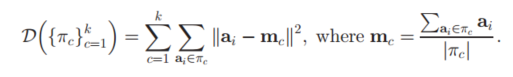算法说明
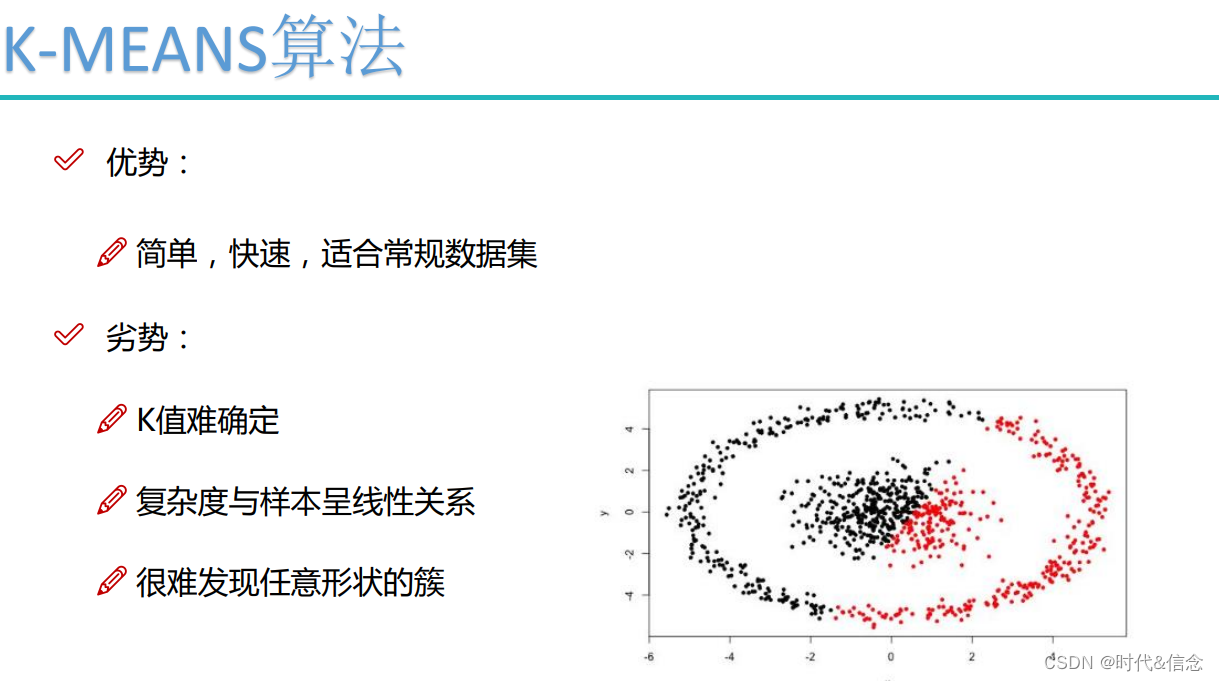
K均值聚类算法其实就是根据距离来看属性,近朱者赤近墨者黑。其中K表示要聚类的数量,就是说样本要被划分成几个类别。而均值则是因为需要求得每个类别的中心点,比如一维样本的中心点一般就是求这些样本的算术平均数。
这里存在一个问题了,在最开始我并不知道哪个样本属于哪个类别,那么我怎么能求出中心点呢?如何去划分类别呢?既然是无监督的算法,肯定是没有结果来做训练的。
算法思想
首先最开始的类别数K我们需要先指定,这个一般根据实际情况来给定。
K Means算法原理:
在已知K的情况下,我们先随机指定K个样本为这K个类别的中心点,然后去计算所有样本与这个K个中心的距离,样本离哪个中心点近,我们就认为这个样本和这个中心点属于同一个类别,这样我们就将所有样本划分成了K份。然后我们去计算已经划分的每个类别的平均值作为新的中心,重复刚才的操作继续将所有样本划分类别,直到新的中心点已经足够接近实际的平均值了。一般认为是它已经变化不明显的时候。
我们在一开始说随机指定,但在实际应用中并不是随机去指定起始的中心的,因为这会影响最后聚类的效果,我们一般会选择距离最远的几个样本作为起始中心,至于原理不清楚。而所计算的距离一般是欧式距离,当然也可以指定其他距离作为计算。
这个算法很简单,我们完全可以自己用Python实现一个聚类器,这样可以加深对算法的理解,具体请参考https://www.cnblogs.com/listenfwind/p/9911561.html。
案例
我在实际操作中遇到这样一个问题。在一堆URL中如何区分是列表页还是详情页?这本来是一个分类问题,但实际上可以用聚类的思想来解决,因为正常情况下列表页是小于详情页的,所以我只需聚类为两个类别,多的一方就是详情页了。
首先我们找到一堆的URL,随便选择一个新闻网站的首页(选择新闻网站的目的有两个,第一是新闻网站列表页和详情页区分比较明确,第二我遇到的问题实际上就是针对新闻网站的),用//a/@href就可以提出网页所有的URL了。
那就以某某头条为例,为了让详情页更多一点,我先下滑几次在提出所有URL,经过去重和去头(为了减少计算量)后总共196条,经过观察发现有些链接包含锚点,这个也是影响因素需要去除,处理后的数据如下:
["complain/",
"ch/news_hot/",
"ch/news_image/",
"ch/news_tech/",
"ch/news_entertainment/",
"ch/news_game/",
"ch/news_sports/",
"ch/news_finance/",
"ch/funny/",
"ch/news_military/",
"ch/news_world/",
"ch/news_fashion/",
"ch/news_travel/",
"ch/news_discovery/",
"ch/news_baby/",
"ch/news_regimen/",
"ch/news_essay/",
"ch/news_history/",
"ch/news_food/",
"group/6772361797107188228/",
"search/?keyword=%E6%97%B6%E6%94%BF",
"c/user/token/MS4wLjABAAAAP09LrX61xFpIWrgGdBDqkp-5om9Lans_kuIZ_ipAGRE/",
"group/6772361797107188228//",
"group/6772263443085918733/",
"search/?keyword=%E6%95%99%E8%82%B2",
"c/user/token/MS4wLjABAAAA6Ftyf-tftfbjp1u_TEz6kpY77ZlPaYRV0UsfXkF2UsM/",
"group/6772263443085918733//",
"group/6772351056622912007/",
"c/user/token/MS4wLjABAAAAa4jZTw8oFVgiBHDJk10547ATPToNthylT4jZwY2ik1w/",
"group/6772351056622912007//",
"group/6771237220582949380/",
"news_society",
"c/user/token/MS4wLjABAAAAX48WhqFh4ZlMkKgEZnGBoXUx0zeI5BcDWJ4OzPJGSPc/",
"group/6771237220582949380//",
"group/6772066939926741518/",
"news_world",
"c/user/token/MS4wLjABAAAAOXfnKLIKxnJ7JRLpqpNjMyrwCqgsRlwHyEZq0p4YChs/",
"group/6772066939926741518//",
"group/6772323191109976583/",
"search/?keyword=%E6%91%84%E5%BD%B1",
"c/user/token/MS4wLjABAAAA_Jz2pdlbw4TBZcLU7LsLshugPcU3fhZJBtPIrSnpHqc/",
