cross-validation:从 holdout validation 到 k-fold validation
2016年01月15日 11:06:00 Inside_Zhang 阅读数:4445
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lanchunhui/article/details/50522424
构建机器学习模型的一个重要环节是评价模型在新的数据集上的性能。模型过于简单时,容易发生欠拟合(high bias);模型过于复杂时,又容易发生过拟合(high variance)。为了达到一个合理的 bias-variance 的平衡,此时需要对模型进行认真地评估。本文将介绍两个十分有用的cross-validation技术,holdout cross-validation 以及 k-fold cross-validation,这些方法将帮助我们获得模型关于泛化误差(generalization error)的可信的估计,所谓的泛化误差也即模型在新数据集上的表现。
holdout validation
from sklearn.cross_validation import train_test_split使用 holdout 方法,我们将初始数据集(initial dataset)分为训练集(training dataset)和测试集(test dataset)两部分。训练集用于模型的训练,测试集进行性能的评价。然而,在实际机器学习的应用中,我们常常需要反复调试和比较不同的参数设置以提高模型在新数据集上的预测性能。这一调参优化的过程就被称为模型的选择(model selection):select the optimal values of tuning parameters (also called hyperparameters)。然而,如果我们重复使用测试集的话,测试集等于称为训练集的一部分,此时模型容易发生过拟合。
一个使用 holdout 方法进行模型选择的较好的方式是将数据集做如下的划分:
-
训练集(training set);
The training set is used to fit the different models
-
评价集(validation set);
The performance on the validation set is then used for the model selection。
-
测试集(test set);
The advantage of having a test set that the model hasn’t seen before during the training and model selection steps is that we can obtain a less biased estimate of its ability to generalize to new data. 下图阐述了 holdout cross-validation 的工作流程,其中我们重复地使用 validation set 来评估参数调整时(已经历训练的过程)模型的性能。一旦我们对参数值满意,我们就将在测试集(新的数据集)上评估模型的泛化误差。
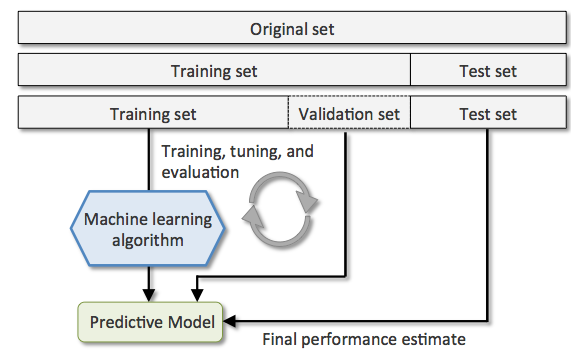
holdout 方法的弊端在于性能的评估对training set 和 validation set分割的比例较为敏感。
k-fold validation
在 k-fold cross_validation,我们无放回(without replacement)地将训练集分为 k folds(k个部分吧),其中的 k-1 folds 用于模型的训练,1 fold 用于测试。将这一过程重复 k 次,我们便可获得 k 个模型及其性能评价。
我们然后计算基于不同的、独立的folds的模型(s)的平均性能,显见该性能将与holdout method相比,对training set的划分较不敏感。一旦我们找到了令人满意的超参的值,我们将在整个训练集上进行模型的训练。
因为k-fold cross-validation 是无放回的重采样技术,这种方法的优势在于每一个采样数据仅只成为训练或测试集一部分一次,这将产生关于模型性能的评价,比 hold-out 方法较低的variance。下图展示了 k=10k=10 时的 k-fold 方法的工作流程。
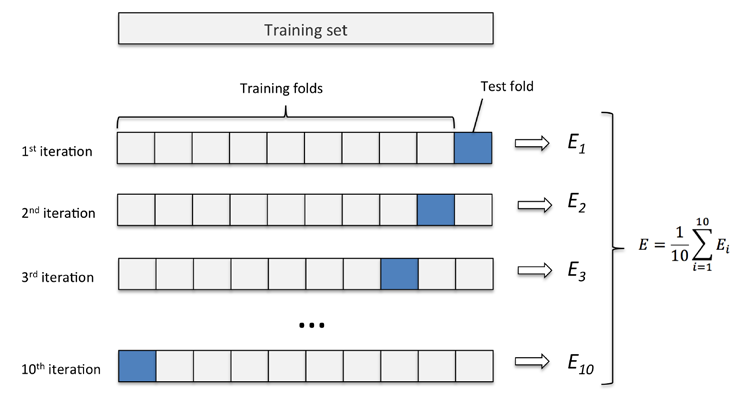
k-fold cross-validation 的 kk 值一般取10,对大多数应用而言是一个合理的选择。然而,如果我们处理的是相对较小的训练集的话,增加 kk 的值将会非常实用。因为如果增加 kk,更多的训练数据(N×(1−1k)N×(1−1k))得以使用在每次迭代中,这将导致较低的 bias在评估模型的泛化性能方面。然而,更大的 kk 将会增加cross-validation的运行时间,生成具有更高higher variance 的评价因为此时训练数据彼此非常接近。另一方面,如果我们使用的是大数据集,我们可以选择更小的 kk,比如 k=5k=5,较小的 kk 值将会降低在不同folds上的refitting 以及模型评估时的计算负担。
一个 k-fold cross-validation 的特例是 LOO(leave-one-out) cross-validation method。在LOO中,我们取 k=nk=n,如前所述,LOO尤其适用于具有小规模的数据集上。
对于 k-fold cross-validation 的一中改进是 stratified k-fold cv method,该方法可以产生更好的 bias以及variance 评价,尤其当 unequal class proportions。
实践
from sklearn.cross_validation import StratifiedKFold
kfolds = StratifiedKFold(y=y_train, n_folds=10, random_state=1)
scores = []
for i, (train, test) in enumerate(kfolds):# train.shape 将是 test.shape的接近9倍clf.fit(X_train[train], y_train[train])score = clf.score(X_train[test], y_train[test])scores.append(score)print('Fold: %s, class dist.: %s, Acc: %.4f' %(i+1, np.bincount(y_train[train]), score))
print('CV accuracy: %.4f +/- %.4f' % (np.mean(scores), np.std(scores)))