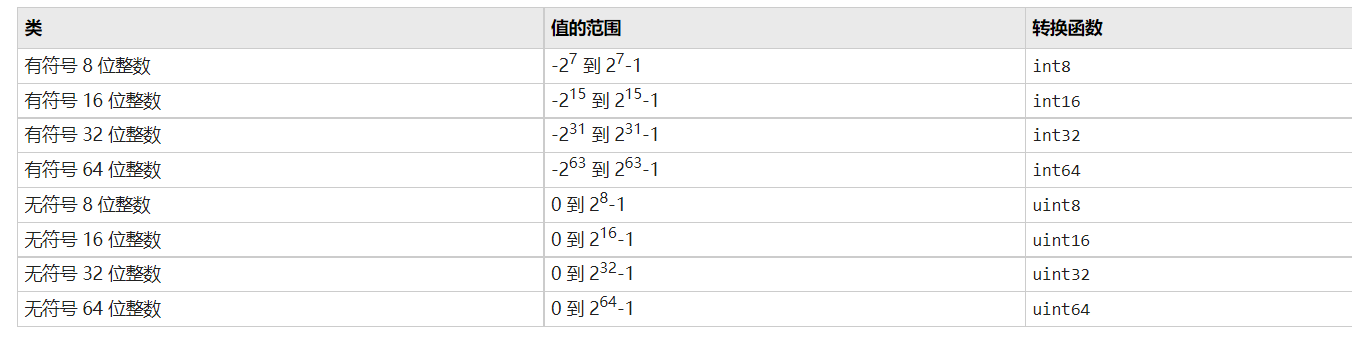
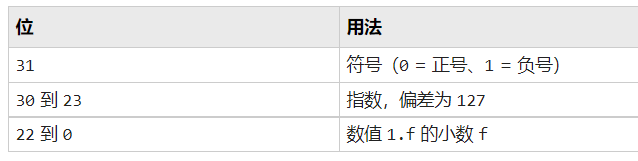
http://www.lencomputer.com/xk2008/lesson19/search_algorithm.htm
状态空间搜索是程序设计中的最基本方法之一。它通过在状态空间中的初始状态出发,按照一定的顺序和条件对空间中的状态进行遍历,最终找到目标状态。一般的状态空间搜索方法有枚举、深度/广度优先搜索、启发式搜索等等,由于枚举法相对比较易懂,这里不再加以介绍;同时介于篇幅的限制,我们在这一讲也不打算单独启发式搜索。于是,本讲的主要内容就是介绍深度/广度优先搜索以及一些常见的优化技巧。
第一部分 深度优先搜索(Depth-first Search)
大多数程序员最先学习的搜索方法恐怕就是深度优先搜索(DFS)了,它那直接的思考方式很容易被人们所理解并接受。基于堆栈技术的回溯法就是DFS的一个很成功的应用,而我们所熟悉的“八皇后问题”便是回溯法中最为经典的问题。来看一看DFS是如何在状态空间中搜索的吧:
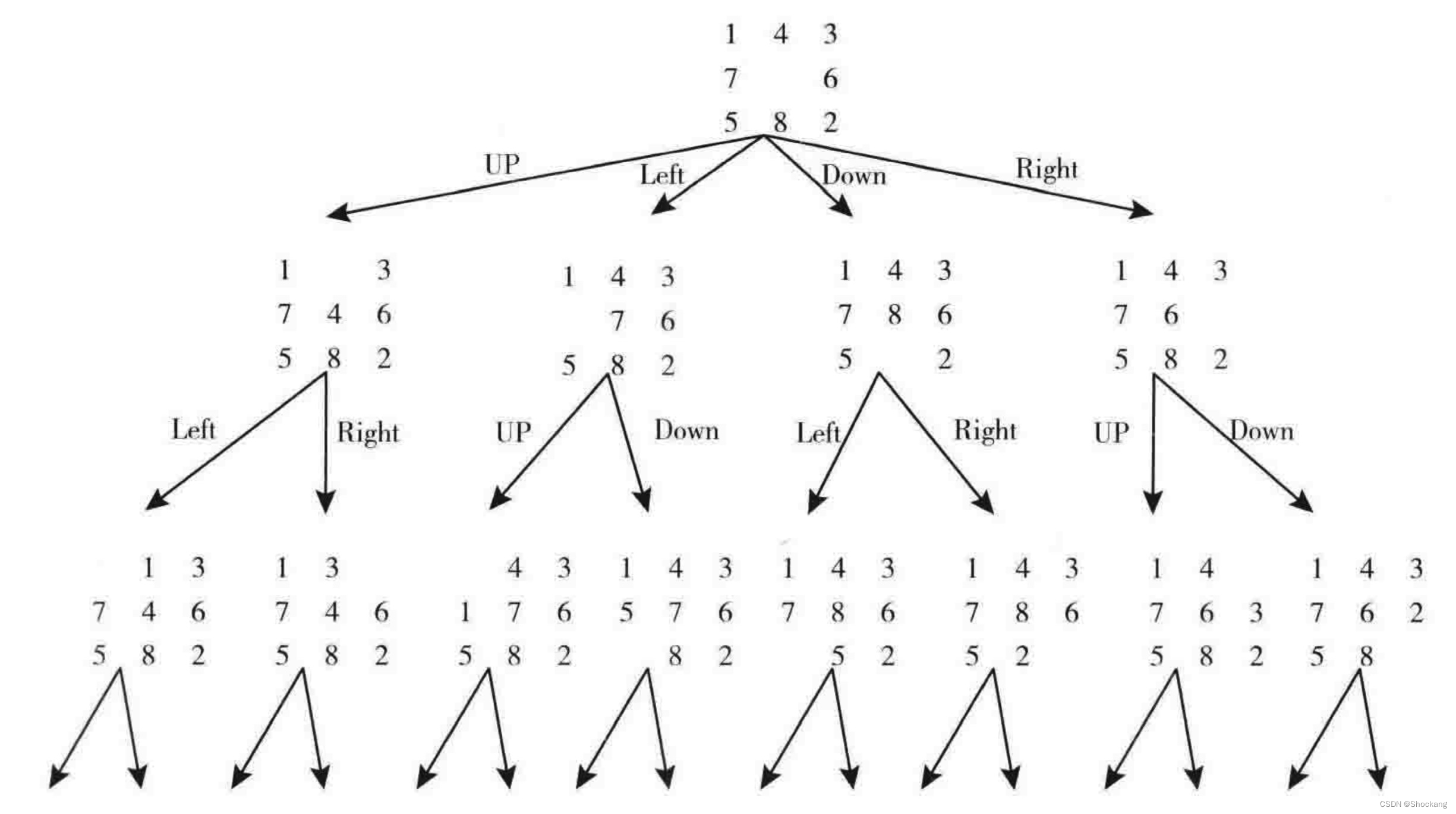
