最近在学习如何应用API来实现语言交互系统的功能,所以打算写一篇文章来整理和记录自己了解API使用的过程。
有很多平台提供语音识别等功能的API,文章使用的是科大讯飞开发的API。
使用讯飞开放平台SDK实现一个Windows语音交互demo
- 讯飞开放平台简介
- SDK的下载
- Visual Studio工程
- 离线语音识别
- 主函数
- run_asr运行整套流程:
- run_ivw运行唤醒:
- run_asr_mic麦克风语音识别:
- 语法规则:
- 运行效果:
讯飞开放平台简介
本文所使用的资料和基础代码均来自科大讯飞的 讯飞开放平台 和开放平台论坛社区。讯飞开放平台上提供了很多产品和项目解决方案,一些SDK以及基础使用方法。你只需注册一个账号(或进一步实名制来申请更多资源)就可获取一个APPID,就可以在一定的每日免费使用量下完成本文的demo。
讯飞开放平台
讯飞开放平台–论坛社区
SDK的下载
实际上讯飞开放平台提供的SDK会根据你的选中的功能自动生成一个包含你APPID的压缩包,里面会有已经实现你选中功能的例程sample的整个工程:
如果使用语音唤醒需要提前在控制台的页面内设置唤醒词,然后再下载SDK

平台已经提供了相关的文档来支持你跑动所有你可以下载到的例程,并且你的APPID已经设置到相应的文件里,你无需再自行修改(如果出现问题,可参照平台文档内流程设置或重新下载SDK)。本文默认认为你已经了解讯飞开放平台的基本使用方法因此这里就不再过多的提及。
由于文章写的是Windows平台的demo,所以在这里贴一个Windows下的API文档:
MSC for Windows&Linux API
文档里面详尽的提供了API文档应该提供的内容,但是如果之前没有相关经验或者和我一样是那种没有认真写过代码的CS本科生,那么你需要通过一定的实践和认真阅读代码来熟悉和理解。
Visual Studio工程
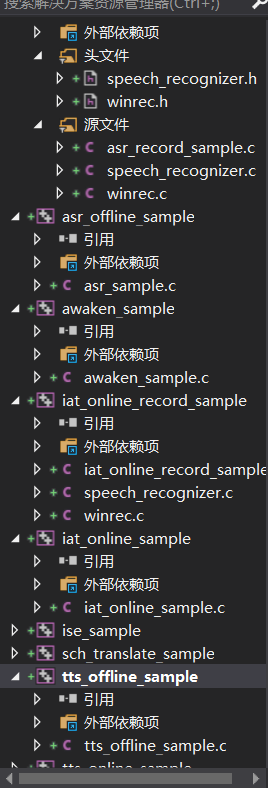
如你所见,压缩包里的工程已经整理好你所选中的所有功能,你可以每一个都把玩一下,看看他们运行起来的样子。这有助于理解API函数运行的逻辑,并给你提供一个设计应用的思路。
如你所见,官方提供的Windows\Linux平台API全部都是C语言编写,如果你要根据具体项目开发使用其他编程语言(或许可以使用WebAPI)。
同时,例程项目都是单独生成的,因此每一个功能的例程都是单独运行的。
离线语音识别
我实现的demo是通过本地离线命令词识别来进行语音识别,讯飞开放平台对这个原理的介绍如下:
语法(命令词)识别,是基于语法规则,将与语法一致的自然语言音频转换为文本输出的技术。语法识别的结果值域只在语法文件所列出的规则里,故有很好的匹配率,另外,语法识别结果携带了结果的置信度,应用可以根据置信分数,决定这个结果是否有效。语法识别多用于要更准确结果且有限说法的语音控制,如空调的语音控制等。在使用语法识别时,应用需要先编写一个语法文件,然后通过调用QISRBuildGrammar接口编译本地语法文件,以及获得语法ID,并在会话时,传入语法ID,以使用该语法。
后面我会在讲语法开发怎么做,首先要把拼凑出来的代码跑通。
主函数
int main(int argc, char* argv[])
{const char *login_config = "appid = 123456789"; //登录参数,这里写你的APPIDUserData asr_data; int ret = 0 ;ret = MSPLogin(NULL, NULL, login_config); //第一个参数为用户名,第二个参数为密码,传NULL即可,第三个参数是登录参数if (MSP_SUCCESS != ret) {printf("登录失败:%d\n", ret);goto exit;}memset(&asr_data, 0, sizeof(UserData));printf("构建离线识别语法网络...\n");ret = build_grammar(&asr_data); //第一次使用某语法进行识别,需要先构建语法网络,获取语法ID,之后使用此语法进行识别,无需再次构建if (MSP_SUCCESS != ret) {printf("构建语法调用失败!\n");goto exit;}while (1 != asr_data.build_fini)_sleep(300);if (MSP_SUCCESS != asr_data.errcode)goto exit;printf("离线识别语法网络构建完成,开始识别...\n"); ret = run_asr(&asr_data); //执行封装好的语音识别函数if (MSP_SUCCESS != ret) {printf("离线语法识别出错: %d \n", ret);goto exit;}printf("请按任意键继续\n");_getch();printf("更新离线语法词典...\n");ret = update_lexicon(&asr_data); //当语法词典槽中的词条需要更新时,调用QISRUpdateLexicon接口完成更新if (MSP_SUCCESS != ret) {printf("更新词典调用失败!\n");goto exit;}while (1 != asr_data.update_fini)_sleep(300);if (MSP_SUCCESS != asr_data.errcode)goto exit;printf("更新离线语法词典完成,开始识别...\n");ret = run_asr(&asr_data);if (MSP_SUCCESS != ret) {printf("离线语法识别出错: %d \n", ret);goto exit;}exit:MSPLogout();printf("请按任意键退出...\n");_getch();return 0;
}
API提供的函数,几乎所有的函数返回值都是通过宏定义的错误码,而这个错误码可以在官方的查询链接里查询:
错误码查询–讯飞开放平台
对于错误码的及时和解决方法都说的比较笼统,如果你跟我一样缺乏相关经验,估计要花时间来猜测分析错误的原因。
run_asr运行整套流程:
int run_asr(UserData *udata)
{char asr_params[MAX_PARAMS_LEN] = {NULL};//离线唤醒的参数设置const char *ssb_param = "ivw_threshold=0:1450,sst=wakeup,ivw_res_path =fo|res/ivw/wakeupresource.jet";const char *rec_rslt = NULL;const char *session_id = NULL;const char *asr_audiof = NULL;FILE *f_pcm = NULL;char *pcm_data = NULL;long pcm_count = 0;long pcm_size = 0;int last_audio = 0;int aud_stat = MSP_AUDIO_SAMPLE_CONTINUE;int ep_status = MSP_EP_LOOKING_FOR_SPEECH;int rec_status = MSP_REC_STATUS_INCOMPLETE;int rss_status = MSP_REC_STATUS_INCOMPLETE;int errcode = -1;int aud_src = 0;const char res[] = "id=\"001\"";//离线语法识别参数设置_snprintf(asr_params, MAX_PARAMS_LEN - 1, "engine_type = local, \asr_res_path = %s, sample_rate = %d, \grm_build_path = %s, local_grammar = %s, \result_type = xml, result_encoding = GB2312,vad_eos=1000 ",ASR_RES_PATH,SAMPLE_RATE_16K,GRM_BUILD_PATH,udata->grammar_id);//printf("音频数据在哪? \n0: 从文件读入\n1:从MIC说话\n");//scanf("%d", &aud_src);//Getid(res);if(1) {while (1) //保持运行{printf("等待唤醒:\n");run_ivw(NULL, ssb_param); //运行唤醒函数SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 12);printf("你好!小恩正在听……\n"); SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 15);run_asr_mic(asr_params); //运行麦克风语音识别}} else {asr_audiof = get_audio_file(); //获取本地录音文件demo_file(asr_audiof, asr_params); //运行本地录音识别}return 0;
}
在原版的例程中是有一个函数是用本地录音进行语音识别,你也可以去掉或者保留用作调试。
唤醒功能的参数设置:
const char *ssb_param = "ivw_threshold=0:1450,\
sst=wakeup,\
ivw_res_path =fo|res/ivw/wakeupresource.jet";
识别功能的参数设置:
_snprintf(asr_params, MAX_PARAMS_LEN - 1, "engine_type = local, \asr_res_path = %s, sample_rate = %d, \grm_build_path = %s, local_grammar = %s, \result_type = xml, result_encoding = GB2312,vad_eos=1000 ",ASR_RES_PATH,SAMPLE_RATE_16K,GRM_BUILD_PATH,udata->grammar_id);
我在这里将engine_type 参数设置为 local,表示我使用的是本地离线识别。
结果类型为XML类型,result_type = xml,结果编码为result_encoding = GB2312。你也可以设置为json或plain,但要注意更改encoding的类型。
这里我增加了允许尾部静音的最长时间这个参数,vad_eos=1000,主要是根据我的需要,默认值为2000。(单位毫秒)
run_ivw运行唤醒:
//======================================================唤醒部分=====================================================
int awkeFlag = 0; //唤醒状态flag,默认0未唤醒,1已换醒
struct recorder *recorder; //初始化录音对象
int record_state = MSP_AUDIO_SAMPLE_FIRST; //初始化录音状态
int ISR_STATUS = 0;//oneshot专用,用来标识命令词识别结果是否已返回。//唤醒状态消息提示,喂给回调函数QIVWRegisterNotify
int cb_ivw_msg_proc(const char *sessionID, int msg, int param1, int param2, const void *info, void *userData)
{if (MSP_IVW_MSG_ERROR == msg) //唤醒出错消息{//printf("\n\nMSP_IVW_MSG_ERROR errCode = %d\n\n", param1);printf("唤醒失败!");awkeFlag = 0;}else if (MSP_IVW_MSG_WAKEUP == msg) //唤醒成功消息{//printf("\n\nMSP_IVW_MSG_WAKEUP result = %s\n\n", info);SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 14);printf("唤醒成功!");SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 15);awkeFlag = 1; }return 0;