"group/6772323191109976583//",
"group/6772320361343091214/",
"c/user/token/MS4wLjABAAAAvazHMceCo3MeM9IJbll231AC8GkJDcrd__iZFw2hi4o/",
"group/6772320361343091214//",
"group/6772151050703995405/",
"c/user/token/MS4wLjABAAAA2-a42jcCrjxiaPdxJ-H8uPjQMXUZ9bKfc4A19l_W100/",
"group/6772151050703995405//",
"group/6772385639112376839/",
"news_military",
"group/6772385639112376839//",
"group/6771748311419322894/",
"news_entertainment",
"c/user/token/MS4wLjABAAAAhAKK7LCl_xBflEJTPy1wesrlqc3Kha8jRxiU3-fIR4A/",
"group/6771748311419322894//",
"group/6772052998580339203/",
"news_essay",
"c/user/token/MS4wLjABAAAAa1oH7xLE2_jMJY69c_Ku7N9jghYdyads-KTwC_O4yRY/",
"group/6772052998580339203//",
"group/6763220871336165902/",
"news_baby",
"c/user/token/MS4wLjABAAAAoUxm_l1pll0rl7YbzRs2DYvCF43zhqraHPB3tRt31xs/",
"group/6763220871336165902//",
"group/6772052257421656587/",
"c/user/token/MS4wLjABAAAAq9HewtKfV2PkxOJki10cNTsolSg7v49ZfK9SgjW3tVI/",
"group/6772052257421656587//",
"group/6767265813985493512/",
"c/user/token/MS4wLjABAAAAWvKmt6iRkkdPOAy2nW9weNVHDy5ALwEPbD3i_LP0ll0/",
"group/6767265813985493512//",
"group/6772327266912305677/",
"search/?keyword=%E4%BC%A0%E5%AA%92",
"group/6772327266912305677//",
"group/6772076545138754059/",
"c/user/token/MS4wLjABAAAAW5brp6MGo0YZBvUMIkKcv1seF48r0FqTdDytfflPZLc/",
"group/6772076545138754059//",
"group/6760618370665545997/",
"news_tech",
"c/user/token/MS4wLjABAAAAvcmuAjmIREb3PslmhNCTj9uAImPNsEqhJs_Ku5Iu2eI/",
"group/6760618370665545997//",
"group/6772342657982136835/",
"c/user/token/MS4wLjABAAAAkhsrroV99JNDoAbxTbYCbHwA0h8gvCcrG9FIMqjZrPw/",
"group/6772342657982136835//",
"group/6771996344211997198/",
"c/user/token/MS4wLjABAAAAs0318h_M05o0X1gOx256e65RwmneiXgRpVwQMtFmPO4/",
"group/6771996344211997198//",
"group/6771633794106524168/",
"group/6771633794106524168//",
"group/6772357820948939275/",
"c/user/token/MS4wLjABAAAAJCwQwGTZntQ4gPhah3rAbUbzGGfP3VyQ_8a1wf4khqs/",
"group/6772357820948939275//",
"group/6772082352932782596/",
"c/user/token/MS4wLjABAAAABKCVGCTavubanOWlP5mCy2CEJ0MW4i5zd9HBYbXZrPo/",
"group/6772082352932782596//",
"group/6771951110539182596/",
"search/?keyword=%E6%83%85%E6%84%9F",
"c/user/token/MS4wLjABAAAAed3H7aKDz5JrhsEgg_jhNo1yAbbPLlKGLO6rdZ0OwgA/",
"group/6771951110539182596//",
