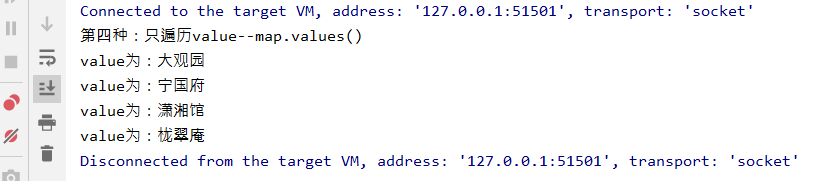
之前在CSDN上看到这篇文章,觉得通俗易懂,写的非常好。不过近来再次查看,发现文章的照片莫名其妙的没有了,没有图就根本看不懂了。找到了之前关注的微信公众号:AI传送门 。
在里面找到了这篇文章,决定再把这篇文章重新整理过来。
导读:卷积神经网络(CNNs)在“自动驾驶”、“人脸识别”、“医疗影像诊断”等领域,都发挥着巨大的作用。这一无比强大的算法,唤起了很多人的好奇心。当阿尔法狗战胜了李世石和柯杰后,人们都在谈论“它”。
但是,
“它”是谁?
“它”是怎样做到的?
已经成为每一个初入人工智能——特别是图像识别领域的朋友,都渴望探究的秘密。
本文通过“算法可视化”的方法,将卷积神经网络的原理,呈献给大家。教程分为上、下两个部分,通篇长度不超过7000字,没有复杂的数学公式,希望你读得畅快。
下面,我们就开始吧!
先提一个小问题:
“你是通过什么了解这个世界的?”
当一辆汽车从你身边疾驰而过,你是通过哪些信息知道那是一辆汽车?
“它的材质,速度,发动机的声响,还是什么?”
你可能说不清所以然,但是当你看到下图时,你会第一时间反应出来,“噢,车! ”
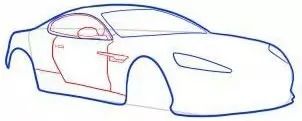
为什么你能猜对它?
“轮廓”!
——对,我给你看了它的轮廓。
再给你一些七七八八、大小不一的图片,你总能猜对一些。
你是怎样做到的?
很简单
你读了一张图片 → 找到了图片的特征 → 进而对图片做出了分类
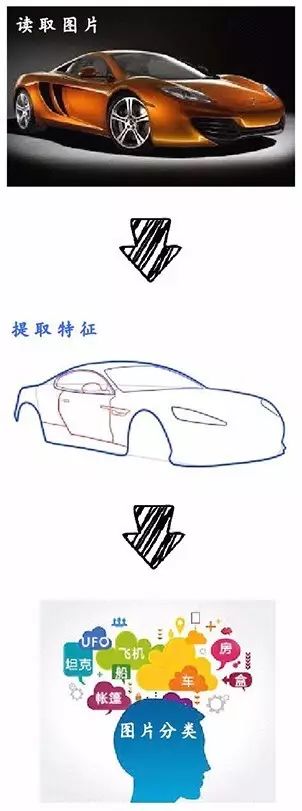
其实,CNNs的工作原理也是这样。
先不考虑那些复杂的专有名词:什么卷积(convolution)、池化(pooling)、过滤器(filter) 等等…… 统统抛到一边。
CNNs做的就是下面3件事:
1. 读取图片;
2. 提取特征;
3. 图片分类。
下面,我们逐一来看各步骤的细节。

如果是一张黑白图片,我们看到的,是这个样子的:

而在计算机的眼里,它看到的,是这个样子的:

好没有情趣……

这些数字是哪里来的?
因为图片是由一个又一个的像素点构成。(当你将图片无限放大,你能看到那些像素点)

而每一个像素点,都是由一个0~255的数字组成。

所以,在计算机“看”来,一张图片,就是一个又一个的数字。

所以,我们第一步的工作,是将左上图的那只小狗,转换成右上图的那一行行数字。
幸运的是,目前在python中,很多第三方库,诸如PIL/Matplotlib等,都可以实现这种转换,我们需要了解的是,后面的所有运算过程,都是基于右上图来完成的,至于具体的转换过程,不需要我们费心来做。

