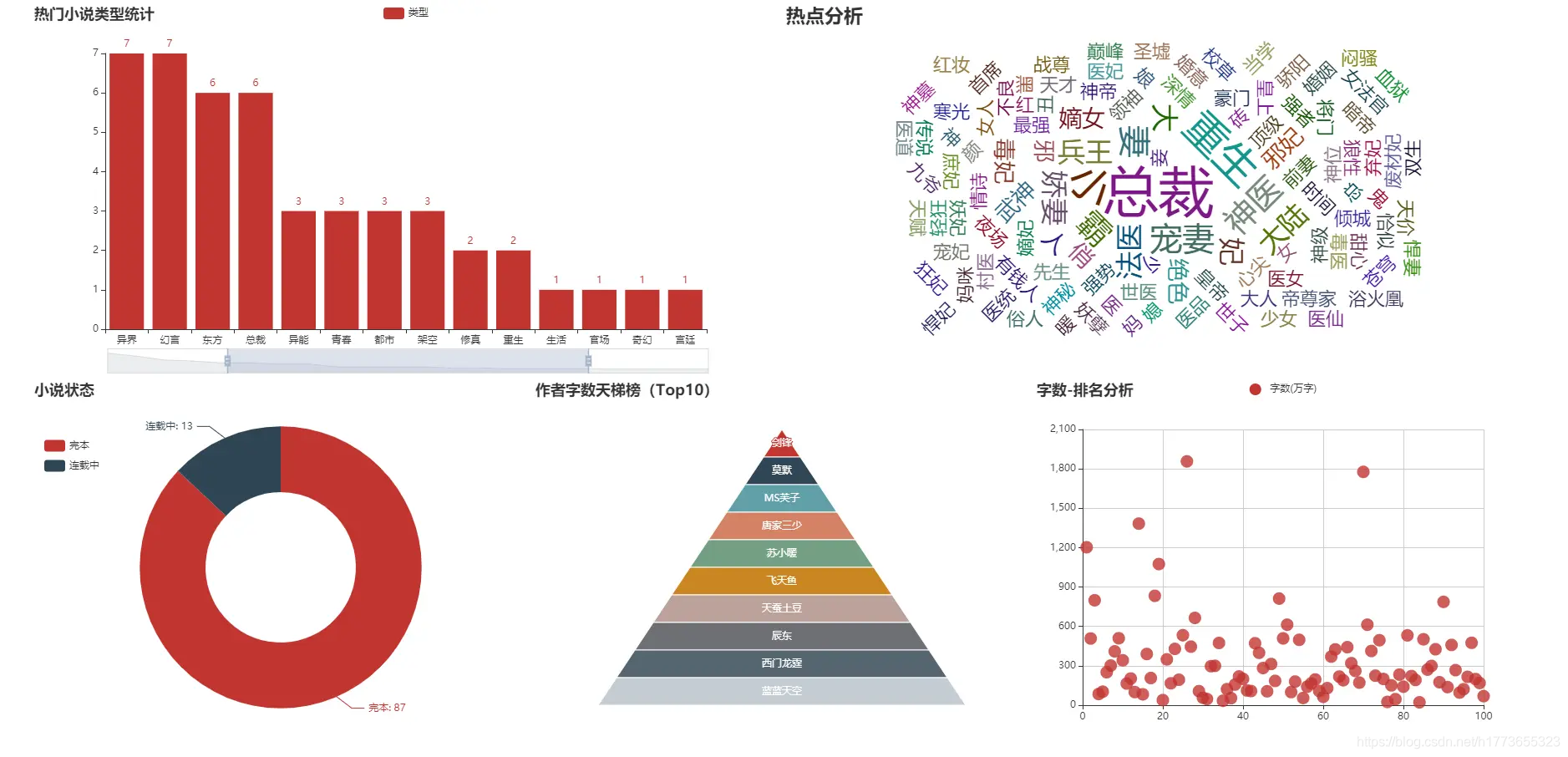
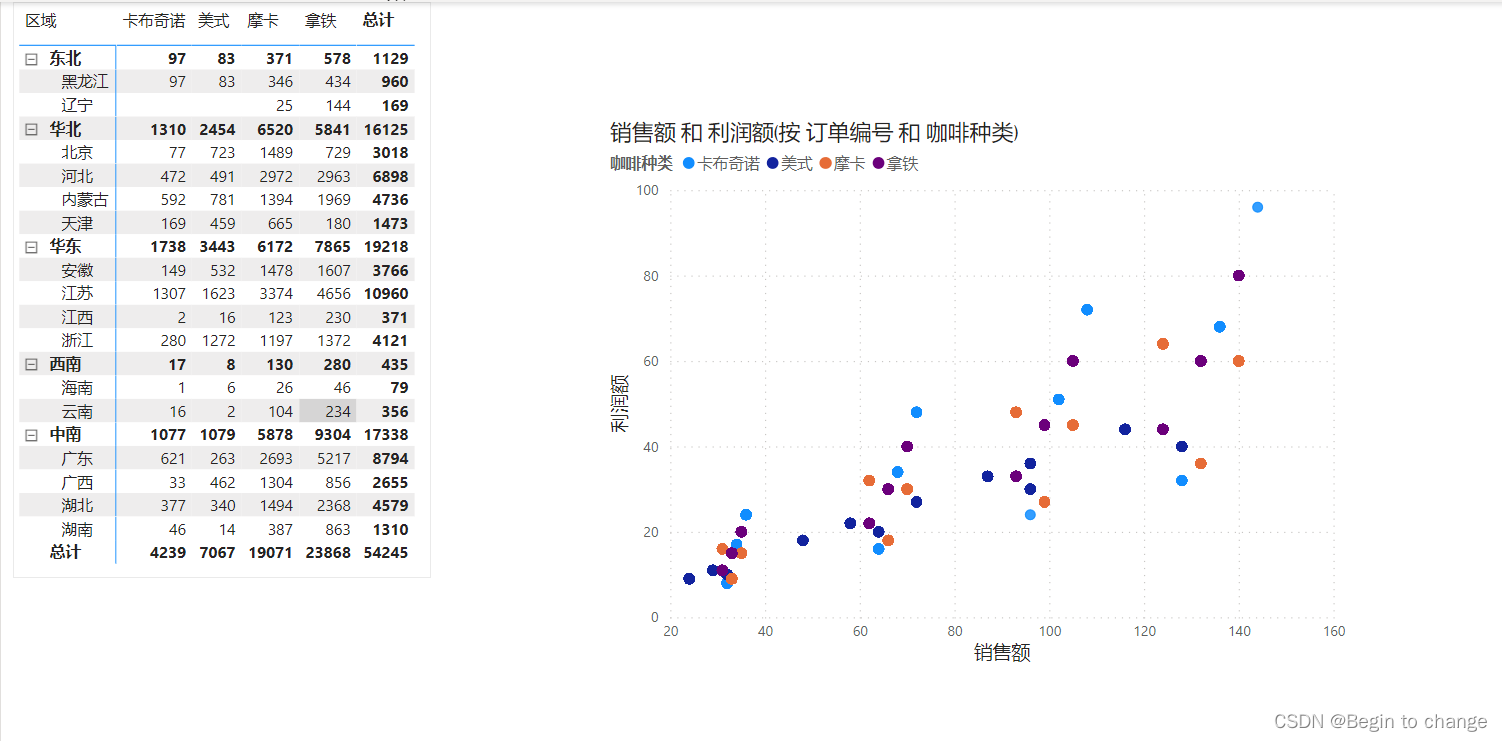
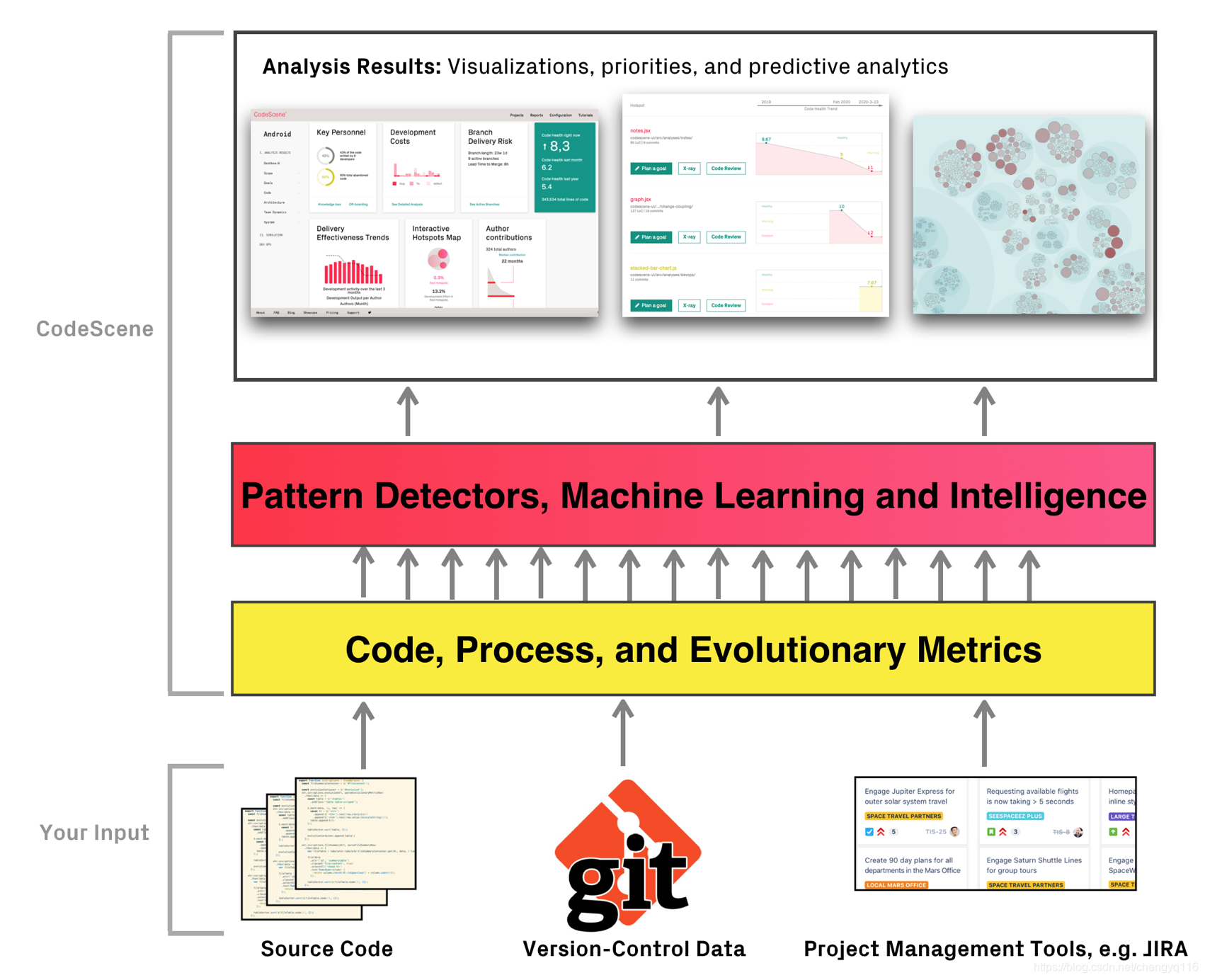
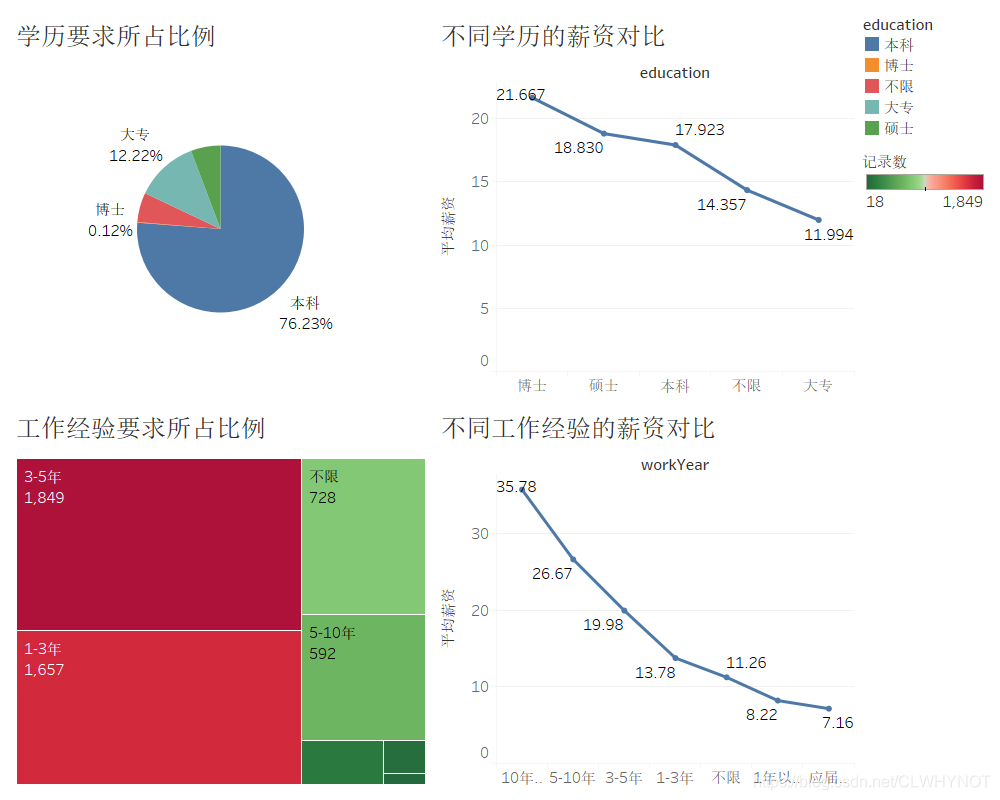
在一些比较经典的GAN模型中(像WGAN、LSGAN、DCGAN等等),往往都是从样本空间里随机采样得到输入噪声,生成的图像究竟属于哪一个类别也是随机的。通过这些模型,我们无法生成指定类别的数据。
举个不恰当的例子:在解放前夕,我们的目标就是填饱肚子,吃嘛嘛香;随着经济社会的不断发展和祖国的繁荣昌盛,我们变得越来越挑剔,比如今天只想吃波士顿龙虾,明天只想吃澳洲大螃蟹… GAN的发展也是一样,早期我们只关注GAN否生成清晰度高、类别丰富的图像数据,但是发展到一定的程度,我们就希望模型能够按照我们的要求生成出指定类别的数据。同时也可以一定程度上解决GAN训练太自由,以至于在一些复杂数据集上不稳定的弊病。
于是在早些时候,有两种比较经典的模型CGAN和InfoGAN,都可以生成指定模式的数据。下面对两种模型分别做一下简介。
CGAN
CGAN(Conditional GAN)模型是有监督的,即利用了数据集中的标签信息。在传统GAN中,Discriminator的打分非常简单粗暴,生成的图像比较真实打高分,比较模糊的打低分。但是当引入了标签信息以后,打分规则需要变得更加严格。也就是说,模糊的图像还是打低分;但是在清晰真实的生成图像中,如果该图像与他的标签不匹配,也是需要打低分的。
CGAN的结构与传统的GAN非常相似,其模型如下图所示:
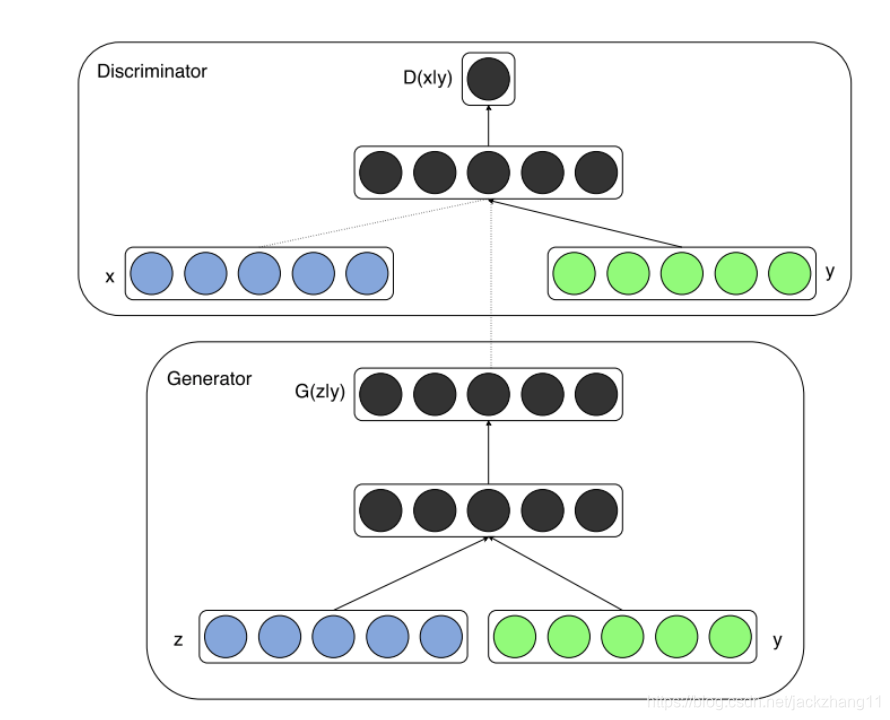
根据上面的模型图,CGAN引入标签 y y y 的方法也非常直接,就是在Generator和Discriminator的输入层,加上一个额外的one-hot向量,也就是图像的标签信息。因此,整个优化目标就变为:
V ( G , D ) = E x ∼ P d a t a [ l o g ( D ( x ∣ y ) ) ] + E z ∼ P z [ 1 − l o g ( D ( G ( z ∣ y ) ) ) ] V(G,D)=E_{x \sim P_{data}}[log(D(x|y))]+E_{z \sim P_{z}}[1-log(D(G(z|y)))] V(G,D)=Ex∼Pdata[log(D(x∣y))]+Ez∼Pz[1−log(D(G(z∣y)))]
根据公式可以看出,Generator和Discriminator都改造成了条件概率的形式,即在给定标签向量 y y y 的条件下进行计算。因此,可以看作是每一个类别 y y y 都对应一个隶属于自己的目标函数。有了这个约束,假如生成了清晰但是类别与标签不匹配的图像,也会当做fake来进行打分。因此可以通过调整标签的值,来改变生成数据的类别。
InfoGAN
相对于CGAN来说,InfoGAN是通过无监督学习来得到一些潜在的特征表示,这些潜在的特征就包括数据的类别。如果现在有一个数据集,里面的数据没有标签信息,但仍存在潜在的类别差异,此时InfoGAN就可以提供一种无监督的方法,来辨别出数据中潜在的类别差异,并且可以通过控制潜在编码 latent code 来生成指定类别的数据。
举个不恰当的栗子,现在摆在我面前有一卡车美食,但是我并不知道他们是什么(没有标签),只知道这些都是食物。现在我吃到一个带壳的、两个钳两条腿的、味道鲜美的东西,特别好恰,但由于没有(澳洲大螃蟹)这个标签,所以无法通过CGAN去得到它。但是呢,虽然有一卡车的美食,且没有标签信息区分他们的类别,但很显然他们是有潜在的类别区分的,螃蟹和狗不理包子就是不一样…因此这时候通过无监督的InfoGAN,即使是在没有标签信息的指导下,也可以学习到样本中潜在的类别差异,从而可以生成鲜美可口的澳洲大螃蟹。