在图1-1的状态空间图中,如果我们选择每次先扩展最左边的结点,再扩展右边的结点,那么我们的搜索顺序就是1-> 2 -> 4 -> 8 -> 9 -> 5 -> 10 -> 11 -> 3 -> 6 -> 12 -> 13 -> 7 -> 14 -> 15。
DFS回溯法的递归实现框架大致如下:
void Dfs(int a)
{//设置出口for(循环枚举可能值){//修改一些参量值。Dfs(a + 1);//恢复之前修改的参量值。}
}1. 普通深度优先搜索
与广度优先搜索(BFS)相比,DFS的一个最大好处就是它所需要的空间开销非常小,因为它只需要记录当前的状态即可。于是,在处理需要遍历大量结点的问题时,DFS就体现出了它在空间复杂度方面的优势。当然,在另一些问题,比如处理形如“目标结点较浅”类型的问题时,相对DFS来说,BFS的时间优势就会相当明显。
来看一个DFS的例子吧:
[例 1-1, POJ 1167] 公交车问题
一男子于12:00来到一个公交车站,他记录下了12:00-12:59所有公交车的到站情况。现在我们假设:
1) 同一条线路的公交车到站是有规律的,也就是每隔一个固定时间就会有一辆车到站。
2) 公交车的到站是以分钟为最小计量单位的。
3) 每一条线路的车至少到站两次。
4) 经过该车站的公交车线路≤17条。
5) 不同线路的公交车可以同时到达该车站。
6) 不同线路的公交车到该车站的时刻和时间间隔均可以相同。
现在问,根据该男子的记录,最少有多少条公交车线路经过该车站?