在文章开篇的例子中,我们知道,在识别一辆汽车的时候,可以将它的轮廓提取出来,从而判断出那是一辆车。
同样的,CNNs在识别图片时,也需要提取图像的特征。
在CNNs中,完成这一工作的小伙叫“卷积”。(希望你不要纠结这个极具个性的名字,懂得它的原理就OK)
“卷积”在每次工作时,手里都会握着几把“过滤器”。

过滤器的作用是:寻找图片的特征。
仍以小狗为例,过滤器会在图片上从头到尾“滑过”一遍

每滑到一个地方,就将该地方的图像特征提取出来。
那它是怎样提取的呢?
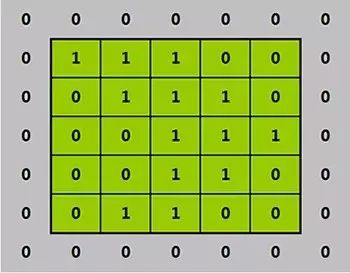
别忘了,在计算机的眼里,世界是这个样子的:
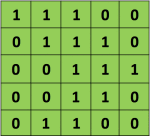
(为了简化问题,这里将像素值仅用0和1表示)
假设过滤器是这个样子的:
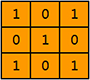
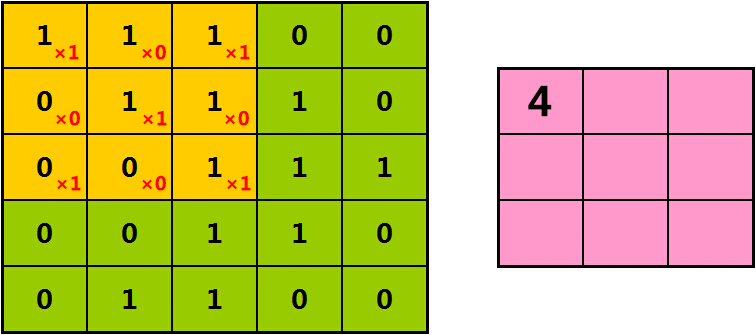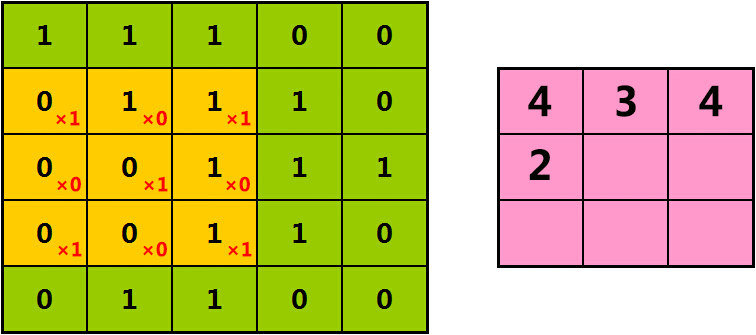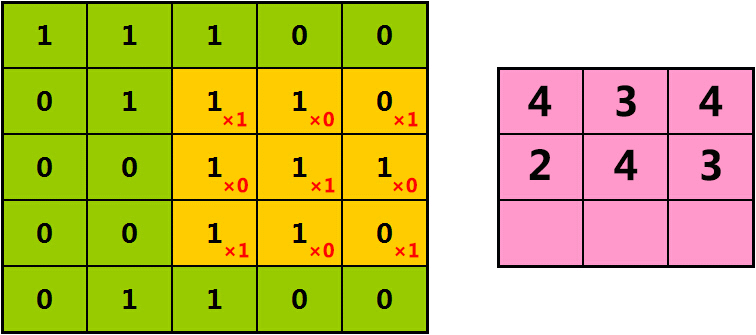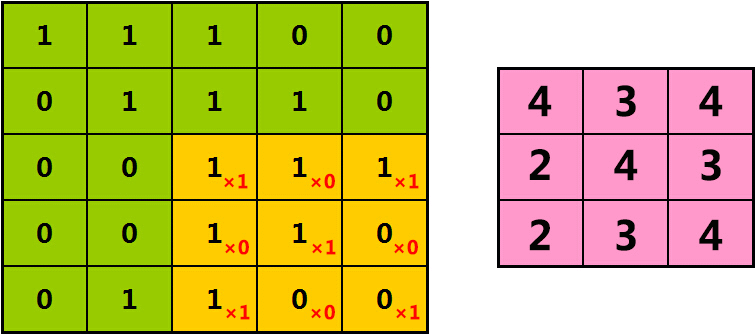
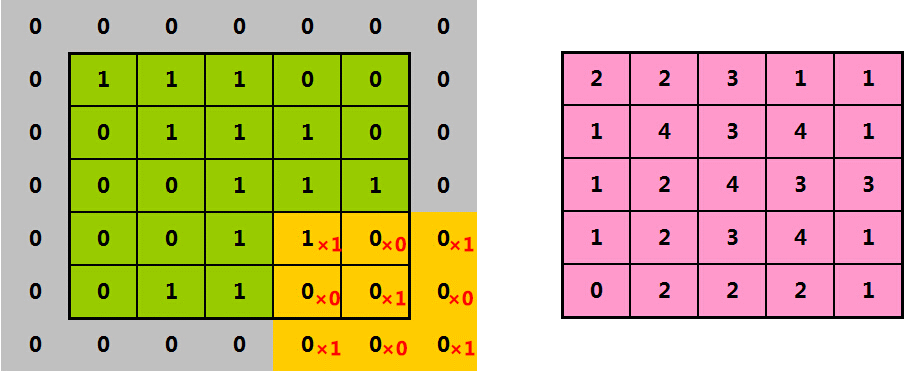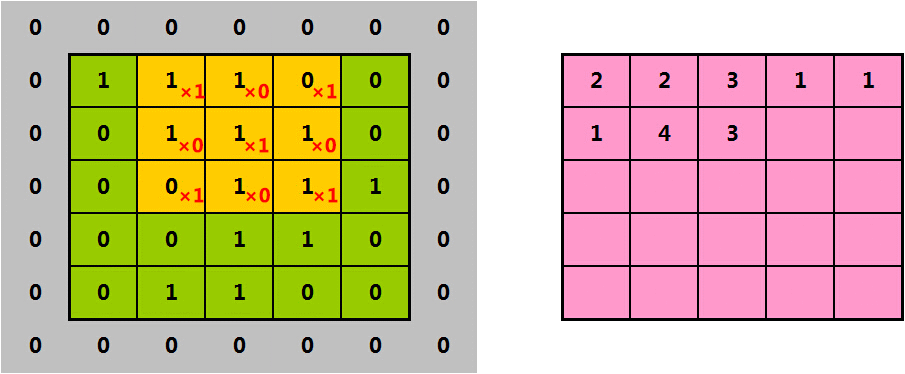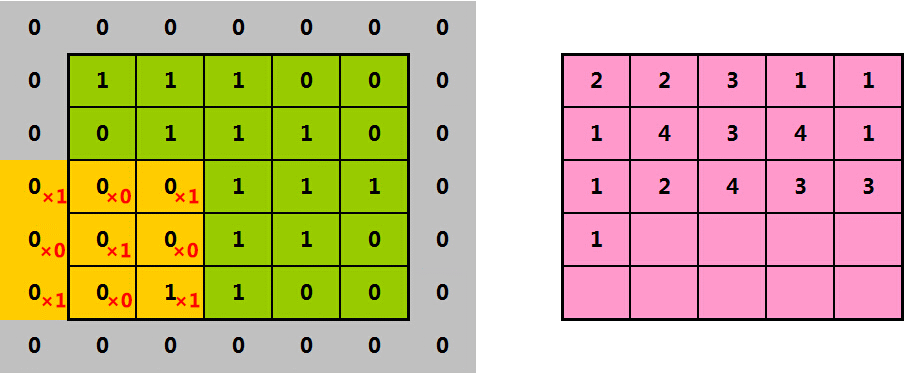