简单易懂的人脸识别,学不会直接跪倒!
一、人脸识别步骤
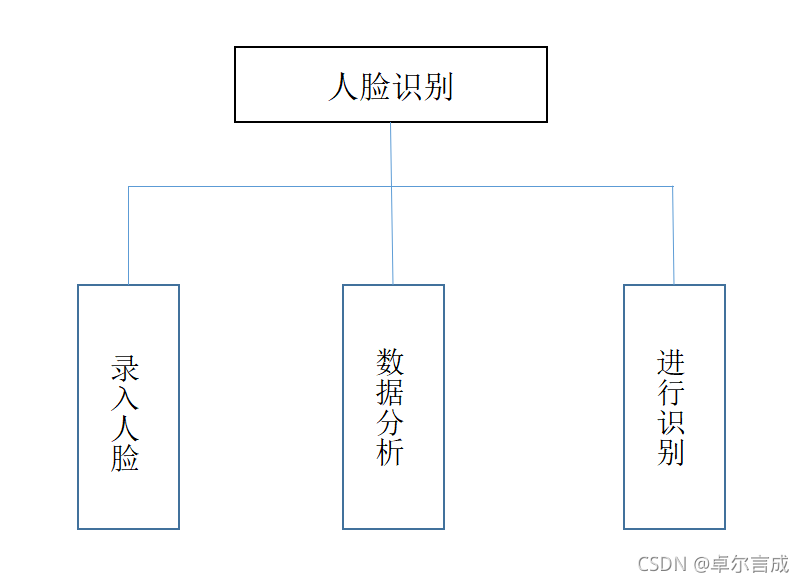
二、直接上代码
(1)录入人脸.py
import cv2face_name = 'cjw' # 该人脸的名字# 加载OpenCV人脸检测分类器
face_cascade = cv2.CascadeClassifier("D:/BaiduNetdiskDownload/python/opencv/opencv-4.5.1/""data/haarcascades/haarcascade_frontalface_default.xml")
recognizer = cv2.face.LBPHFaceRecognizer_create() # 准备好识别方法LBPH方法camera = cv2.VideoCapture(0) # 0:开启摄像头
success, img = camera.read() # 从摄像头读取照片
W_size = 0.1 * camera.get(3) # 在视频流的帧的宽度
H_size = 0.1 * camera.get(4) # 在视频流的帧的高度def get_face():print("正在从摄像头录入新人脸信息 \n")picture_num = 0 # 设置录入照片的初始值while True: # 从摄像头读取图片global success # 设置全局变量global img # 设置全局变量ret, frame = camera.read() # 获得摄像头读取到的数据(ret为返回值,frame为视频中的每一帧)if ret is True:gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转为灰度图片else:breakface_detector = face_cascade # 记录摄像头记录的每一帧的数据,让Classifier判断人脸faces = face_detector.detectMultiScale(gray, 1.3, 5) # gray是要灰度图像,1.3为每次图像尺寸减小的比例,5为minNeighborsfor (x, y, w, h) in faces: # 制造一个矩形框选人脸(xy为左上角的坐标,w为宽,h为高)cv2.rectangle(frame, (x, y), (x + w, y + w), (255, 0, 0))picture_num += 1 # 照片数加一t = face_namecv2.imwrite("./data/1." + str(t) + '.' + str(picture_num) + '.jpg', gray[y:y + h, x:x + w])# 保存图像,将脸部的特征转化为二维数组,保存在data文件夹内maximums_picture = 13 # 设置摄像头拍摄照片的数量的上限if picture_num > maximums_picture:breakcv2.waitKey(1)get_face()
注意:加载分类器的文件地址;cv2.imwrite:保存图片的路径
(2)数据训练.py
import os
import cv2
from PIL import Image