[分析]
此题是明显的搜索题,且DFS较为合适。由于每条线路只需要第一和第二辆车到达的时刻,就可以完全确定,因此我们可以依次考虑12:00-12:59的车辆到达情况。假设某一个时刻有一辆车到达本站,那么它有两种可能:
1) 它是一条新线路的第一辆车;2) 它是已有某条线路的第二辆车。
如果是情况1),那么我们需将它作一下标记。如果是情况2),那么我们就枚举该线路的第一辆车在何时刻到达,有了此时刻,那么就可以完全确定这条线路,随后我们可以把这一条线路从记录中删除。再根据题干中提到的那么约束条件,我们就可以写出程序了。
2. 迭代加深搜索(Iterative Deepening Search)
尽管DFS对空间复杂度的要求很低,但它也有着不少问题。其中很突出的一点就是,DFS在处理一些“目标结点较浅”的问题时,往往效率不够高。比如图1-1中,如果目标状态为3结点,那么它将在第9步才找到。假如这棵状态树更深一些,或者它是无限长的,那么DFS就很有可能在有限时间内找不到解。而事实上我们看到,目标状态3其实离初始状态1非常接近。
因此这种情况下,我们需要对DFS进行一定的改进。最直接的想法就是,为它设定一个深度限制d,使得我们只在深度d范围内搜索。这样如果目标结点在该范围内,那么就很轻易的找到了解。而只要我们让d从1开始逐渐递增,那么就可以在有限步内找到目标结点。这就是迭代加深搜索思想(IDS)(图1-2)。
在IDS方法中,很多结点都被重复搜索了多次。这对它的效率有一定的影响。分析一下,假设每个结点的子结点个数为b,那么可以看到,每加深一层(由第i层增加到第i+1层),新扩展出的结点数为bi+1,而之前的结点数为1+b+b2+…+bi=bi+1-1,差不多有一半结点被重复了。不过尽管如此,可以看到它的时间复杂度比DFS只是增加了常数倍,从数量级上来看是一样的。
第二部分 广度优先搜索(Breadth-first Search)
广度优先搜索(BFS)也是最为常用的搜索方法之一。与DFS相比,BFS最大的不同是它的搜索顺序是按照逐层扩展的,对于图1-1来说,BFS依次扩展出的结点为1->2->3->…->15,因此它所用来存储的数据结构是队列而不是堆栈。BFS的实现框架大致如下:
void BFS()
{while(队列可扩展且尚未找到目标状态){//从队首依次取出队列中未扩展的结点进行扩展,并将新结点加入队尾。}
}1. 普通广度优先搜索
对于求“最短步数”一类的问题,一般BFS会比DFS快一些。原因就在于DFS经常会纠缠于那些找不到目标结点的分支中。来看一看下面这个经典的例子:
[例2-1, POJ 1077] 八数码问题
给定一个3*3的格子,里面已经填上了数字1-8以及一个空格,问是否能够通过空格移动数字,使得最终能得到如下图案:
[分析]
如果盲目移动数字,那么很容易就会出现重复的情况。因此我们需要判重。那么如何记录一个图案状态呢?如果我们将图上的9个格子中的数(空格看成9)线性地连起来,那么这样一个排列就能唯一地确定一个图。接下来我们只需给出一个排列的序号即可:
对于一个序列:a1a2…a9,可以依次考虑数字ai(1≤i≤9)后有几个数字小于它,设ai后有bi个数比它小,那么ai贡献的权值为bi*(9-i)!,最后计算 ,就得到了它的序号。这个方法很直接也好理解,就不再解释了。由于9个数的排列有9!种方法,因此我们需要大小为9!的数组来判重。
接下来就是用什么搜索方法的问题了。可以看到,虽然题目里没有明确说求最短的移动方法,但是相对来说,如果我们能找到最短的移动方法,那么自然算法的速度相对会快一些。所以这里我们可以使用BFS(当然带判重DFS也是可以的)来解题。队列的初始状态就是初始图案上数字的线性排列,比如图2-1(a)中就是973851624,我们需要得到的目标状态是123456789。通过BFS的基本框架,实现算法应该是较为容易的。
这里给出一个小技巧,如果题目是多Case的,那么可以作预处理,即把初始状态设为123456789,用一遍BFS算出所有可达状态是如何到达的,然后根据给定的输入数据,将原先的移动过程颠倒,就得到我们所需要的答案。这样多个Case只需一遍BFS,而不是多遍BFS就能解决了。