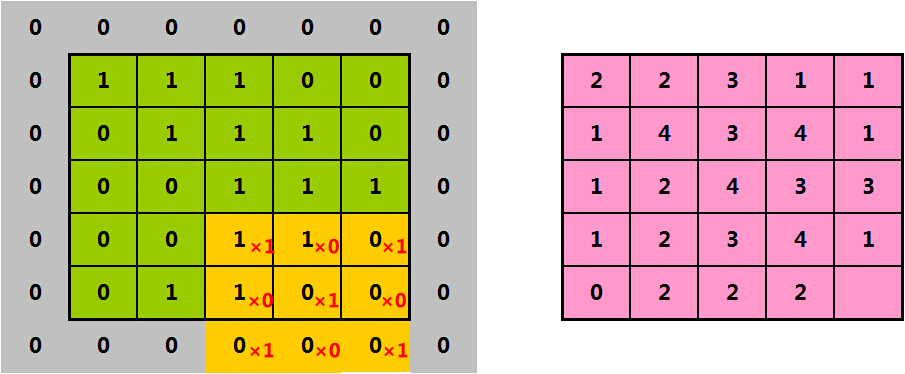
当橘色的过滤器在绿色矩形框中,缓慢滑过时,
我们用橘色过滤器中的每一个值,与绿色矩形框中的对应值相乘、再相加
有点儿拗口,直接看图:
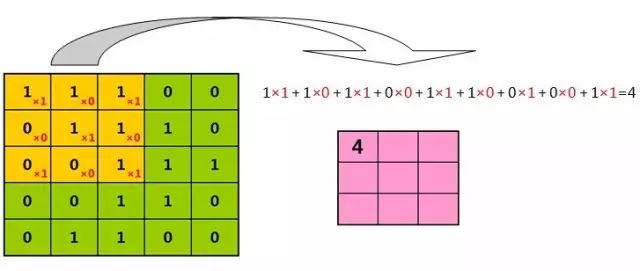
(点击图片,查看大图)
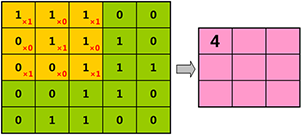
结果“4”,就是我们从第一个橘色方框中,提取出的特征。
如果我们每次将橘色过滤器,向右、向下移动1格,则提取出的特征为:
你可能会问:
我知道绿色矩阵代表一张图片,是计算机“眼中”图片的样子。
但是,
经过橘色过滤器提取特征后,得到的粉色矩阵,那是什么?

