刚接触图像恢复问题,简单记录一下最近看论文刚弄懂的一个小问题
ADMM算法
ADMM(交替方向乘子法)是一种解决变量可分离凸优化问题的简单算法,具有求解速度快,收敛性能好的特点。ADMM可以将原问题转换为几个子问题,分别并行求解,最后协调各个子问题的解,得到原问题最优解。
算法流程
ADMM算法主要用于解决如下凸优化问题:
arg min x , y f ( x ) + g ( y ) s . t . A x + B y = c \argmin_{x,y} f(x)+g(y) \\ s.t.\quad Ax+By=c x,yargminf(x)+g(y)s.t.Ax+By=c
其中, x ∈ R n x \in R^n x∈Rn为目标函数 f ( x ) f(x) f(x) 的优化变量, y ∈ R m y \in R^{m} y∈Rm为目标函数 g ( y ) g(y) g(y) 的优化变量, A ∈ R p × n A\in R^{p\times n} A∈Rp×n , B ∈ R p × m B\in R^{p\times m} B∈Rp×m , c ∈ R p c\in R^p c∈Rp 。 函数 f f f, g g g 是凸函数。
- 首先写出他的增广拉格朗日函数:
L ρ ( x , y , λ ) = f ( x ) + g ( y ) + λ T ( A x + B y − c ) + ρ / 2 ∥ A x + B y − c ∥ 2 2 , ρ > 0 L_{\rho}(x,y,\lambda) = f(x)+g(y)+\lambda^T(Ax+By-c)+\rho/2\Vert Ax+By-c\Vert ^2_2, \quad \rho>0 Lρ(x,y,λ)=f(x)+g(y)+λT(Ax+By−c)+ρ/2∥Ax+By−c∥22,ρ>0
λ ∈ R p \lambda \in R^p λ∈Rp是拉格朗日乘子, ρ \rho ρ为惩罚参数且 ρ > 0 \rho>0 ρ>0。 - 利用ADMM算法求解:
x k + 1 = arg min x L ρ ( x , y k , λ k ) y k + 1 = arg min y L ρ ( x k + 1 , y , λ k ) λ k + 1 = λ k + ρ ( A x k + 1 + B y k + 1 − c ) x_{k+1} = \argmin_x L_{\rho}(x,y_k,\lambda_k)\\ y_{k+1} = \argmin_y L_{\rho}(x_{k+1},y,\lambda_k)\\ \lambda_{k+1} = \lambda_k+\rho(Ax_{k+1}+By_{k+1}-c) xk+1=xargminLρ(x,yk,λk)yk+1=yargminLρ(xk+1,y,λk)λk+1=λk+ρ(Axk+1+Byk+1−c)
实际上就是将 x x x和 y y y的联合优化过程分开了。 - 利用放缩对偶变量进行化简:
根据向量乘法公式 ∥ a + b ∥ 2 2 = ∥ a ∥ 2 2 + 2 a T b + ∥ b ∥ 2 2 \Vert a+b\Vert_2^2 = \Vert a \Vert_2^2+2a^Tb+\Vert b \Vert_2^2 ∥a+b∥22=∥a∥22+2aTb+∥b∥22得 2 a T b + ∥ b ∥ 2 2 = ∥ a + b ∥ 2 2 − ∥ a ∥ 2 2 2a^Tb +\Vert b \Vert_2^2= \Vert a+b\Vert^2_2-\Vert a \Vert_2^2 2aTb+∥b∥22=∥a+b∥22−∥a∥22,所以 L ρ ( x , y , λ ) L_{\rho}(x,y,\lambda) Lρ(x,y,λ)中的线性项 λ T ( A x + B y − c ) \lambda^T(Ax+By-c) λT(Ax+By−c)和二次项 ρ / 2 ∥ A x + B y − c ∥ 2 2 \rho/2\Vert Ax+By-c\Vert ^2_2 ρ/2∥Ax+By−c∥22可以进行合并:
λ T ( A x + B y − c ) + ρ / 2 ∥ A x + B y − c ∥ 2 2 = ρ 2 ( 2 λ T ρ ( A x + B y − c ) + ∥ A x + B y − c ∥ 2 2 ) = ρ 2 ( ∥ A x + B y − c + λ T / ρ ∥ 2 2 − ∥ λ / ρ ∥ 2 2 \lambda^T(Ax+By-c)+\rho/2\Vert Ax+By-c\Vert ^2_2 \\ \begin{array}{l} =\frac{\rho}2\left ( 2\frac{\lambda^T}{\rho}(Ax+By-c)+\Vert Ax+By-c\Vert ^2_2\right ) \\ =\frac{\rho}2(\Vert Ax+By-c+\lambda^T/\rho\Vert_2^2 - \Vert \lambda/\rho\Vert_2^2 \end{array} λT(Ax+By−c)+ρ/2∥Ax+By−c∥22=2ρ(2ρλT(Ax+By−c)+∥Ax+By−c∥22)=2ρ(∥Ax+By−c+λT/ρ∥22−∥λ/ρ∥22
由于最后一项 ∥ λ / ρ ∥ 2 2 \Vert \lambda/\rho\Vert_2^2 ∥λ/ρ∥22与 x x x, y y y无关,因此不影响 x x x和 y y y子问题的求解,可以在求解子问题时省略。 - 令放缩对偶变量为 u = λ / ρ u=\lambda/\rho u=λ/ρ,则ADMM算法可以改写为以下形式:
x k + 1 = arg min x f ( x ) + ρ / 2 ∥ A x + B y k − c + u k ∥ 2 2 y k + 1 = arg min x g ( y ) + ρ / 2 ∥ A x k + 1 + B y − c + u k ∥ 2 2 u k + 1 = u k + A x k + 1 + B y k + 1 − c x_{k+1} = \argmin_x f(x)+\rho/2\Vert Ax+By_k-c+u_k\Vert_2^2\\ y_{k+1} = \argmin_x g(y)+\rho/2\Vert Ax_{k+1}+By-c+u_k\Vert_2^2\\ u_{k+1} = u_k+Ax_{k+1}+By_{k+1}-c xk+1=xargminf(x)+ρ/2∥Ax+Byk−c+uk∥22yk+1=xargming(y)+ρ/2∥Axk+1+By−c+uk∥22uk+1=uk+Axk+1+Byk+1−c
论文中经常利用放缩形式的ADMM算法,而刚开始接触ADMM时并不知道这种形式,所以导致很长一段时间我没看懂论文里公式是怎么推导的,这里对他的推导进行了一个总结。
在压缩图像重建中的应用
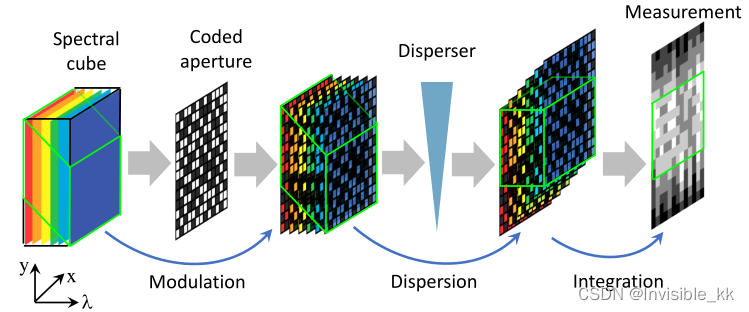
以上是压缩快照图像的成像过程,可以用以下公式来表示:
y = H x + z \pmb{y}= \pmb{H}\pmb{x}+\pmb{z} y=Hx+z
y \pmb{y} y代表观测图像, x \pmb{x} x代表理想的干净图像, H H H代表退化矩阵,是已知的, z \pmb z z代表观测噪声。
作者结合了深度图像先验以及去噪先验提出了以下重建模型:
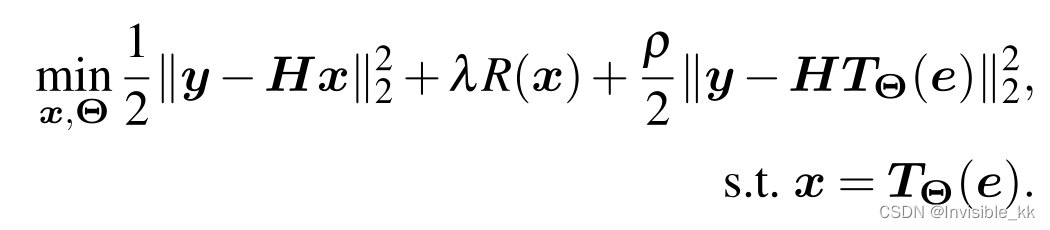
其中 T Θ ( e ) \pmb{T_\Theta(e)} TΘ(e)是一个未训练的神经网络(参考论文Deep Image Prior),用于提取图像先验, R ( x ) \pmb{R(x)} R(x)是去噪先验。以上优化模型可以利用ADMM算法进行求解,这里的第一项是保真项,后两项是先验项。然后引入放缩对偶变量 b \pmb{b} b,就能得到下面的式子:
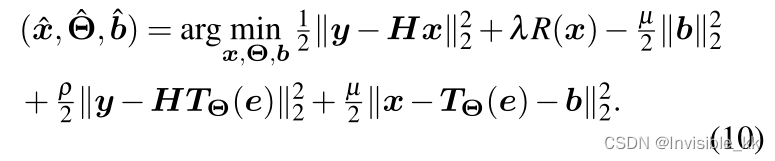
再利用ADMM算法就可以将上述问题解耦为关于 x , Θ , b \pmb{x,\Theta,b} x,Θ,b的三个子问题:
Θ ^ = arg min Θ ρ 2 ∥ y − H T Θ ( e ) ∥ 2 2 + μ 2 ∥ x − T Θ ( e ) − b ∥ 2 2 x ^ = arg min x 1 2 ∥ y − H x ∥ 2 2 + λ R ( x ) + μ 2 ∥ x − T Θ ( e ) − b ∥ 2 2 b k + 1 = b k − ( x k − T Θ k ( e ) ) \begin{array}{l} \hat{\boldsymbol{\Theta}}=\argmin\limits_{\Theta} \frac{\rho}{2}\left\|\boldsymbol{y}-\boldsymbol{H} \boldsymbol{T}_{\boldsymbol{\Theta}}(\boldsymbol{e})\right\|_{2}^{2}+\frac{\mu}{2}\left\|\boldsymbol{x}-\boldsymbol{T}_{\boldsymbol{\Theta}}(\boldsymbol{e})-\boldsymbol{b}\right\|_{2}^{2} \end{array}\\ \hat{\boldsymbol{x}}=\argmin_{\boldsymbol{x}} \frac{1}{2}\|\boldsymbol{y}-\boldsymbol{H} \boldsymbol{x}\|_{2}^{2}+\lambda R(\boldsymbol{x})+\frac{\mu}{2}\left\|\boldsymbol{x}-\boldsymbol{T}_{\boldsymbol{\Theta}}(\boldsymbol{e})-\boldsymbol{b}\right\|_{2}^{2} \\ \boldsymbol{b}^{k+1}=\boldsymbol{b}^{k}-\left(\boldsymbol{x}^{k}-\boldsymbol{T}_{\boldsymbol{\Theta}^{k}}(\boldsymbol{e})\right) Θ^=Θargmin2ρ∥y−HTΘ(e)∥22+2μ∥x−TΘ(e)−b∥22x^=xargmin21∥y−Hx∥22+λR(x)+2μ∥x−TΘ(e)−b∥22bk+1=bk−(xk−TΘk(e))
关于 Θ \Theta Θ的子问题利用DIP网络求解,这个式子可以直接作为他的loss函数,关于x的子问题含有 R ( x ) R(x) R(x)先验项,不便于直接求解,可以再利用ADMM算法进行分解,相当于ADMM里嵌套了一个ADMM,具体可以参考原论文。
论文链接: Self-supervised Neural Networks for Spectral Snapshot Compressive Imaging
参考网址:Anna的知乎回答:ADMM算法的详细推导过程是什么