}//读取录音内容的函数,用于喂给创建录音的函数create_recorder
static void iat_cb(char *data, unsigned long len, void *user_para)
{int errcode;int ret = 0;const char *session_id = (const char *)user_para;//初始化本次识别的句柄。//printf("进入录音读取");if (len == 0 || data == NULL)return;errcode = QIVWAudioWrite(session_id, (const void *)data, len, record_state);if (MSP_SUCCESS != errcode){printf("QIVWAudioWrite failed! error code:%d\n", errcode);ret = stop_record(recorder);if (ret != 0) {printf("Stop failed! \n");//return -E_SR_RECORDFAIL;}wait_for_rec_stop(recorder, (unsigned int)-1);QIVWAudioWrite(session_id, NULL, 0, MSP_AUDIO_SAMPLE_LAST);record_state = MSP_AUDIO_SAMPLE_LAST;//g_is_awaken_succeed = FALSE;}if (record_state == MSP_AUDIO_SAMPLE_FIRST) {record_state = MSP_AUDIO_SAMPLE_CONTINUE;}
}//运行唤醒的本体
void run_ivw(const char *grammar_list, const char* session_begin_params)//运行唤醒步骤
{const char *session_id = NULL; int err_code = MSP_SUCCESS;WAVEFORMATEX wavfmt = DEFAULT_FORMAT;char sse_hints[128]; //用于设置结束时显示的信息int count = 0;//开始唤醒sessionsession_id = QIVWSessionBegin(grammar_list, session_begin_params, &err_code);if (err_code != MSP_SUCCESS){printf("QIVWSessionBegin failed! error code:%d\n", err_code);goto exit;}err_code = QIVWRegisterNotify(session_id, cb_ivw_msg_proc, NULL); //为避免丢失句柄,回掉函数应当在此调用if (err_code != MSP_SUCCESS){_snprintf(sse_hints, sizeof(sse_hints), "QIVWRegisterNotify errorCode=%d", err_code);printf("QIVWRegisterNotify failed! error code:%d\n", err_code);goto exit;}//开始录音err_code = create_recorder(&recorder, iat_cb, (void*)session_id);err_code = open_recorder(recorder, get_default_input_dev(), &wavfmt);err_code = start_record(recorder);//循环监听,保持录音状态while (record_state != MSP_AUDIO_SAMPLE_LAST){Sleep(200); //阻塞直到唤醒结果出现//printf("正在监听%d\n", record_state);if (awkeFlag == 1){awkeFlag = 0; //恢复标志位方便下次唤醒break; //跳出循环}count++;if (count == 20) //为了防止循环监听时写入到缓存中的数据过大{//先释放当前录音资源stop_record(recorder);close_recorder(recorder);destroy_recorder(recorder);recorder = NULL;//printf("防止音频资源过大,重建\n");//struct recorder *recorder;//重建录音资源err_code = create_recorder(&recorder, iat_cb, (void*)session_id);err_code = open_recorder(recorder, get_default_input_dev(), &wavfmt);err_code = start_record(recorder);count = 0;}}exit:if (recorder) {if (!is_record_stopped(recorder))stop_record(recorder);close_recorder(recorder);destroy_recorder(recorder);recorder = NULL;}if (NULL != session_id){QIVWSessionEnd(session_id, sse_hints); //结束一次唤醒会话}
}QIVWAudioWrite()其实在流程中基本都是在循环调用的:
写入本次唤醒的音频,本接口需要反复调用直到音频写完为止。调用本接口时,推荐用户在写入音频时采取"边录边写"的方式,即每隔一小段时间将采集到的音频通过本接口写入MSC。
