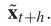什么是人工神经元算法
人工神经网络算法 “人工神经网络”(ARTIFICIAL NEURAL NETWORK,简称ANN)是在对人脑组织结构和运行机制的认识理解基础之上模拟其结构和智能行为的一种工程系统。
早在本世纪40年代初期,心理学家McCulloch、数学家Pitts就提出了人工神经网络的第一个数学模型,从此开创了神经科学理论的研究时代。
其后,F Rosenblatt、Widrow和J. J .Hopfield等学者又先后提出了感知模型,使得人工神经网络技术得以蓬勃发展。
神经系统的基本构造是神经元(神经细胞),它是处理人体内各部分之间相互信息传递的基本单元。据神经生物学家研究的结果表明,人的一个大脑一般有1010~1011个神经元。
每个神经元都由一个细胞体,一个连接其他神经元的轴突和一些向外伸出的其它较短分支——树突组成。轴突的功能是将本神经元的输出信号(兴奋)传递给别的神经元。
其末端的许多神经末梢使得兴奋可以同时传送给多个神经元。树突的功能是接受来自其它神经元的兴奋。
神经元细胞体将接受到的所有信号进行简单处理(如:加权求和,即对所有的输入信号都加以考虑且对每个信号的重视程度——体现在权值上——有所不同)后由轴突输出。
神经元的树突与另外的神经元的神经末梢相连的部分称为突触。
谷歌人工智能写作项目:神经网络伪原创

什么叫神经元神经元节点信息计算方法
隐层节点数在BP网络中,隐层节点数的选择非常重要,不仅对建立的神经网络模型的性能影响很大,而且是训练时出现“过拟合”的直接原因,但是目前理论上还没有一种科学的和普遍的确定方法文案狗。
神经元之间联系的基本方式是形成突触,突触由突触前膜、突触间隙和突触后膜构成,突触前膜内侧有大量线粒体和囊泡,不同类型突触所含囊泡的形态、大小及递质均不同。突触后膜上有递质作用的受体。
扩展资料:神经元也和其他类型的细胞一样,包括有细胞膜、细胞质和细胞核。但是神经细胞的形态比较特殊,具有许多突起,因此又分为细胞体、轴突和树突三部分。细胞体内有细胞核,突起的作用是传递信息。
树突是作为引入输入信号的突起,而轴突是作为输出端的突起,它只有一个。人工神经网络反映了人脑功能的若干基本特性,但并非生物系统的逼真描述,只是某种模仿、简化和抽象。
与数字计算机比较,人工神经网络在构成原理和功能特点等方面更加接近人脑,它不是按给定的程序一步一步地执行运算,而是能够自身适应环境、总结规律、完成某种运算、识别或过程控制。
参考资料来源:百度百科-神经网络算法。
神经网络算法是什么?
Introduction --------------------------------------------------------------------------------神经网络是新技术领域中的一个时尚词汇。
很多人听过这个词,但很少人真正明白它是什么。本文的目的是介绍所有关于神经网络的基本包括它的功能、一般结构、相关术语、类型及其应用。
“神经网络”这个词实际是来自于生物学,而我们所指的神经网络正确的名称应该是“人工神经网络(ANNs)”。在本文,我会同时使用这两个互换的术语。
一个真正的神经网络是由数个至数十亿个被称为神经元的细胞(组成我们大脑的微小细胞)所组成,它们以不同方式连接而型成网络。人工神经网络就是尝试模拟这种生物学上的体系结构及其操作。
在这里有一个难题:我们对生物学上的神经网络知道的不多!因此,不同类型之间的神经网络体系结构有很大的不同,我们所知道的只是神经元基本的结构。
The neuron --------------------------------------------------------------------------------虽然已经确认在我们的大脑中有大约50至500种不同的神经元,但它们大部份都是基于基本神经元的特别细胞。
基本神经元包含有synapses、soma、axon及dendrites。
