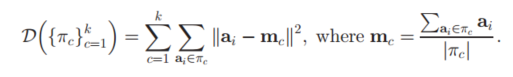前段时间把en.wikipedia.org里关于K-means clustering算法的条目翻译了一下,搬到了zh.wikipedia.org里的条目“K-平均算法”下。
后来组内讨论的时候又重新整理了一下要用的内容,放到博客上来吧。
因为打算写一篇K-均值算法下自学习距离度量(distance metric)的文章,还需要有K-均值算法的内容作为铺垫。
本文名为K-均值算法简介,除包含算法内容以外,还包含了K-均值算法的来源、关于K-均值算法的不同视角,以及应用和优缺点方面的内容。
一、算法描述
已知观测集 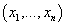
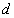
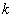
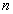
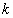
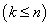
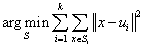
其中
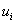 是
是
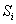 中所有点的均值。
中所有点的均值。
注:这个 问题本身是NP-难的,所以出现了K-均值这样的启发式算法来求解。
1.1初始化
通常使用的初始化方法有Forgy和随机划分(Random Partition)方法:
(1)Forgy方法随机地从数据集中选择 个观测点作为初始的均值点;
(2)随机划分方法则随机地为每一观测指定所属聚类,然后运行“更新(Update)”步骤,计算随机分配的各聚类的图心,作为初始的均值点。
特点:Forgy方法易于使得初始均值点散开,随机划分方法则把均值点都放到靠近数据集中心的地方。
适用性:随机划分方法一般更适用于K-调和均值和模糊K-均值算法;Forgy方法更适用于期望-最大化(EM)算法和标准K-均值算法。
K-均值是一个启发式算法,无法保证收敛到全局最优解,并且聚类的结果会依赖于初始的聚类。又因为算法的运行速度通常很快,所以一般都以不同的起始状态运行多次来得到更好的结果。
1.2运行时
已知初始的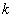
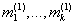
分配(Assignment):
将每个观测分配到聚类中,使得组内平方和(WCSS)达到最小。
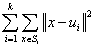
因为这一平方和就是平方后的欧氏距离,所以很把观测点分配到离它最近的均值点即可:
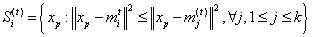
(数学上,这意味依照由这些均值点生成的Voronoi图来划分上述观测点)
其中每个
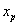 都只被分配到一个确定的聚类
都只被分配到一个确定的聚类
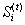 中(在理论上它可能被分配到2个或者更多的聚类中)。
中(在理论上它可能被分配到2个或者更多的聚类中)。
更新(Update):
计算上步得到的聚类中,每一聚类观测点的图心,作为新的均值点。
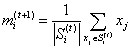
因为算术平均是最小平方估计,所以这一步同样减小了目标函数组内平方和(WCSS)的值。
这一算法将在对于观测的分配不再变化时收敛。由于交替进行的两个步骤都会减小目标函数WCSS的值,并且分配方案只有有限种,所以算法一定会收敛于某一(局部)最优解。
注意:使用这一算法无法保证得到全局最优解。
算法为把观测点分配到距离最近的聚类。
目标函数是组内平方和(WCSS),而且按照“最小平方和”来分配观测,确实是等价于按照最小欧氏距离来分配观测的。
如果使用不同的距离函数来代替(平方)欧氏距离,可能使得算法无法收敛。然而,使用不同的距离函数,也能得到K-均值聚类的其他变体,如球体K-均值算法和K-中心点算法。
二、算法思想[1]
算法的思想可以追溯到1957年,术语“K-均值”在1967年被首次使用。不过,标准算法其实是由Stuart Lloyd在1957年,作为一种脉冲编码调制技术提出的(但1982年才被AT&T实验室公开出版)。在1965年,E.W.Forgy发表了本质上相同的方法,所以这一算法有时被称为Lloyd-Forgy方法。
下面是问题原型:
脉冲编码调制就是把一个时间连续,取值连续的模拟信号变换成时间离散,取值离散的数字信号后在信道中传输。即对模拟信号先抽样,再对样值幅度量化,编码的过程。
给定一些要处理的信号,那些量化之后的值应该与……
It has long been realized that in pulse-code modulation(PCM), with a given ensemble of signals to handle, the quantum values should be spaced more closely in the voltage regions where the signal amplitude is more likely to fall.