InfoGAN 将 Generator 的输入拆分成两个部分,一部分是 latent code,一般记作 c c c,另一部分和传统 GAN 的输入一样,是一个噪声向量 z z z。其中, c c c 通常包括两个部分,一部分是离散的,一部分是连续的。这个latent code是可以服从于某种分布的。对于MNIST数据集来说,离散的部分可以服从一个多项分布(Multinomial Distribution),取值空间是0-9内的随机数字;连续的部分可以服从某个连续的分布(如均匀分布、正态分布),每一个维度代表着某种潜在的数据特征(如笔画的粗细、倾斜程度等)。
InfoGAN的精髓在于,在原始GAN的基础上,加入 latent code 与 生成数据 之间的互信息作为约束,使两者之间产生一定的关联。因为隐变量 c c c 携带着某种可以解释生成数据 G ( z , c ) G(z,c) G(z,c) 的信息。如果两者的相关性强,那么 c c c 与 G ( z , c ) G(z,c) G(z,c) 之间的互信息 I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c)) 就比较大(互信息简而言之,是描述两个随机变量相关程度的一种度量)。所以InfoGAN的优化目标可以改写为:
m i n G m a x D V I ( G , D ) = V ( G , D ) − λ I ( c ; G ( z , c ) ) min_{G}max_{D}V_{I}(G,D)=V(G,D)-\lambda I(c;G(z,c)) minGmaxDVI(G,D)=V(G,D)−λI(c;G(z,c))
但是这个互信息 I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c)) 并不能直接计算,因为:
I ( c ; G ( z , c ) ) = H ( c ) − H ( c ∣ G ( z , c ) ) = H ( c ) + E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) ] ] I(c;G(z,c))=H(c)-H(c|G(z,c))=H(c)+E_{x \sim G(z,c)} [E_{c' \sim P(c|x)}[logP(c'|x)]] I(c;G(z,c))=H(c)−H(c∣G(z,c))=H(c)+Ex∼G(z,c)[Ec′∼P(c∣x)[logP(c′∣x)]]
上式中隐变量的后验 P ( c ∣ x ) P(c|x) P(c∣x) 是无法得到的,所以这里采取变分推断,利用一个可控的辅助分布 Q ( c ∣ x ) Q(c|x) Q(c∣x) 来近似这个无法得到的后验概率 P ( c ∣ x ) P(c|x) P(c∣x),于是互信息可以进一步写为:
I ( c ; G ( z , c ) ) = H ( c ) + E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) Q ( c ′ ∣ x ) Q ( c ′ ∣ x ) ] ] I(c;G(z,c))=H(c)+E_{x \sim G(z,c)} [E_{c' \sim P(c|x)}[log\frac{P(c'|x)}{Q(c'|x)}Q(c'|x)]] I(c;G(z,c))=H(c)+Ex∼G(z,c)[Ec′∼P(c∣x)[logQ(c′∣x)P(c′∣x)Q(c′∣x)]]