Synapses负责神经元之间的连接,它们不是直接物理上连接的,而是它们之间有一个很小的空隙允许电子讯号从一个神经元跳到另一个神经元。
然后这些电子讯号会交给soma处理及以其内部电子讯号将处理结果传递给axon。而axon会将这些讯号分发给dendrites。
最后,dendrites带着这些讯号再交给其它的synapses,再继续下一个循环。如同生物学上的基本神经元,人工的神经网络也有基本的神经元。
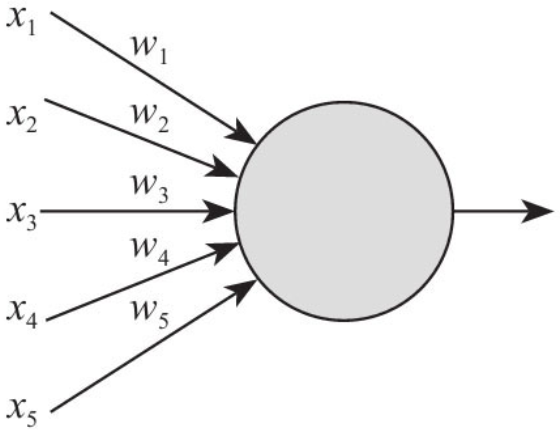
每个神经元有特定数量的输入,也会为每个神经元设定权重(weight)。权重是对所输入的资料的重要性的一个指标。
然后,神经元会计算出权重合计值(net value),而权重合计值就是将所有输入乘以它们的权重的合计。每个神经元都有它们各自的临界值(threshold),而当权重合计值大于临界值时,神经元会输出1。
相反,则输出0。最后,输出会被传送给与该神经元连接的其它神经元继续剩余的计算。
Learning --------------------------------------------------------------------------------正如上述所写,问题的核心是权重及临界值是该如何设定的呢?
世界上有很多不同的训练方式,就如网络类型一样多。但有些比较出名的包括back-propagation, delta rule及Kohonen训练模式。
由于结构体系的不同,训练的规则也不相同,但大部份的规则可以被分为二大类别 - 监管的及非监管的。监管方式的训练规则需要“教师”告诉他们特定的输入应该作出怎样的输出。
然后训练规则会调整所有需要的权重值(这是网络中是非常复杂的),而整个过程会重头开始直至数据可以被网络正确的分析出来。监管方式的训练模式包括有back-propagation及delta rule。
非监管方式的规则无需教师,因为他们所产生的输出会被进一步评估。
Architecture --------------------------------------------------------------------------------在神经网络中,遵守明确的规则一词是最“模糊不清”的。
因为有太多不同种类的网络,由简单的布尔网络(Perceptrons),至复杂的自我调整网络(Kohonen),至热动态性网络模型(Boltzmann machines)!
而这些,都遵守一个网络体系结构的标准。一个网络包括有多个神经元“层”,输入层、隐蔽层及输出层。输入层负责接收输入及分发到隐蔽层(因为用户看不见这些层,所以见做隐蔽层)。
这些隐蔽层负责所需的计算及输出结果给输出层,而用户则可以看到最终结果。现在,为免混淆,不会在这里更深入的探讨体系结构这一话题。
对于不同神经网络的更多详细资料可以看Generation5 essays尽管我们讨论过神经元、训练及体系结构,但我们还不清楚神经网络实际做些什么。
The Function of ANNs --------------------------------------------------------------------------------神经网络被设计为与图案一起工作 - 它们可以被分为分类式或联想式。
分类式网络可以接受一组数,然后将其分类。例如ONR程序接受一个数字的影象而输出这个数字。或者PPDA32程序接受一个坐标而将它分类成A类或B类(类别是由所提供的训练决定的)。
更多实际用途可以看Applications in the Military中的军事雷达,该雷达可以分别出车辆或树。联想模式接受一组数而输出另一组。
例如HIR程序接受一个‘脏’图像而输出一个它所学过而最接近的一个图像。联想模式更可应用于复杂的应用程序,如签名、面部、指纹识别等。