也就是说,这其实是一个聚类问题:对于整个电压轴,需要找出
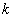
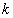
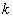
三、视角
3.1 可视为期望-最大化算法的特例
“分配”—即—“期望”
“更新”—即—“最大化”
可以看到,这一算法实际上是广义期望-最大化算法(GEM)的一个变体。
3.2 可视为空间划分的Voronoi图
链接到网页[3]。
3.3 与其它统计机器学习方法的关系
K-均值问题很容易就能一般化为高斯混合模型,另一个K-均值算法的推广则是K-SVD算法。后者把数据点视为“编码本向量”的稀疏线性组合,而K-均值对应于使用单编码本向量的特殊情形。
此外,K-均值算法还与下列方法有一定联系:
(1)Mean Shift 聚类
基本的Mean Shift聚类要维护一个与输入数据集规模大小相同的数据点集。初始时,这一集合就是输入集的副本。然后对于每一个点,用一定距离范围内的所有点的均值来迭代地替换它。与之对比,K-均值把这样的迭代更新限制在(通常比输入数据集小得多的)K个点上,而更新这些点时,则利用了输入集中与之相近的所有点的均值。
还有一种与K-均值类似的Mean shift算法,即似然Mean shift,对于迭代变化的集合,用一定距离内在输入集中所有点的均值来更新集合里的点。
(2)主成分分析(PCA)
有研究表明,K-均值的放松形式解(由聚类指示向量表示),可由主成分分析中的主成分给出。
且主成分分析中,主方向张成的子空间与聚类图心空间是等价的。不过,主成分分析是K-均值聚类的有效放松形式并不是一个新的结果,并且还有研究结果直接给出了关于“聚类图心子空间是由主成分方向张成的”这一论述的反例。
(3)独立成分分析(ICA)
在稀疏假设下以及输入数据经过白化处理后,K-均值得到的解就是独立成分分析的解。这一结果对于解释K-均值在特征学习方面的成功应用很有帮助。