= H ( c ) + E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) Q ( c ′ ∣ x ) + l o g Q ( c ′ ∣ x ) ] ] =H(c)+E_{x \sim G(z,c)} [E_{c' \sim P(c|x)}[log\frac{P(c'|x)}{Q(c'|x)}+logQ(c'|x)]] =H(c)+Ex∼G(z,c)[Ec′∼P(c∣x)[logQ(c′∣x)P(c′∣x)+logQ(c′∣x)]]
= H ( c ) + E x ∼ G ( z , c ) [ K L ( P ( ⋅ ∣ x ) ∣ ∣ Q ( ⋅ ∣ x ) ) + E c ′ ∼ P ( c ∣ x ) l o g Q ( c ′ ∣ x ) ] ] =H(c)+E_{x \sim G(z,c)} [KL(P(\cdot|x)||Q(\cdot|x))+E_{c' \sim P(c|x)}logQ(c'|x)]] =H(c)+Ex∼G(z,c)[KL(P(⋅∣x)∣∣Q(⋅∣x))+Ec′∼P(c∣x)logQ(c′∣x)]]
≥ H ( c ) + E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) l o g Q ( c ′ ∣ x ) ] ] \geq H(c)+E_{x \sim G(z,c)} [E_{c' \sim P(c|x)}logQ(c'|x)]] ≥H(c)+Ex∼G(z,c)[Ec′∼P(c∣x)logQ(c′∣x)]]
由于KL散度非负,这里将极大化互信息的问题,转化为极大化互信息的下界,令:
L 1 ( G , Q ) = H ( c ) + E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) l o g Q ( c ′ ∣ x ) ] ] L_{1}(G,Q) = H(c)+E_{x \sim G(z,c)} [E_{c' \sim P(c|x)}logQ(c'|x)]] L1(G,Q)=H(c)+Ex∼G(z,c)[Ec′∼P(c∣x)logQ(c′∣x)]]