The Ups and Downs of Neural Networks --------------------------------------------------------------------------------神经网络在这个领域中有很多优点,使得它越来越流行。
它在类型分类/识别方面非常出色。神经网络可以处理例外及不正常的输入数据,这对于很多系统都很重要(例如雷达及声波定位系统)。很多神经网络都是模仿生物神经网络的,即是他们仿照大脑的运作方式工作。
神经网络也得助于神经系统科学的发展,使它可以像人类一样准确地辨别物件而有电脑的速度!前途是光明的,但现在...是的,神经网络也有些不好的地方。这通常都是因为缺乏足够强大的硬件。
神经网络的力量源自于以并行方式处理资讯,即是同时处理多项数据。因此,要一个串行的机器模拟并行处理是非常耗时的。
神经网络的另一个问题是对某一个问题构建网络所定义的条件不足 - 有太多因素需要考虑:训练的算法、体系结构、每层的神经元个数、有多少层、数据的表现等,还有其它更多因素。
因此,随着时间越来越重要,大部份公司不可能负担重复的开发神经网络去有效地解决问题。
NN 神经网络,Neural Network ANNs 人工神经网络,Artificial Neural Networks neurons 神经元 synapses 神经键 self-organizing networks 自我调整网络 networks modelling thermodynamic properties 热动态性网络模型 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++网格算法我没听说过好像只有网格计算这个词网格计算是伴随着互联网技术而迅速发展起来的,专门针对复杂科学计算的新型计算模式。
这种计算模式是利用互联网把分散在不同地理位置的电脑组织成一个“虚拟的超级计算机”,其中每一台参与计算的计算机就是一个“节点”,而整个计算是由成千上万个“节点”组成的“一张网格”, 所以这种计算方式叫网格计算。
这样组织起来的“虚拟的超级计算机”有两个优势,一个是数据处理能力超强;另一个是能充分利用网上的闲置处理能力。
简单地讲,网格是把整个网络整合成一台巨大的超级计算机,实现计算资源、存储资源、数据资源、信息资源、知识资源、专家资源的全面共享。
神经网络算法原理
4.2.1 概述人工神经网络的研究与计算机的研究几乎是同步发展的。
1943年心理学家McCulloch和数学家Pitts合作提出了形式神经元的数学模型,20世纪50年代末,Rosenblatt提出了感知器模型,1982年,Hopfiled引入了能量函数的概念提出了神经网络的一种数学模型,1986年,Rumelhart及LeCun等学者提出了多层感知器的反向传播算法等。
神经网络技术在众多研究者的努力下,理论上日趋完善,算法种类不断增加。目前,有关神经网络的理论研究成果很多,出版了不少有关基础理论的著作,并且现在仍是全球非线性科学研究的热点之一。
神经网络是一种通过模拟人的大脑神经结构去实现人脑智能活动功能的信息处理系统,它具有人脑的基本功能,但又不是人脑的真实写照。它是人脑的一种抽象、简化和模拟模型,故称之为人工神经网络(边肇祺,2000)。
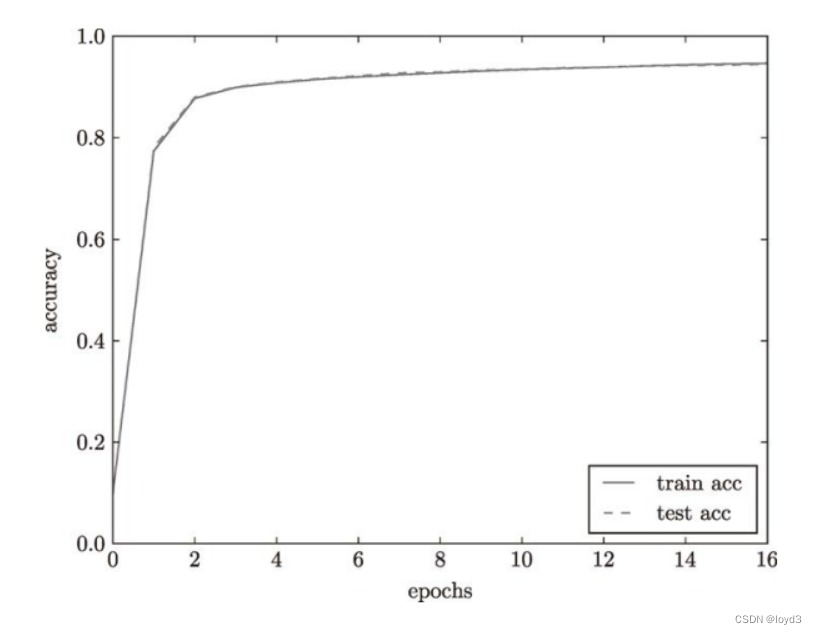
人工神经元是神经网络的节点,是神经网络的最重要组成部分之一。目前,有关神经元的模型种类繁多,最常用最简单的模型是由阈值函数、Sigmoid 函数构成的模型(图 4-3)。
图4-3 人工神经元与两种常见的输出函数神经网络学习及识别方法最初是借鉴人脑神经元的学习识别过程提出的。
输入参数好比神经元接收信号,通过一定的权值(相当于刺激神经兴奋的强度)与神经元相连,这一过程有些类似于多元线性回归,但模拟的非线性特征是通过下一步骤体现的,即通过设定一阈值(神经元兴奋极限)来确定神经元的兴奋模式,经输出运算得到输出结果。
经过大量样本进入网络系统学习训练之后,连接输入信号与神经元之间的权值达到稳定并可最大限度地符合已经经过训练的学习样本。