我们从人类的视角,再重新审视一遍。
这次,我们回到之前的例子中。
仍以这张萌狗为例,它经过“过滤器”提取特征后,得到的是一张……哦,好吧……看起来有点儿模糊的图。
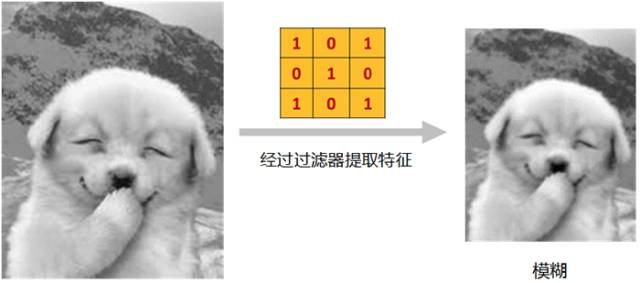
(点击图片,查看大图)
虽然图片模糊了,但是图片中的主要特征,已经被过滤器全部提取出来,单凭这么一张模糊的图,作为人类的我们,足以对它做出判断了。(谁敢说它是一只猫?!)
下面,我们再换几个过滤器试试。

(点击图片,查看大图)
这些就是经过过滤器提取后,得到的不同“特征图片”。
由此我们可以看出,采用不同的“过滤器”,能够提取出不同的图片特征。
你可能又会问:
那过滤器里的数值,该如何确定呢?
这就涉及到CNNs要做的工作了。每一个过滤器中的数值,都是算法自己学习来的,不需要我们费心去设置。
需要我们做的有:
① 设置过滤器的大小(用字母“F”表示)
上例中,我们的过滤器大小是3×3,即F=3。
当然,你还可以设置成5×5,都是可以的。
只不过,需要注意的是:过滤器的尺寸越大,得到的图像细节就越少,最终得到的特征图的尺寸也更小。
② 设置过滤器滑动的步幅数(用字母“S”表示)
上例中,过滤器滑动的步幅是1,即每次过滤器向右或向下滑动1个像素单位。
当然,你也可以将步幅设置为2或更多,但是通常情况下,我们会使用S=1或S=2。
③ 设置过滤器的个数(用字母“K”表示)
上例中,我们分别给大家展示了4种过滤器。所以你可以理解为K=4,如下图:
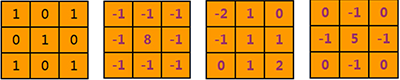
当然,你可以设置任意个数。
再次强调:不要在意过滤器里面的数值,那是算法自己学习来的,不需要我们操心,我们只要把过滤器的个数设置好,就可以了。
所以,一张图片,在经过4种过滤器的提取后,会得到4种不同的特征图片:
![]()
实际上,这就是“卷积”小伙儿所做的工作。
从上面的例子我们能够看到,“卷积”输出的结果,是包含“宽、高、深”3个维度的:

实际上,在CNNs中,所有图片都是包含有“宽、高、深”。
像输入的图片——萌狗,它也是包含3个维度,只不过,它的深度是1,所以在我们的图片中没有明显地体现出来:

所以,我们要记住,经过“卷积”层的处理后,图片含有深度,这个“深度”,等于过滤器的个数。
例如,上面我们采用了4种过滤器,那么,输出的结果,深度就为4。
④ 设置是否补零(用字母“P”表示)
何为“补零”?
上面的例子中,我们采用了3×3大小的过滤器,直接在原始图片滑过。
从结果中可以看到,最终得到的“特征图片”比“原始图片”小了一圈:
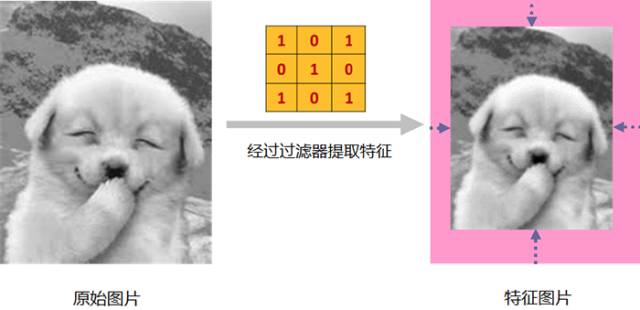
为什么会出现这种情况?
原因很简单:过滤器将原始图片中,每3*3=9个像素点,提取为1个像素点
所以,当过滤器遍历整个图片后,得到的特征图片会比原始图片更小。
当然,你也可以得到一个和原始图片大小一样的特征图,这就需要采用“在原始图片外围补零”的方法:
下面,我们来看看“补零”后的效果:
从图中可以看到,当我们在原始图片外围补上1圈零后,得到的特征图大小和原始图一样,都是5*5。
你可能会问:
如何确定“补零”的圈数,才能保证图片大小一致?
假设你的过滤器大小为F,滑动步幅S=1,想要实现这一目标,补零的个数应为:
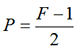
举个例子:
在上图中,因为我们使用的是3*3大小的过滤器,而且每次滑动时,都是向右或向下移动1格。
所以,为了使特征图片与原始图片保持一致,需要补零P=(3-1)/2=1,即在原始图片外围,补1圈零。
如果你使用的过滤器大小为5*5,那么补零P=(5-1)/2=2,即在原始图片外围,补2圈零。
当然,是否需要“补零”,由你自己来决定,“补零”并不是硬性规定。
 温馨提示:
温馨提示:
假设原始图片的大小为W,当我们设置了
过滤器的大小(F)、滑动的步幅数(S)、以及补零的圈数(P)
实际上,得到的特征图片大小为:
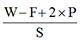
所以,当我们设置这些超参数时,需要遵循一个原则,即“上面公式得到的结果,必须为一个整数”:

恭喜你!
看到这里,CNNs中最难的部分我们已经学习完了。
下面,我们会学习“非线性计算”和“池化”。
但它们都很简单,深呼吸,下节课我们继续……
(整理)吊炸天的CNNs,这是我见过最详尽的图解!(下)
原文在微信公众号:AI传送门