摘要
语音唤醒(KWS,Keyword spotting )实现了基于语音的用户交互,逐渐成为智能设备不可或缺的组成部分。最近,端到端(E2E)方法已经成为设备上KWS任务最流行的方法。然而,目前端到端加密KWS方法的研究和应用还存在一定的差距。在本文中,我们将介绍WeKws,这是一个具有生产质量、易于构建且易于应用的E2E KWS工具包。
WeKws包含了几个最先进的骨干网的实现,使其在三个公开可用的数据集上实现了极具竞争力的结果。为了使WeKws成为一个纯粹的端到端工具包,我们利用了一个细化的max-pooling loss,使模型自己学习关键字的结束位置,这大大简化了训练流程,使WeKws非常高效地应用于现实场景。
代码开源仓库:https://github.com/wenet-e2e/wekws
1、引言
关键字检测(KWS)是从连续音频流中检测预定义关键字的任务。唤醒词检测作为KWS的一项专项任务,已成为智能音箱、手机等物联网设备中典型且不可或缺的组成部分,为用户提供完全免提的语音交互用户体验。WuW(wake-up word )检测系统需要处理流音频,并在物联网设备上本地持久运行。因此,系统应具有较小的内存占用和计算成本,同时保持低延迟(实时响应)和高检测精度。
由于一些具有长期建模能力的神经网络的出现,基于端到端(E2E)的KWS方法最近因其训练/解码的简单性而受到广泛关注。KWS变成关键字/非关键字二进制分类任务。通过模型直接预测不同关键词对应的后验结果。然后,系统可以通过将后验结果与手动定义的关键字阈值进行比较,轻松检测关键字。基于端到端加密的方法比传统方法具有更好的性能。
然而,目前的端到端KWS方法仍存在缺陷。首先,为了训练模型,他们通常需要一个 force-alignment 过程来得到关键词在话语中的起止位置。其次,其中一些依赖于整个输入音频序列来进行决策,因此不适用于流任务。除了目前E2E KWS方法的上述缺点外,在small-footprint KWS领域还缺乏像Wenet这样的开源工具包来弥合研究和生产之间的差距。有几个很好的语音处理工具包,例如Kaldi, Fairseq和Honk,它们已经实现了KWS作为其功能的一部分。然而,它们要么过于复杂,要么在设计中远离实际生产。
在本文中,为了解决上述问题,我们提出了面向产品的轻量级端到端KWS工具包WeKws。WeKws的主要优势如下:
- Alignment-free:WeKws是一个不需要对齐的端到端加密工具包。不需要使用自动语音识别(ASR)或语音活动检测(SAD)系统来获得关键字的对齐或结束时间戳,这大大简化了KWS训练管道。
- Production ready:当我们设计WeKws时,我们尽最大努力弥合研究和生产之间的差距。Wekws使用因果卷积来实现流KWS。WeKws的所有模块都符合TorchScript的要求。因此,使用WeKws训练的模型可以通过Torch Just In Time (JIT)导出,转换为Open Neural Network Exchange 2 (ONNX)格式,因此很容易部署。
- Light weight:WeKws是专门为E2E KWS设计的,代码干净简单,只依赖于PyTorch。经过训练的模型是轻量级的,并且能够在嵌入式设备上运行。
- Competitive results:与最近提出的其他KWS系统相比,WeKws在几个公共KWS基准测试中取得了具有竞争力的结果。此外,WeKws不需要对齐和解码图形,而比较系统则无法做到这一点,这使得它们的训练管道变得复杂,并依赖于其他沉重的工具包。
2、WEKWS
2.1 模型结构
WeKws的整体模型结构如图2所示。它由四个部分组成,从全局倒谱均值和方差归一化(CMVN)层开始,将输入的声学特征归一化为正态分布。然后是线性层,该层将输入要素的尺寸映射到所需的尺寸。然后是主干网络,它可以是递归神经网络(RNN)、时间卷积网络(TCN)或多尺度深度时间卷积(MDTC)。在模型的末尾,有几个二进制分类器,每个二进制分类器都有一个带有S形激活的单一输出节点来预测相应关键字的后验概率。对于每个关键词,我们在主干网络后面增加了一个独立的二进制分类器来处理多个关键词的场景。请注意,主干网络由这些二进制分类器共享。
WeKws当前支持以下三种主干网络:1)RNN或其改进版本LSTM,已广泛应用于语音识别和其他语音任务;2)TCN或其轻量级版本深度可分离TCN(DS-TCN),其扩展卷积以增加接受场;3)MDTC,一个高效提取多尺度特征表示的高级主干网络。注意,当我们的目标是实现流KWS系统时,我们在所有基于卷积的神经网络中使用因果卷积。