2. 双向广度优先搜索
对于一棵搜索状态树,如果每个结点的子结点数目很多,那么状态数每加深一层,就会扩展出指数倍的状态树。因此,我们希望能对状态数目做适当的控制。双向广搜就是这样一种方法,假如我们知道初始状态S和目标状态T,也知道由初始到目标最多需要经过的步数K,那么我们可以这样做:
先用BFS对S扩展出深度≤[k/2]的所有结点,假如没有找到T,那么再对T用BFS反向扩展出深度≤k-[k/2]的所有结点,这些结点中必然与之前的某些结点有重复,考察这些结点,我们就能够找到一条最短路径。用图表示如下:
可以看出,双向广搜的最大好处就是可以少扩展出指数倍的无用结点,为搜索节省了大量的空间和时间。
第三部分 搜索的优化技巧
1.改变搜索顺序
搜索顺序的确立对于搜索的效率是很重要的,如果我们每次都选择先扩展更接近目标状态的结点,那么就会更快的找到最优解,并为剪枝提供依据。因此,搜索顺序的改变往能起到意想不到的效果。事实上搜索顺序的不同也是BFS和DFS之间最大的区别之一。这一节我们没有对A*算法做介绍,事实上,A*算法就是一种典型的通过调整搜索顺序来更快找到解的方法。它利用一个评价函数来决定子结点的优先级,然后按优先级从高到低的顺序依次进行遍历。这显然比盲目搜索法要好得多。
2.增加剪枝策略
剪枝是搜索中最基本,也是最重要的技巧之一。有时一条好的剪枝可以去掉一棵搜索状态树中大部分的无用结点。剪枝策略的好坏,决定了搜索法的最终效率。有时,一个问题可以采用几种不同的搜索方法,这时,我们就会选择其中具有最好剪枝手段的那个方法。用一个例子来的剪枝技巧吧:
例3,POJ 1011] 合并木棒
我们有n(n≤64)根小木棍,每根长度均不大于50。现在需要将它们拼接成长度相同的若干长木棍,使得这些长木棍最短。
[分析]
此题也是很明显的搜索题。最直接的思路就是从小到大枚举每个拼成后的木棍长(d),之所以要从小到大,是因为按题意,最小的长度才是我们要找的解,因此,按从小到大的顺序找到的第一个满足题意的长度d就是该问题的解。假设所有木棍总长为t,那么一共就要拼d/t根木棍。随后我们用小木棍将这d/t根木棍一根一根地拼完即可。当然,由于数据量不算小,如果直接做很难在规定时间内出解,故我们需要有一些好的剪枝技巧:
1) 让我们先对木棍长从大到小排个序,之所以从大到小,是因为直观上,先拼上长木棍,接下来用短木棍补充似乎更容易成功拼完。如果先费了一番功夫拼短木棍,最后发现接上剩下的任何一根长木棍都已超过当前枚举的长度d,那么就浪费了之前的搜索。
2)枚举的长度d也有要求,首先d应该不小于最长的小木棍长度,不大于木棍总长t。其次d必须是t的约数。这个剪枝很容易想到,也对减小搜索量非常有帮助。
接下来就可以进行搜索了,可以用一个函数
bool solve(int rest, int start, int step)进行DFS,其中rest表示正在拼的当前木棍还需要多少长度,start表示当前可以从第几根开始拼,Step表示当前还剩下多少根小木棍。
搜索中同样可以找到好些剪枝策略。
3) 我们从start到n枚举小木棍编号i,如果此时rest=len(i),那么显然把这根木棍拼上是最好的选择了,也不需要枚举i+1…n号木棍了。
4) 如果len(i)…len(j)都具有相同的长度,那么试探完i后应该跳过这些相同长度的小木棍,直接枚举第(j+1)号小木棍。
5) 如果当前挑选的小木棍是目前正在拼的木棍的首根木棍,即rest == d, 那么试完i后我们没有必要再去试i+1,而是直接跳回递归上一层。因为对于一个合理的分配,小木棍i一定属于某一根待拼木棍,而当前木棍还没有开始拼,既然是这样,那么就可以认为它属于当前木棍。如果拼上它后,没有能够形成满足条件的解。那么也就没有必要继续尝试了,因为在上一层的木棍分配上肯定已经出现了错误。
可以看出,以上说的这些剪枝条件很多都不能直接能想到,需要仔细分析搜索过程后才能得出。剪枝策略是多种多样的,不同的问题对应有的不同策略。同时,由于每次都需要一些适当的判断,剪枝也会相应地付出一些代价。有些剪枝的“成本”甚至超过了它所带来的益处,这显然是不可取的。那些能够补偿策略本身所花费代价的剪枝,才能称得上是好的剪枝。