得到唤醒结果后,会通过回调注册的函数QIVWRegisterNotify()这样一个异步的机制给你返回结果。
所以QIVWRegisterNotify()函数应当在QIVWSessionBegin()函数执行过后就立即执行。否则会出现丢失句柄的状况。
建议在每执行一个接口后就进行error_code的判断和返回。由于函数的数据传递过程都封装好了,这样可以方便进行调试。
QIVWSessionEnd()主要用于释放这个会话的资源,同时可以给你展示一个你自己定义的结束信息,意味着它正常结束。
当你流程的接口调用方法和顺序不当时,多半会返回这个错误码:

run_asr_mic麦克风语音识别:
static void run_asr_mic(const char* session_begin_params)
{int errcode;int i = 0;HANDLE helper_thread = NULL;struct speech_rec asr;DWORD waitres;char isquit = 0;struct speech_rec_notifier recnotifier = {on_result,on_speech_begin,on_speech_end};errcode = sr_init(&asr, session_begin_params, SR_MIC, DEFAULT_INPUT_DEVID, &recnotifier);if (errcode = sr_start_listening(&asr)) {printf("start listen failed %d\n", errcode);isquit = 1;}//Sleep(3000);if (errcode = sr_stop_listening(&asr)) {printf("stop listening failed %d\n", errcode);isquit = 1;}sr_stop_listening(&asr);sr_uninit(&asr);
}
你可以通过单独建立一个Sleep()延时来设置一个你规定的录音时间,
也可以完全依赖API的VAD机制。
官方例程采用的方式是通过按键开始,按键结束这样一个方法来限定录音的时间。
为了有更好的体验,我在sr_stop_listening()函数中,是用了VAD:
int sr_stop_listening(struct speech_rec *sr)
{int ret = 0;const char * rslt = NULL;char rslt_str[2048] = { '\0' };int count = 0;//如果未开始录音就错误调用了本函数那么返回报错if (sr->state < SR_STATE_STARTED) {sr_dbg("Not started or already stopped.\n");return 0;}while (1) //进程阻塞{if (sr->ep_stat == MSP_EP_AFTER_SPEECH) //VAD检测为音频末尾{break;}}//采用录音参数为NULL,0,MSP_AUDIO_SAMPLE_LASTret = QISRAudioWrite(sr->session_id, NULL, 0, MSP_AUDIO_SAMPLE_LAST, &sr->ep_stat, &sr->rec_stat);if (ret != 0) {sr_dbg("write LAST_SAMPLE failed: %d\n", ret);QISRSessionEnd(sr->session_id, "write err");return ret;}//反复调用结果函数,直至获取结果while (sr->rec_stat != MSP_REC_STATUS_COMPLETE) {rslt = QISRGetResult(sr->session_id, &sr->rec_stat, 0, &ret);if (MSP_SUCCESS != ret) {sr_dbg("\nQISRGetResult failed! error code: %d\n", ret);end_sr_on_error(sr, ret);return ret;}if (NULL != rslt && sr->notif.on_result)sr->notif.on_result(rslt, sr->rec_stat == MSP_REC_STATUS_COMPLETE ? 1 : 0);Sleep(100);}strcat(rslt_str, rslt); //存储结果内容printf(rslt_str); //展示结果Getid(rslt_str); //解析出IDGetRawText(rslt_str); //解析出原文//结束本次录音,释放资源if (sr->aud_src == SR_MIC) {ret = stop_record(sr->recorder);
#ifdef __FILE_SAVE_VERIFY__safe_close_file();
#endifif (ret != 0) {sr_dbg("Stop failed! \n");return -E_SR_RECORDFAIL;}wait_for_rec_stop(sr->recorder, (unsigned int)-1);}sr->state = SR_STATE_INIT;QISRSessionEnd(sr->session_id, "normal");sr->session_id = NULL;return 0;
}
语法规则:
本文使用的是离线命令词识别,官方使用的语法规则是巴克斯范式BNF。
可以在论坛下载pdf文件去系统学习如何定义规则:
语法开发指南
当你是用本地语法规则是,应当将你的BNF文件编辑好,并在代码中指定文件路径:


例程中附带BNF可以给你一个很好范本,作为你“照葫芦画瓢”的对象。
运行效果:

实际上API只会给你返回一个XML的字符串,如果你要解析你需要的信息,可以尝试用一些库去尝试。其中需要注意的是,如果你的部分语法中的词汇没有指定id,那么在xml中会返回一个默认的最大值65535。所以在编制id的时候应当避免编制到65535这个最大的数值,而且尽量在解析的时候滤除65535的关键词。