这里又发现一个问题, P ( c ∣ x ) P(c|x) P(c∣x) 我们还是不知道,所以作者在论文中证明了一个引理,即:
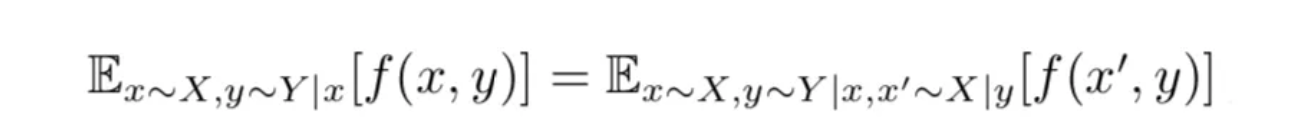
通过上述引理,可将互信息下界 L 1 ( G , D ) L_{1}(G,D) L1(G,D)改写为:
L 1 ( G , Q ) = H ( c ) + E c ∼ P ( c ) , x ∼ G ( z , c ) [ l o g Q ( c ∣ x ) ] L_{1}(G,Q) = H(c)+E_{c \sim P(c), x \sim G(z,c)} [logQ(c|x)] L1(G,Q)=H(c)+Ec∼P(c),x∼G(z,c)[logQ(c∣x)]
这里感兴趣的话可以证明一下。通过这个转换,避免了从隐变量后验分布中进行采样,因此可以直接通过蒙特卡洛进行采样即可。因此最终的优化目标为:
m i n G m a x D V I ( G , D , Q ) = V ( G , D ) − λ I ( G ; Q ) min_{G}max_{D}V_{I}(G,D,Q)=V(G,D)-\lambda I(G;Q) minGmaxDVI(G,D,Q)=V(G,D)−λI(G;Q)
InfoGAN的理论到这里就差不多了,下面浅谈一下实验环节。
Github上看过几个实验,也跑通了程序,基本思路大致是:假设是在MNIST上训练,输入的向量分为三个部分,10维的离散特征(服从多项分布),2维的连续特征(可以服从(-1,1)均匀分布),62维的噪声(后面两个维度都可以更改)。分别对三者进行采样,然后进行拼接组成输入向量,通过Generator生成图像。和传统的GAN一样,对Generator和Discriminator进行辨别图像真假的训练。