import numpy as npdef getlable(path):facesamples = [] # 储存人脸数据(该数据为二位数组)ids = [] # 储存星门数据imagepaths = [os.path.join(path, f) for f in os.listdir(path)] # 储存图片信息face_detector = cv2.CascadeClassifier('D:/BaiduNetdiskDownload/python/opencv/opencv-4.5.1/data/haarcascades/''haarcascade_frontalface_alt2.xml') # 加载分类器print('数据排列:', imagepaths) # 打印数组imagepathsfor imagePath in imagepaths: # 遍历列表中的图片pil_img = Image.open(imagePath).convert('L')# 打开图片,灰度化,PIL的两种不同模式:# (1)1(黑白,有像素的地方为1,无像素的地方为0)# (2)L(灰度图像,把每个像素点变成0~255的数值,颜色越深值越大)img_numpy = np.array(pil_img, 'uint8') # 将图像转化为数组faces = face_detector.detectMultiScale(img_numpy) # 获取人脸特征id = int(os.path.split(imagePath)[1].split('.')[0]) # 获取每张图片的id和姓名for x, y, w, h in faces: # 预防无面容照片ids.append(id)facesamples.append(img_numpy[y:y+h, x:x+w])# 打印脸部特征和idprint('id:', id)print('fs:', facesamples)return facesamples, idsif __name__ == '__main__':path = 'D:/BaiduNetdiskDownload/python/opencv/pythonProject/face1/data' # 图片路径faces, ids = getlable(path) # 获取图像数组和id标签数组和姓名recognizer = cv2.face.LBPHFaceRecognizer_create() # 获取训练对象recognizer.train(faces, np.array(ids))recognizer.write('trainer/trainer.yml') # 保存生成的人脸特征数据文件(3) 进行识别.py
import cv2
import os# 加载训练数据集文件
recogizer = cv2.face.LBPHFaceRecognizer_create()
recogizer.read('trainer/trainer.yml') # 获取脸部特征数据文件
names = []
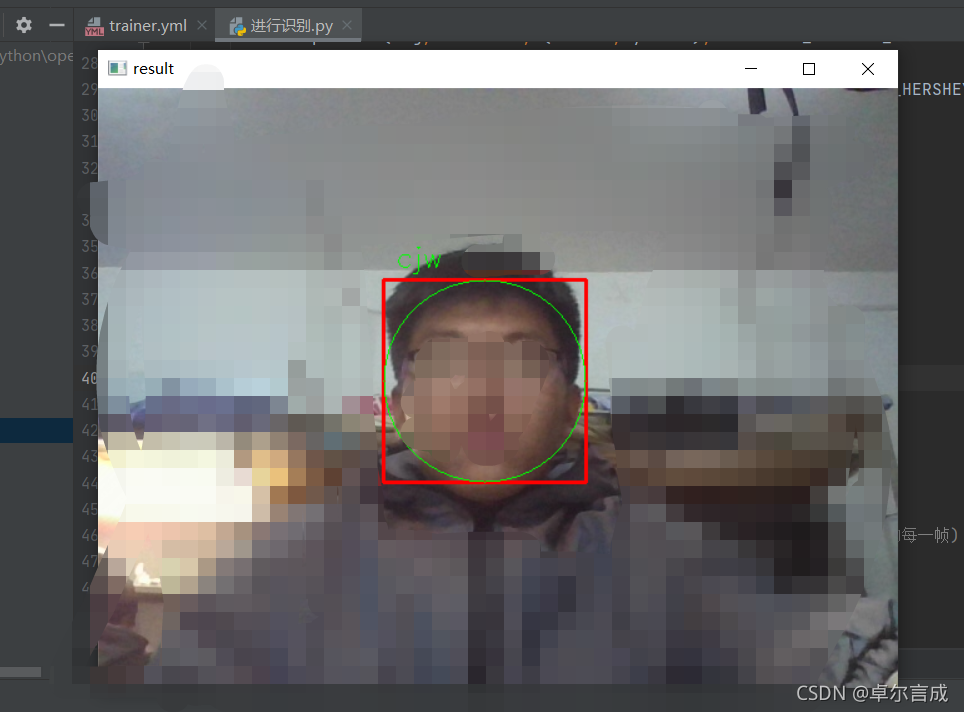