(4)双向过滤
K-均值算法隐含地假设输入数据的顺序不影响结果。双向过滤与K-均值算法和Mean shift算法类似之处在于它同样维护着一个迭代更新的数据集(亦是被均值更新)。
然而,双向过滤限制了均值的计算只包含了在输入数据中顺序相近的点,这使得双向过滤能够被应用在空间安排非常重要的图像去噪等问题中。
四、应用与优缺点
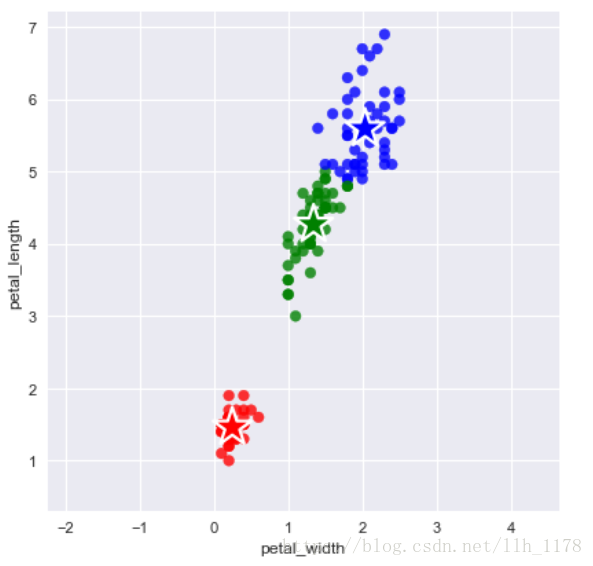
K-均值算法在向量量化、聚类分析、特征学习、计算机视觉等领域都有应用,也经常作为其他算法的预处理步骤使用。
使K-均值算法效率高的两个关键特点同时也常被视为它最大的缺陷:
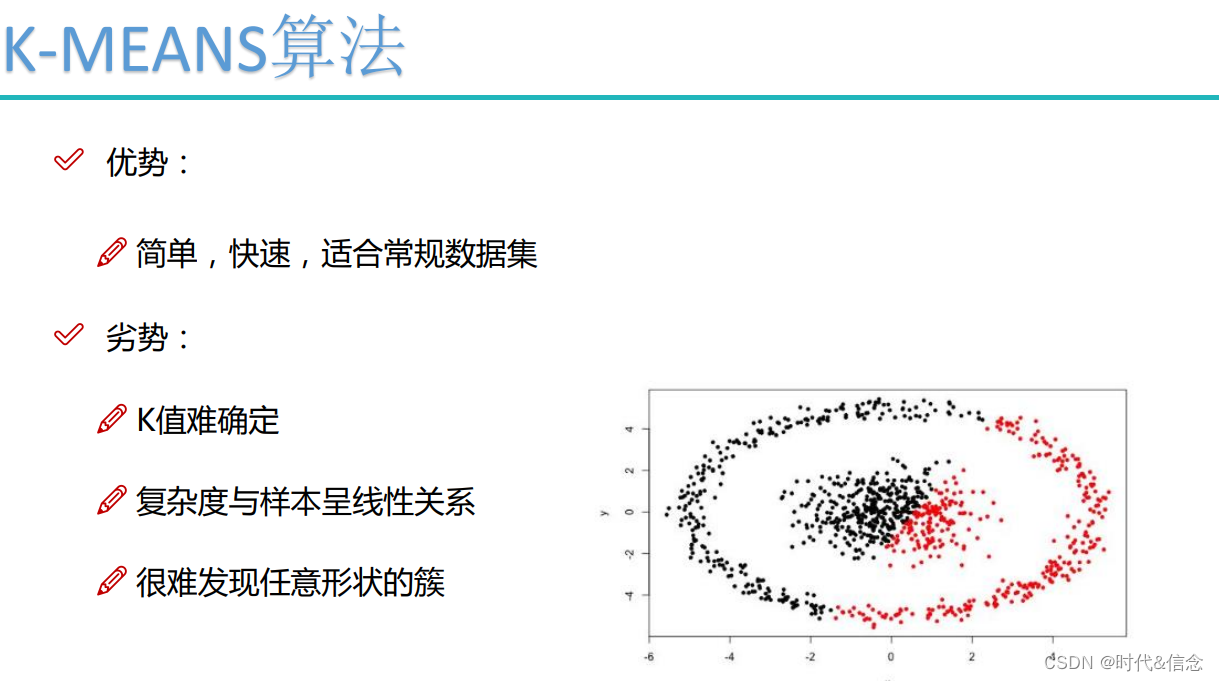
(1)聚类数目k是一个输入参数。选择不恰当的k值可能会导致糟糕的聚类结果。这也是为什么要进行特征检查来决定数据集的聚类数目了。
(2)收敛到局部最优解,可能导致与直觉相反的错误结果。
K-均值算法的一个重要的局限性在于它的聚类模型:
这一模型的基本思想在于:得到相互分离的球状聚类,在这些聚类中,均值点趋向收敛于聚类中心。 一般会希望得到的聚类大小大致相当,这样把每个观测都分配到离它最近的均值点对应的聚类就是正确的分配方案。
五、其他[2]
- K-均值算法的变体
- 复杂度
参考文献
[1]STUART P. LLOYD.Least Squares Quantization in PCM[J].IEEE TRANSACTIONSON INFORMATION THEORY, 1982, IT-28(2):129-138.
[2]维基百科.K-平均算法[EB/OL].2015[2015-4-8].http://zh.wikipedia.org/zh/K%E5%B9%B3%E5%9D%87%E7%AE%97%E6%B3%95.
[3]VoronoiDiagram[EB/OL].[2015-4-8].
http://www.csie.ntnu.edu.tw/~u91029/VoronoiDiagram.html.