模型评估(Model Evaluation)
1.测试集(testing set)
- 测试集(testing set): 通常,我们可通过实验测验来对学习器的泛化误差进行评估并进而做出选择,为此,需要一个“测试集”来测试学习器对新样本的判别能力。然后以测试集上的“测试误差”(testing error)作为泛化误差的近似。
- 通常我们假设测试样本也是从样本真实分布中独立同分布采样而得到。但需要注意的是,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现,未在训练过程中使用过。
- 训练集用于模型的训练,而测试集用于评估模型的性能。(即模型的泛化能力)一般来说,训练模型时,测试集从头到尾都不会参加模型的训练。
注:我们只在模型的参数调整好了,整个模型训练好了之后在测试集上进行评估测试模型的近似泛化误差以及性能。 在训练过程中我们还要对模型进行选择和参数(超参数)调优,如果在模型选择的过程中,我们始终用测试集来评价模型性能进行参数调优,这实际上也将测试集变相地转为了训练集,这时候选择的最优模型很可能是过拟合的。所以我们要引入一个验证集(validation set)其作用是在训练的过程中进行模型选择和参数(超参数)调优,减缓训练时的过拟合。
模型选择(Model Selection)
注:有资料把选择参数这一步称为模型选择,也有不少资料把选择何种模型算法称为模型选择。
- 参数(超参数(hyper parameters))选择:: 在训练模型这一步,我们非常关心如何选择参数来提高模型的预测能力,因为对于同一种机器学习算法,如果选择不同的参数(超参数),模型的性能会有很大差别。
1.验证集(validation set)
- 验证集(validation set): 模型评估与选择中用于评估测试的数据集(基于验证集上的性能来进行模型选择和调参)常称为“验证集”
- 测试集(testing set)和验证集(validation set)的比较和区别

机器学习大致过程
- 有了模型评估(Model Evaluation)和模型选择(Model Selection)以及训练集(training set)、验证集(validation set)、测试集(testing set)的概念,可以大致归纳出机器学习的过程步骤:
- 将整个数据集按照正确的划分方式划分成训练集、验证集、测试集。
- 选取一个模型选择方法(如Hold-out Method),首先确定一个学习算法,然后确定模型的超参数集。
- 将模型用于训练集上训练,确定模型函数中的参数集。
- 将此时完整的模型用于验证集上进行性能评估。
- 重复2、3、4步骤,根据在验证集上的性能评估结果,得到效果最好的学习算法以及确定了其模型的超参数集。
- 此时,模型选择(Model Selection)已经完成,确定了最优的学习算法以及其超参数组合,把训练集和验证集合并,然后把模型置于合并后的训练集上训练,确定模型中的函数等参数,得到最优函数。
- 把训练好的模型用于测试集上进行模型评估(Model Evaluation)。
- 在整个数据集上训练最终模型,得到一个在未见数据集或未来数据集上能够更好地泛化的模型。
Hold-out Method(留出法)
- 注: Hold-out Method是将整个数据集仅分出一部分作为训练集训练模型,另外的部分作为验证集和测试集,当在模型评估时我们用训练集训练,测试集来评估;而当用留出法做模型选择时,我们用训练集训练,验证集来调整参数(超参数)或者选择算法模型。(下面是有关Hold-out Method在模型评估(Model Evaluation)和模型选择(Model Selection)中的详细用法)
1.Hold-out Method for Model Evaluation(Hold-out Method用于模型评估)
- 留出法(Hold-out Method): 直接将数据集D划分成两个互斥的集合,其中一个为训练集S,另一个作为测试集T,这称为“留出法”。
- 需注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响,若S,T中样本类别比例差别很大,则误差估计将由于训练/测试数据分布的差异产生偏差。
- 分层采样(stratified sampling): 在对数据集进行划分的时候,保留类别比例的采样方式称为“分层采样”。若对数据集D(包含500个正例,500个反例)则分层采样的到的训练集S(70%)应为350个正例,350个反例,测试集(30%)应为150个正例,150个反例。
- 一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
- 划分比例: 若训练集S包含大多数样本则模型可能更接近于用整个数据集D训练出的样本,而因为测试集T太小,评估结果会不稳定不准确。反之,若测试集T很大,则训练集S训练出来的模型丧失了真实性。常见的做法是将大约2/3 ~ 4/5的样本用于训练,剩余样本呢用于测试。

- 用Hold-out Method在模型评估时的步骤:
- 将数据集分为训练集和测试集两部分(一般的比例时70-30%)
- 在训练集上训练模型,在训练之前要选择固定的一些模型超参数设置。
- 把训练好的模型在测试集上评估(测试)
- 在整个数据集上训练最终模型,得到一个在未见数据集或未来数据集上能够更好地泛化的模型。
注:此过程用于基于将数据集分割为训练数据集和测试数据集并使用固定的超参数集的模型评估。下面阐述的就是确定模型的超参数。
2.Hold-out method for Model Selection(Hold-out Method用于模型选择)
Hold-out Method也可用于模型选择或超参数调谐 。事实上,有时模型选择过程被称为超参数调优。在模型选择的hold-out方法中,将数据集分为训练集(training set)、验证集(validation set)和测试集(testing set)。如下图:

- 用Hold-out Method在模型选择时的步骤:
- 把数据集分成训练集、验证集和测试集。
- 训练不同的模型用不同的机器学习算法(如logistic regression, random forest, XGBoost)。
- 对于用不同算法训练的模型,调整超参数,得到不同的模型。对于步骤2中提到的每个算法,改变超参数设置,并配备多个模型。
- 在验证集上测试每个模型(属于每个算法)的性能。
- 从验证数据集中测试的模型中选择最优的模型。对于特定的算法,最优模型将具有最优的超参数设置。
- 在测试数据集中测试最优模型的性能。
用Hold-out Method的整个训练的过程如下图:

Cross-Validation(交叉验证)/ k-fold Cross-Validation(K折交叉验证) & Nested Cross-Validation(嵌套交叉验证)
1.k-fold Cross—Validation for Model Evaluation(k-fold Cross-Validation用于模型评估)

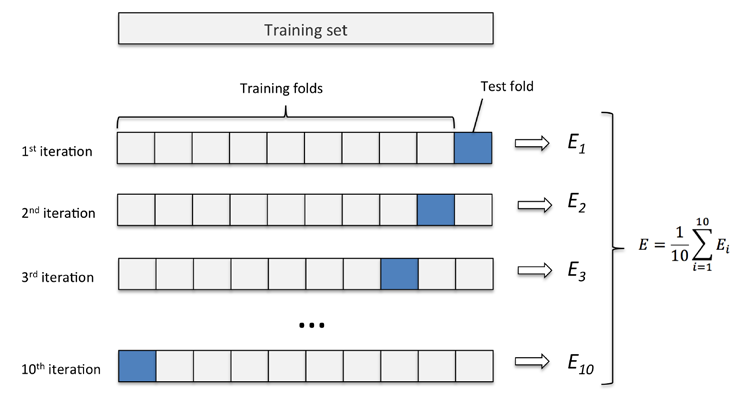
- 交叉验证法(cross validation)/k折交叉验证(k-fold cross validation):将数据集D划分成k个大小相似的互斥子集,每个子集Di都尽量保持数据分布的一致性,即从D中通过分层采样得到,然后每次用k - 1个子集的并集作为训练集,余下的那个自己作为测试集,这样可以获得k组训练/测试集,从而进行k次训练测试,最终结果为k次训练测试的均值,这称为“k交叉折验证法”
- 与留出法相似,将数据集划分为k个子集有多种划分方式,为了减小样本划分不同而引入的差别,k折交叉验证通常要随机使用不同的划分重复p次,最终的结果是这p次k折交叉验证结果的均值。例如有10折10折交叉验证。

2.k-fold Cross-Validation for Model Selection(k-fold Cross-Validation用于模型选择)
和在Hold-out Method中讲述的一样,对于一个模型我们在训练的时候需要参数调优,那么k-fold Cross-Validation 也是一种很好的参数调优方法,在上述k-fold Cross-Validation用于模型评估的基础上,进一步对训练集进行划分成k(此处的k未必要等于模型评估时的k)个大小相似的互斥子集,每次用k - 1个子集用于训练,一个作为验证集,这样得到k组训练/验证集,从而进行k次训练验证,根据结果模型选择和进行超参数调整。

3.Nested Cross Validation(嵌套交叉验证)
根据上述的k-fold Cross-Validation在模型评估和模型选择的用法,可以在学习中嵌套使用两者。如下图所示:

- 上述图片中训练模型采用内环使用2-fold cross-validation(2折交叉验证)选取最优模型和超参数后,外环使用5-fold cross-validation(5折交叉验证)的方法得到近似的泛化误差来评估模型的性能。我们把这称为nested 5×2 cross-validation(嵌套5 * 2交叉验证)。
- 注:文章hold-out Method以及k-fold Cross-Validation参考于以下文章: (以下链接内容为英文但是讲述的很到位,建议阅读)
- Hold-out Method for Training Machine Learning Models
- K-Fold Cross Validation – Python Example
- Python – Nested Cross Validation for Algorithm Selection
截取自我的另一篇博客:机器学习中理解过拟合,训练集、验证集、测试集,模型评估、模型选择,Hold-out Method(留出法)K-fold Cross-Validation(k折交叉验证法)
其他有关机器学习的博客文章:
- 机器学习中理解过拟合,训练集、验证集、测试集,模型评估、模型选择,Hold-out Method(留出法)K-fold Cross-Validation(k折交叉验证法)
- 深入理解Precision(查准率)、Recall(查全率/召回率)、F1-Score、P-R曲线和micro和macro方法,以及多分类问题P-R曲线
- 深入理解ROC曲线的定义以及绘制ROC曲线过程,其与模型性能的关系,以及AUC
- 决策树、理解信息熵、信息增益(ID3)、增益率(C4.5)、基尼指数(CART)、预剪枝、后剪枝、多变量决策树
- 线性模型——最小二乘法,梯度下降,线性回归,logistic回归