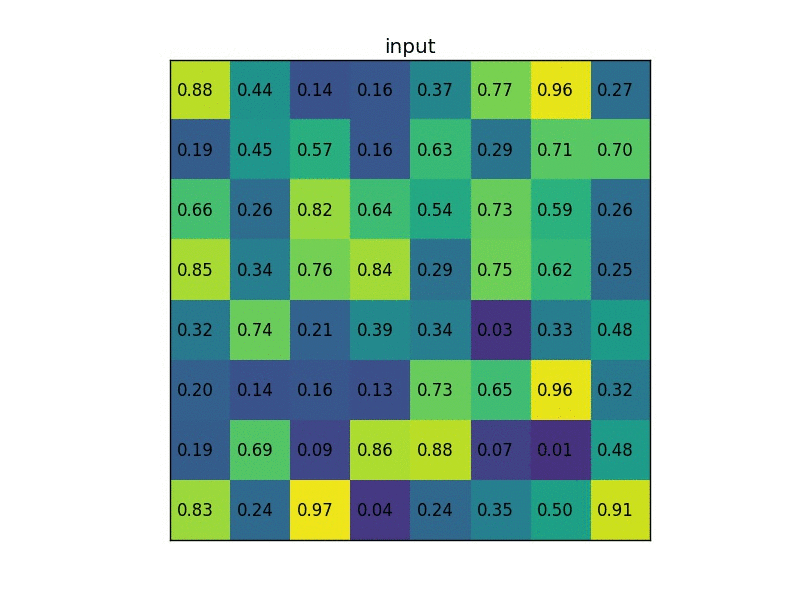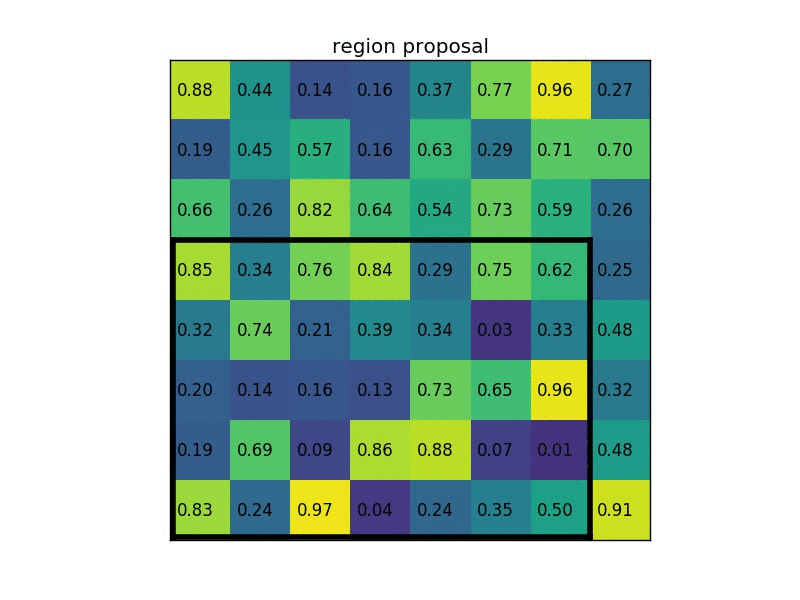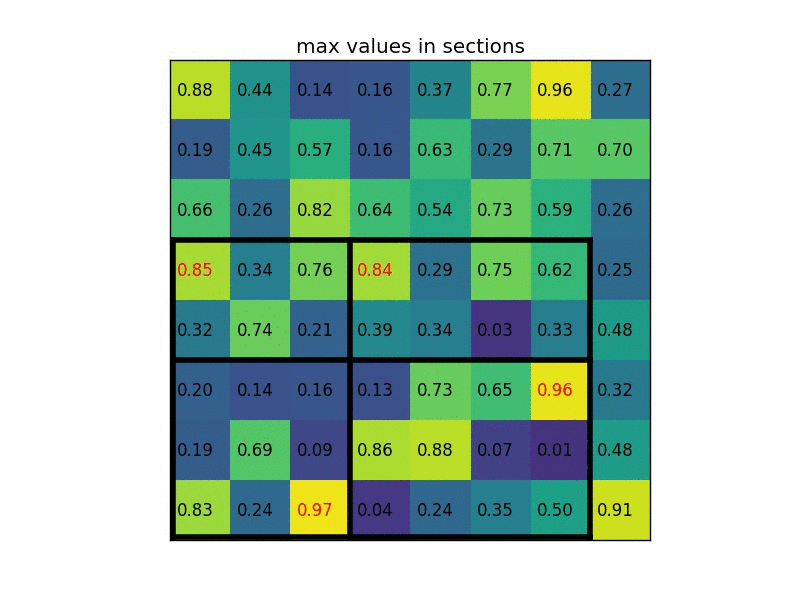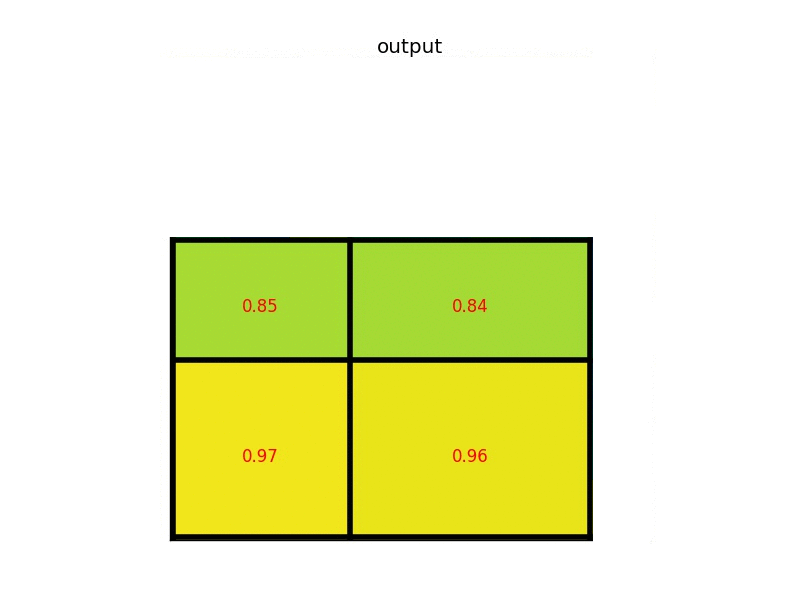
通常,池化方法的反向传播公式如下。

