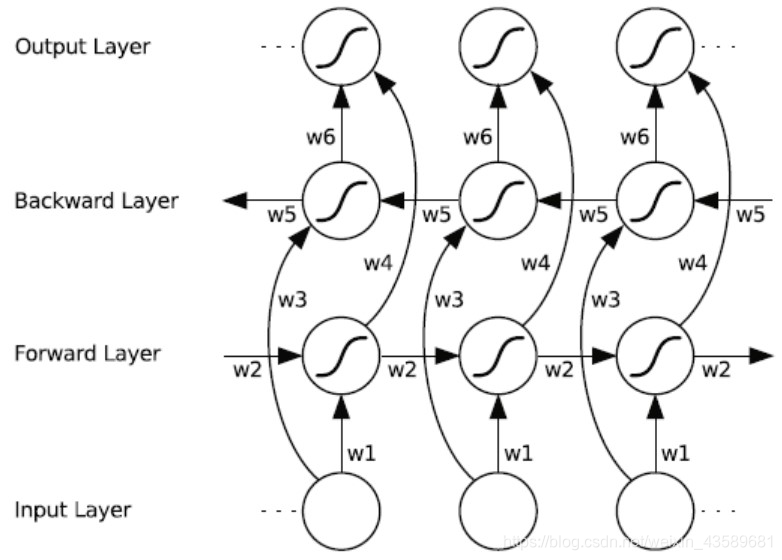
参考:https://www.cnblogs.com/chay/articles/10745417.html
https://www.cnblogs.com/xiaosongshine/p/10557891.html
1.Holdout检验
Holdout 检验是最简单也是最直接的验证方法, 它将原始的样本集合随机划分成训练集和验证集两部分。 比方说, 我们把样本按照70%~30% 的比例分成两部分, 70% 的样本用于模型训练; 30% 的样本用于模型验证, 包括绘制ROC曲线、 计算精确率和召回率等指标来评估模型性能。
Holdout 检验的缺点很明显, 即在验证集上计算出来的最后评估指标与原始分组有很大关系。 为了消除随机性, 研究者们引入了“交叉检验”的思想。
2.K-fold
在机器学习建模过程中,通行的做法通常是将数据分为训练集和测试集。测试集是与训练独立的数据,完全不参与训练,用于最终模型的评估。在训练过程中,经常会出现过拟合的问题,就是模型可以很好的匹配训练数据,却不能很好在预测训练集外的数据。如果此时就使用测试数据来调整模型参数,就相当于在训练时已知部分测试数据的信息,会影响最终评估结果的准确性。通常的做法是在训练数据再中分出一部分做为验证(Validation)数据,用来评估模型的训练效果。
验证数据取自训练数据,但不参与训练,这样可以相对客观的评估模型对于训练集之外数据的匹配程度。模型在验证数据中的评估常用的是交叉验证,又称循环验证。它将原始数据分成K组(K-Fold),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型。这K个模型分别在验证集中评估结果,最后的误差MSE(Mean Squared Error)加和平均就得到交叉验证误差。交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现,可以做为模型优化的指标使用。
疑问:为什么不直接拆分训练集与数据集,来验证模型性能,反而采用多次划分的形式,岂不是太麻烦了?
我们为了防止在训练过程中,出现过拟合的问题,通行的做法通常是将数据分为训练集和测试集。测试集是与训练独立的数据,完全不参与训练,用于最终模型的评估。这样的直接划分会导致一个问题就是测试集不会参与训练,这样在小的数据集上会浪费掉这部分数据,无法使模型达到最优(数据决定了程性能上限,模型与算法会逼近这个上限)。但是我们又不能划分测试集,因为需要验证网络泛化性能。采用K-Fold 多次划分的形式就可以利用全部数据集。最后采用平均的方法合理表示模型性能。
3.bootstrap随机抽样,也叫自助法
不管是Holdout检验还是交叉检验, 都是基于划分训练集和测试集的方法进行模型评估的。 然而, 当样本规模比较小时, 将样本集进行划分会让训练集进一步减小, 这可能会影响模型训练效果。
自助法是基于自助采样法的检验方法。 对于总数为n的样本集合, 进行n次有放回的随机抽样, 得到大小为n的训练集。 n次采样过程中, 有的样本会被重复采样, 有的样本没有被抽出过, 将这些没有被抽出的样本作为验证集, 进行模型验证, 这就是自助法的验证过程。
**在自助法的采样过程中, 对n个样本进行n次自助抽样, 当n趋于无穷大时,最终有多少数据从未被选择过? **

上图的极限定理写错了,真实为 n->无穷,(1+1/n)^n=e