warningtime = 0def face_detect_demo(img):gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图像face_detector = cv2.CascadeClassifier('D:/BaiduNetdiskDownload/python/opencv/opencv-4.5.1/''data/haarcascades/haarcascade_frontalface_default.xml') # 加载分类器face = face_detector.detectMultiScale(gray, 1.3, 5, cv2.CASCADE_SCALE_IMAGE, (100, 100), (300, 300))# 进行识别,把整张人脸部分框起来for x, y, w, h in face:cv2.rectangle(img, (x, y), (x+w, y+h), color=(0, 0, 255), thickness=2) # 矩形cv2.circle(img, center=(x+w//2, y+h//2), radius=w//2, color=(0, 255, 0), thickness=1) # 圆形ids, confidence = recogizer.predict(gray[y:y + h, x:x + w]) # 进行预测、评分if confidence > 80:global warningtimewarningtime += 1if warningtime > 100: # 警报达到一定次数,说明不是这个人warningtime = 0cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)else:cv2.putText(img, str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)# 把姓名打到人脸的框图上cv2.imshow('result', img)# print('bug:',ids)def name():path = 'D:/BaiduNetdiskDownload/python/opencv/pythonProject/face1/data'imagepaths = [os.path.join(path, f) for f in os.listdir(path)]for imagePath in imagepaths:name1 = str(os.path.split(imagePath)[1].split('.', 2)[1])names.append(name1)cap = cv2.VideoCapture('3.mp4')
name()
while True:flag, frame = cap.read() # 获得摄像头读取到的数据(flag为返回值,frame为视频中的每一帧)if not flag:breakface_detect_demo(frame)if ord(' ') == cv2.waitKey(10): # 按空格,退出break
cv2.destroyAllWindows()
cap.release()
# print(names)
三、运行过程及结果
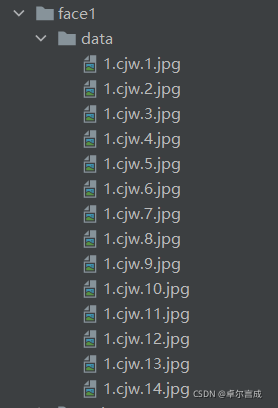
1、获取人脸照片于目标文件中
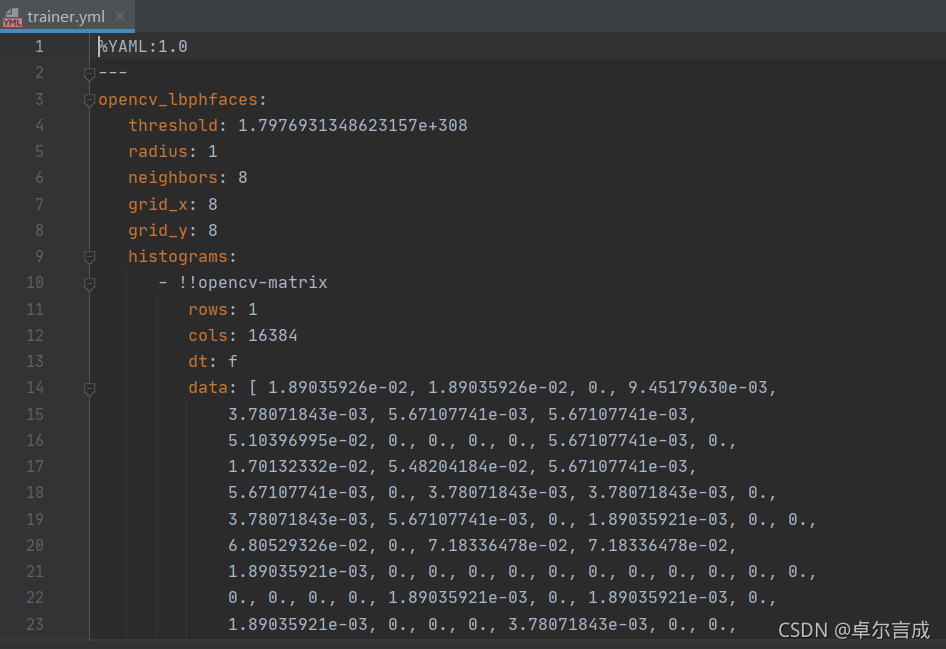
2、进行数据训练,获得trainer.yml文件中的数据
3.进行识别