在被确认网络结构的合理性和学习效果的高精度之后,将待预测样本输入参数代入网络,达到参数预测的目的。
4.2.2 反向传播算法(BP法)发展到目前为止,神经网络模型不下十几种,如前馈神经网络、感知器、Hopfiled 网络、径向基函数网络、反向传播算法(BP法)等,但在储层参数反演方面,目前比较成熟比较流行的网络类型是误差反向传播神经网络(BP-ANN)。
BP网络是在前馈神经网络的基础上发展起来的,始终有一个输入层(它包含的节点对应于每个输入变量)和一个输出层(它包含的节点对应于每个输出值),以及至少有一个具有任意节点数的隐含层(又称中间层)。
在 BP-ANN中,相邻层的节点通过一个任意初始权值全部相连,但同一层内各节点间互不相连。
对于 BP-ANN,隐含层和输出层节点的基函数必须是连续的、单调递增的,当输入趋于正或负无穷大时,它应该接近于某一固定值,也就是说,基函数为“S”型(Kosko,1992)。
BP-ANN 的训练是一个监督学习过程,涉及两个数据集,即训练数据集和监督数据集。
给网络的输入层提供一组输入信息,使其通过网络而在输出层上产生逼近期望输出的过程,称之为网络的学习,或称对网络进行训练,实现这一步骤的方法则称为学习算法。
BP网络的学习过程包括两个阶段:第一个阶段是正向过程,将输入变量通过输入层经隐层逐层计算各单元的输出值;第二阶段是反向传播过程,由输出误差逐层向前算出隐层各单元的误差,并用此误差修正前层权值。
误差信息通过网络反向传播,遵循误差逐步降低的原则来调整权值,直到达到满意的输出为止。
网络经过学习以后,一组合适的、稳定的权值连接权被固定下来,将待预测样本作为输入层参数,网络经过向前传播便可以得到输出结果,这就是网络的预测。
反向传播算法主要步骤如下:首先选定权系数初始值,然后重复下述过程直至收敛(对各样本依次计算)。
(1)从前向后各层计算各单元Oj储层特征研究与预测(2)对输出层计算δj储层特征研究与预测(3)从后向前计算各隐层δj储层特征研究与预测(4)计算并保存各权值修正量储层特征研究与预测(5)修正权值储层特征研究与预测以上算法是对每个样本作权值修正,也可以对各个样本计算δj后求和,按总误差修正权值。
卷积神经网络算法是什么?
一维构筑、二维构筑、全卷积构筑。
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)”。
卷积神经网络的连接性:卷积神经网络中卷积层间的连接被称为稀疏连接(sparse connection),即相比于前馈神经网络中的全连接,卷积层中的神经元仅与其相邻层的部分,而非全部神经元相连。
具体地,卷积神经网络第l层特征图中的任意一个像素(神经元)都仅是l-1层中卷积核所定义的感受野内的像素的线性组合。
卷积神经网络的稀疏连接具有正则化的效果,提高了网络结构的稳定性和泛化能力,避免过度拟合,同时,稀疏连接减少了权重参数的总量,有利于神经网络的快速学习,和在计算时减少内存开销。
卷积神经网络中特征图同一通道内的所有像素共享一组卷积核权重系数,该性质被称为权重共享(weight sharing)。
权重共享将卷积神经网络和其它包含局部连接结构的神经网络相区分,后者虽然使用了稀疏连接,但不同连接的权重是不同的。权重共享和稀疏连接一样,减少了卷积神经网络的参数总量,并具有正则化的效果。
在全连接网络视角下,卷积神经网络的稀疏连接和权重共享可以被视为两个无限强的先验(pirior),即一个隐含层神经元在其感受野之外的所有权重系数恒为0(但感受野可以在空间移动);且在一个通道内,所有神经元的权重系数相同。
神经网络输出神经元个数怎么确定
如果是RBF神经网络,那么只有3层,输入层,隐含层和输出层。确定神经元个数的方法有K-means,ROLS等算法。
现在还没有什么成熟的定理能确定各层神经元的神经元个数和含有几层网络,大多数还是靠经验,不过3层网络可以逼近任意一个非线性网络,神经元个数越多逼近的效果越好。
