RFM模型与Spark实现
- RMF模型
- 什么是RMF模型
- 给R、F、M按价值打分
- 基于RFM模型的用户价值划分
- 代码实现
RMF模型
什么是RMF模型
- R最近一次消费时间:R越小,客户价值越高
- F消费频率:F值会受到品类的影响,不适合做跨类目比较
- M消费金额:最有价值的指标
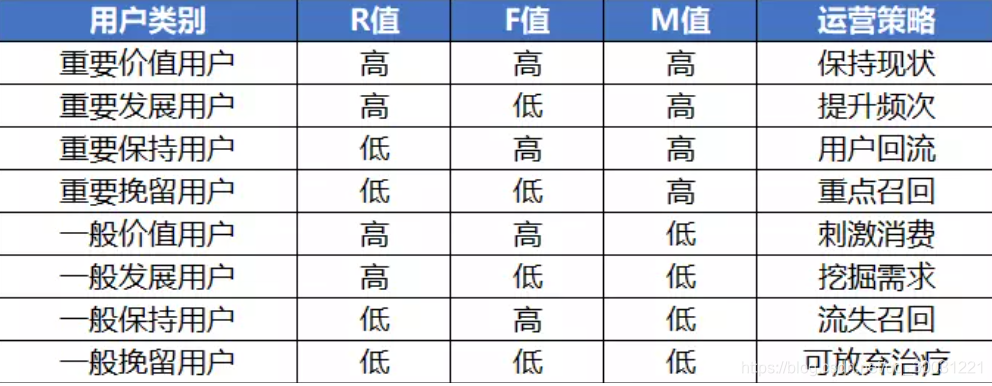
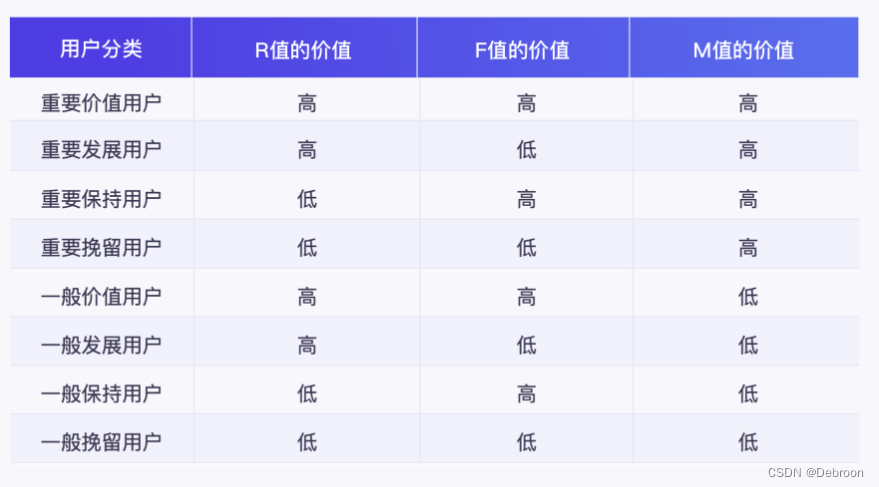
利用以上三个指标将用户分为以下几类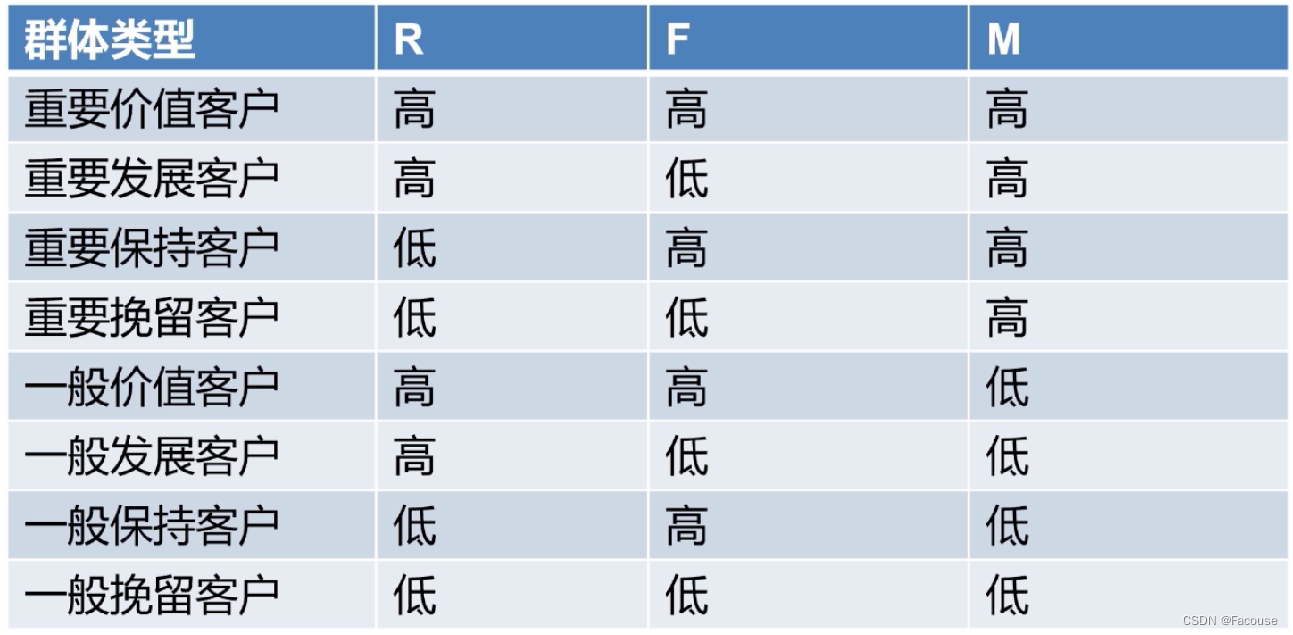
给R、F、M按价值打分
- R打分:最近一次消费距离当前日期越近,分值越高
- F:消费频率越高,得分越高
- M:消费金额越高,得分越高
得分过后需要给R、F、M一定权重,权重根据业务进行选取
基于RFM模型的用户价值划分
- 确定RFM三个指标的分段和每个分段的分值
- 计算每个客户RFM三个指标的得分
- 计算每个客户的总得分,按照值的大小进行人群细分
代码实现
class RFM {/*** 基于RFM模型的客户分群* @param dataSet 数据集* @return 带有RFM打分和标签的数据集*/def rfmGradation(dataSet:DataFrame):DataFrame={//一般情况下,做RFM模型,使用的是过去一年的订单数/** 计算RFM的值 *///计算R: 每个用户最近一次消费距今的时间间隔//datediff: 计算两个日期的间隔//to_date : String 转 dateval r_agg = datediff(max(to_date(col("current_time"))),max(to_date(col("finish_time"))) //获取finish_time的最大值).as("r")//计算F: 每个用户在指定时间范围内的消费次数val f_agg = count(col("*")).as("f")//计算M:每个用户在指定时间范围内的消费总额val m_agg = sum(col("final_total_amount")).as("m")//按用户id聚合获取RFMval rfm_data =dataSet.groupBy(col("user_id")).agg(r_agg,f_agg,m_agg)println("########计算RFM#############")rfm_data.show(false)/** 给RFM打分 (5分制) *///R_SCORE: 1-3天=5分,4-6天=4分,7-9天=3分,10-15天=2分,大于16天=1分val r_score = when(col("r")>=1&&col("r")<=3,5).when(col("r")>=4&&col("r")<=6,4).when(col("r")>=7&&col("r")<=9,3).when(col("r")>=10&&col("r")<=15,2).when(col("r")>=16,1).as("r_score")//F_SCORE: ≥100次=5分,80-99次=4分,50-79次=3分,20-49次=2分,小于20次=1分val f_score = when(col("f")>=100,5).when(col("f")>=80 && col("f")<=99,4).when(col("f")>=50 && col("f")<=79,3).when(col("f")>=20 && col("f")<=49,2).when(col("f")<20,1).as("f_score")//M_SCORE: ≥10000=5分,8000-10000=4分,5000-8000=3分,2000-5000=2分,<2000=1分val m_score = when(col("m")>=10000,5).when(col("m")>=8000 && col("m")<10000,4).when(col("m")>=5000 && col("m")<8000,3).when(col("m")>=2000 && col("m")<5000,2).when(col("m")<2000,1).as("m_score")val rfm_score = rfm_data.withColumn("r_score",r_score).withColumn("f_score",f_score).withColumn("m_score",m_score)println("###########R,F,M打分####################")rfm_score.show(false)//计算RFM的总分,权重根据实际业务进行更改val _rfm_w_score = (col("r_score")*0.6+col("f_score")*0.3+col("m_score")*0.1).as("rfm_score")val rfm_w_score = rfm_score.withColumn("rfm_score",_rfm_w_score)println("##########RFM的总分值###############")rfm_w_score.orderBy(desc("rfm_score")).show(false)val hive_rfm_w_score = rfm_w_score.select(col("user_id"),col("r"),col("f"),col("m"))println("##########准备写入到Hive数仓rfm表###############")hive_rfm_w_score.show(false)/** 打标签 *///重要价值用户 1//重要保持用户 2//一般价值用户 3//RFM_SCORE >= 9: 重要价值用户//RFM_SCORE >= 5 && RFM_SCORE < 9: 重要保持用户//RFM_SCORE < 5: 一般价值用户val tag_rule = when(col("rfm_score")>=9,1).when(col("rfm_score")>=5&&col("rfm_score")<9,2).when(col("rfm_score")<5,3)val _rfm_tag = rfm_w_score.withColumn("tag_rule",tag_rule)val rfm_tag = TagUtils.taggingByRule(_rfm_tag,"rfm客户模型")println("########RFM客户价值标签#############")val hive_rfm_tag = rfm_tag.select(col("user_id"),col("tag_name_cn").as("tag_id"),col("tag_name").as("tag_value"))hive_rfm_tag.show(false)dataSet}}