不同的是,InfoGAN需要加入互信息的约束。在这里引入一个额外的网络Q,该网络除最后一层以外都与鉴别器D共享权值(D和Q只有最后一层全连接不一样,D最后的维度是1,而Q最后是离散特征和连续特征个数的总和,上例中是10+2)。
这样一来,生成器G与额外引进的网络Q,两者一起相当于构成了一个AutoEncoder。首先通过G,将一些潜在特征编码到生成图像中,再通过Q进行解码得到 latent code,这种“特征-数据-特征”的 AutoEncoder,虽然与传统意义的“数据-特征-数据”的 AutoEncoder 相反,但也可以通过 Reconstruction Error 来进行约束。因为通过重构误差就可以知道生成图像中究竟携带了多少 c c c 的特征,如果在 encoder 过程中失去了输入的特征,那么在 decode 以后也不会得到相近的 latent code。
所以,通过连续部分和离散部分的重构误差的加权和,就可以间接估计 latent code 与生成数据之间的互信息。
还有的实现代码是从分布的角度进行描述,假设 c c c 的连续部分服从标准正态分布 N ( 0 , I ) N(0,I) N(0,I),通过 Q(x) 得到的是高斯分布的均值和方差,通过让 Q(x) 得到的均值和方差向 Standard Normal Distribution 靠拢,来实现互信息的约束。
上面的两种方法都以一个共性,就是把 InfoGAN 的网络架构看作“传统GAN + AutoEncoder”,其中 G 和 Q 组成的自动编码器胜任了互信息的约束。AutoEncoder 属于无监督学习模型,因此通过InfoGAN就可以无监督的学习到潜在的类别特征及一些其他可解释性的特征。
刚接触InfoGAN,学识尚浅,如有不当之处,还望交流指正。
参考:
https://www.jiqizhixin.com/articles/2018-10-29-21
https://blog.csdn.net/u011699990/article/details/71599067