神经网络可以指向两种,一个是生物神经网络,一个是人工神经网络。生物神经网络:一般指生物的大脑神经元,细胞,触点等组成的网络,用于产生生物的意识,帮助生物进行思考和行动。
人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。人工神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
在工程与学术界也常直接简称为“神经网络”或类神经网络。
神经网络算法可以解决的问题有哪些
人工神经网络(Artificial Neural Networks,ANN)系统是 20 世纪 40 年代后出现的。
它是由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信 息存储、良好的自组织自学习能力等特点。
BP(Back Propagation)算法又称为误差 反向传播算法,是人工神经网络中的一种监督式的学习算法。
BP 神经网络算法在理 论上可以逼近任意函数,基本的结构由非线性变化单元组成,具有很强的非线性映射能力。
而且网络的中间层数、各层的处理单元数及网络的学习系数等参数可根据具体情况设定,灵活性很大,在优化、信号处理与模式识别、智能控制、故障诊断等许 多领域都有着广泛的应用前景。
工作原理人工神经元的研究起源于脑神经元学说。19世纪末,在生物、生理学领域,Waldeger等人创建了神经元学说。人们认识到复杂的神经系统是由数目繁多的神经元组合而成。
大脑皮层包括有100亿个以上的神经元,每立方毫米约有数万个,它们互相联结形成神经网络,通过感觉器官和神经接受来自身体内外的各种信息,传递至中枢神经系统内,经过对信息的分析和综合,再通过运动神经发出控制信息,以此来实现机体与内外环境的联系,协调全身的各种机能活动。
神经元也和其他类型的细胞一样,包括有细胞膜、细胞质和细胞核。但是神经细胞的形态比较特殊,具有许多突起,因此又分为细胞体、轴突和树突三部分。细胞体内有细胞核,突起的作用是传递信息。
树突是作为引入输入信号的突起,而轴突是作为输出端的突起,它只有一个。树突是细胞体的延伸部分,它由细胞体发出后逐渐变细,全长各部位都可与其他神经元的轴突末梢相互联系,形成所谓“突触”。
在突触处两神经元并未连通,它只是发生信息传递功能的结合部,联系界面之间间隙约为(15~50)×10米。突触可分为兴奋性与抑制性两种类型,它相应于神经元之间耦合的极性。
每个神经元的突触数目正常,最高可达10个。各神经元之间的连接强度和极性有所不同,并且都可调整、基于这一特性,人脑具有存储信息的功能。利用大量神经元相互联接组成人工神经网络可显示出人的大脑的某些特征。
人工神经网络是由大量的简单基本元件——神经元相互联接而成的自适应非线性动态系统。每个神经元的结构和功能比较简单,但大量神经元组合产生的系统行为却非常复杂。
人工神经网络反映了人脑功能的若干基本特性,但并非生物系统的逼真描述,只是某种模仿、简化和抽象。
与数字计算机比较,人工神经网络在构成原理和功能特点等方面更加接近人脑,它不是按给定的程序一步一步地执行运算,而是能够自身适应环境、总结规律、完成某种运算、识别或过程控制。
人工神经网络首先要以一定的学习准则进行学习,然后才能工作。现以人工神经网络对于写“A”、“B”两个字母的识别为例进行说明,规定当“A”输入网络时,应该输出“1”,而当输入为“B”时,输出为“0”。
所以网络学习的准则应该是:如果网络作出错误的的判决,则通过网络的学习,应使得网络减少下次犯同样错误的可能性。
首先,给网络的各连接权值赋予(0,1)区间内的随机值,将“A”所对应的图象模式输入给网络,网络将输入模式加权求和、与门限比较、再进行非线性运算,得到网络的输出。
在此情况下,网络输出为“1”和“0”的概率各为50%,也就是说是完全随机的。这时如果输出为“1”(结果正确),则使连接权值增大,以便使网络再次遇到“A”模式输入时,仍然能作出正确的判断。
神经网络算法可以解决的问题有哪些。