式中,
类比于ROI Pooling,ROI Align的反向传播需要做如下修改:池化后i*(r,j)是一个浮点数坐标,在池化前的特征图中,每一个与i*(r,j)横纵坐标差值小于1的像素点(即双线性插值时特征图上的四个点),都应该接受池化后点

公式中,d(.)表示像素点的距离,Δh和Δw表示
ROI Warp理解
ROI Warp方法是通过论文Instance-aware semantic segmentation via multi-task network cascades引入的。RoIWarp的想法和RoIAlign差不多,唯一的区别是 RoIWarp是将RoI量化到feature map上(量化只发生在第一次映射过程中)。
数据获取/丢失 比较
如果比较从RoIAlign和RoIPooling、RoIWarp的数据丢失/数据获取,应该看到RoIAlign使用来自整个区域来池化数据,而RoIPooling会丢失较多数据,RoIWarp会丢失部分小数据:
绿色意味着用于池化的额外数据。蓝色(深蓝色、天蓝色两种阴影)表示池化是丢失数据。

ROI Warp (下)数据源

再看一下比较结果。
针对实验结果,可以看出ROI Align的分割效果明显好于ROI Pooling 和ROI Warp的效果。
参考博客
https://tjmachinelearning.com/lectures/1718/instance/instance.pdf
Region of interest pooling explained
RoIPooling与RoIAlign的区别 - 蜕变C - 博客园
一文读懂 RoIPooling、RoIAlign 和 RoIWarp_Fast
ROI Align详解 - yumoye - 博客园
ROI Pool和ROI Align - outthinker - 博客园
ROI Pooling和ROI Align - 知乎
详解 ROI Align 的基本原理和实现细节
文中很多内容都源于其他博客,较为详细,都写得较好,不知如何抉择,所以就大部分放上来了,多少也有点缝合的意味了,有点乱乱糟糟的,还望勿怪!!各位看官还请依照目录,选择自己需要的部分看看。