在构建一个机器学习模型之后,我们需要对模型的性能进行评估。如果一个模型过于简单,就会导致欠拟合(高偏差)问题,如果模型过于复杂,就会导致过拟合(高方差)问题。为了使模型能够在欠拟合和过拟合之间找到一个折中方案,我们需要对模型进行评估,后面将会介绍holdout交叉验证和k折交叉验证,通过这两种方法,我们可以获得一个模型泛化误差的可靠估计,也就是模型在新数据上的性能。
一、holdout交叉验证
holdout交叉验证(holdout cross-validation)是评估机器学习模型泛化能力一种常用的方法。holdout方法是将数据集划分为训练集和测试集,训练集用于训练模型,测试集用于评估模型的性能。
但是,如果我们在模型选中过程中不断的重复使用相同的测试数据,其实就可以将测试数据看作训练数据的一部分,从而导致模型的过拟合。在使用holdout交叉验证的时候,有一种更好的方法可以避免过拟合,将数据集分为三个部分:训练集、测试集和验证集。训练集用于不同模型的拟合,模型在验证集上的表现作为模型性能的评估和选择标准,测试集是当模型的参数优化完成之后,再用来评估模型的泛化误差。
holdout方法的缺点:模型性能的评估对于训练集和验证集的划分是敏感的,评价的结果会随着样本的不同而发生变化。接下来将介绍一种鲁棒性更高的性能评价技术:k折交叉验证。
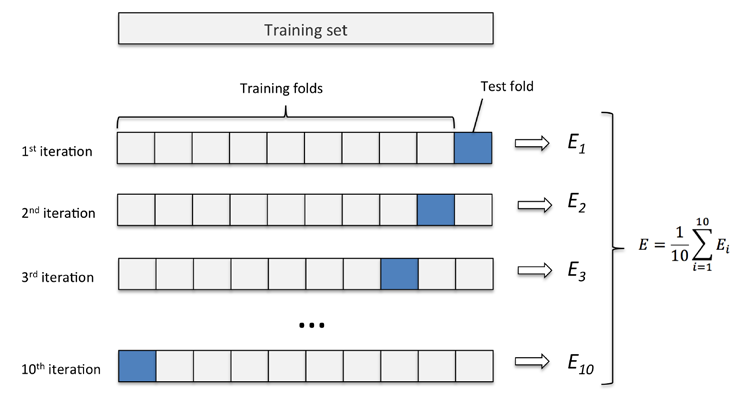
二、k折交叉验证
k折交叉验证(k-fold cross-validation),不重复的将训练集划分为k个,