2.2 基于训练目标的精细化最大池化
WeKws的训练目标采用精细化的最大池化损失,其公式为:

其中,Pij是预测的后验概率,m是关键词的最小持续时间帧,N是每个训练小批次中第i个发声的帧数。注意,最小持续时间m是对训练集中的所有正样本进行统计计算的。

通过使用最大池化损失,模型自动学习关键字的结束时间戳,从而摆脱了对对齐或关键字结束时间戳的依赖。具体地说,对于正样本,最大池化损失只会优化后验概率最高的帧,而忽略其他帧。对于负样本,最大合并损失将最小化后验概率最高的帧,从而最小化负样本中所有帧的后验概率。
3、实验
3.1 实验设置
本文使用Mobvoi(SLR87)、Snips和Google Speech Command(GSC)语料库来评估提出的WEKWS。Mobvoi是专门为WuW任务设计的普通话语料库。语料库中有两个关键词,每个关键词大约有36K个话语。非关键词话语的数量约为183K。Snips是一个众包的无国界医生语料库。语料库的关键词是“嘿Snips”,语料库中约有11K个关键词话语和86.5K个非关键词话语。GSC语料库由64,721个一秒长的录音组成,这些录音由1881名不同的说话者录制了30个单词。我们使用验证list.txt和测试list.txt中的话语分别作为验证和测试数据,并使用其他话语作为训练数据。
我们使用40维梅尔滤波器组(Fbank)特征作为模型输入,窗口大小为25ms,窗口偏移为10ms。我们使用初始学习率为1E−3、L2权重衰减为1E−4的ADAM作为模型训练的优化器。批次大小被设置为128个话语。提出的WeKws接受了80个epoch的训练。我们从每个时期后保存的总共80个模型中,在开发集上选择30个最好的模型,然后对它们进行平均,得到最终的模型。
3.2 实验结果
- 与最近在GSC数据集上使用的两种KWS方法相比,WeKws获得了最好的结果。

- 最大池化损失不使用任何额外的监督信息,这使得WeKws成为一个简单有效的KWS系统。

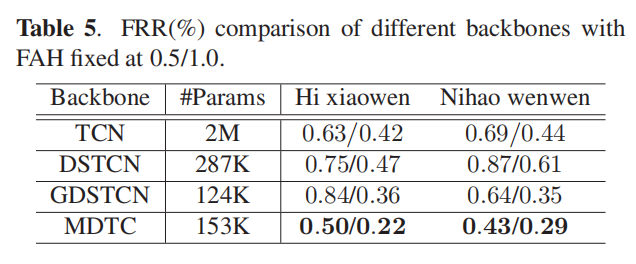
- 从表5中可以看到,深度可分离卷积显著减少了参数的数量,而性能降级很小或没有降级。此外,MDTC在性能和模型占用空间之间实现了最佳平衡。

4、结论
在本文中,提出了一个产品质量高、易于构建、易于应用的开源E2E KWS工具包WeKws。凭借纯粹的端到端训练目标和精心设计的模块,WeKws可以轻松地在不同的平台上进行培训、导出和应用。WeKws有助于弥合KWS方法的研究和生产之间的差距,并为研究人员和工程师提供一个易于使用的平台。对三个KWS基准的评估表明,与许多最先进的KWS方法相比,WeKws取得了与之相当或更好的结果。