"group/6770851310502674951/",
"group/6770851310502674951//",
"group/6772340719047672333/",
"c/user/token/MS4wLjABAAAAhleU_I4Dyq6lGTroUFhL7u07Sme3FBF0IzlIvstjAconpD4GP9bcpOYCLcSKY9dG/",
"group/6772340719047672333//",
"group/6772335014072812045/",
"group/6772335014072812045//",
"group/6762014132725088781/",
"search/?keyword=%E8%81%8C%E5%9C%BA",
"c/user/token/MS4wLjABAAAA9Lz0MeLdJDmqpU26Xi9O_M-cYI9z530wjM7eDKvzZTw/",
"group/6762014132725088781//",
"group/6771675554060960263/",
"group/6771675554060960263//",
"group/6772000767009096204/",
"c/user/token/MS4wLjABAAAAvT19CE0lGC6a7YSbIdcgElbhU4U8tGSKwH44yNPQJ1A/",
"group/6772000767009096204//",
"group/6767586635203740167/",
"group/6767586635203740167//",
"group/6771265100700451336/",
"news_sports",
"c/user/token/MS4wLjABAAAAqiBBLOaIZZuQ96FY6WsTsnL2X7NJZGNqHPd3W2IMOM6ZNQSRObFB6d7a4uZq76DV/",
"group/6771265100700451336//",
"group/6772339427151708680/",
"group/6772339427151708680//",
"group/6772095469431554574/",
"group/6772095469431554574//",
"group/6756141846214214152/",
"news_health",
"c/user/token/MS4wLjABAAAAuTdxeswYIRb0iF7f1sp1Ayyja48nFyh9W6IYWgBORBY/",
"group/6756141846214214152//",
"group/6750806035163775501/",
"news_history",
"c/user/token/MS4wLjABAAAAmWvemddiJQ3NFVq-fsAdyD7L2vP8QXwWNv91sIxThvM/",
"group/6750806035163775501//",
"group/6769822736643523079/",
"group/6769822736643523079//",
"group/6771051458608497156/",
"c/user/token/MS4wLjABAAAAYHBN9OQKyf6cRPh1kOkg0pxeZ6Ddd0Syy6HzS01XAcg/",
"group/6771051458608497156//",
"group/6753429047511876100/",
"group/6753429047511876100//",
"group/6770504135067304456/",
"c/user/token/MS4wLjABAAAA3n46_9F9yBPqXz1VtBYSjVN6so-1XsebySYNTFYm_rk/",
"group/6770504135067304456//",
"group/6771672850416796171/",
"c/user/token/MS4wLjABAAAA4iyuW9Y-2XuPBhGCb7P7H7rJsrr0zBSeZWTL7GNFLZ0/",
"group/6771672850416796171//",
"group/6772325923795501572/",
"news_food",
"c/user/token/MS4wLjABAAAAUtwZYU_H1eQI241W8frJvFJAOOg3ridYOLllshfDMDo/",
"group/6772325923795501572//",
"group/6772411865789104648/",
"group/6772411865789104648//",
"group/6747475934435082500/",
"c/user/token/MS4wLjABAAAAH5WqaLUBRCuQFZxW_Z-_1UneClDhue_bWbxspvIDG0I/",
"group/6747475934435082500//",
"group/6769833806087062030/",
"news_car",
"group/6769833806087062030//",
"group/6761423665880891915/",
"c/user/token/MS4wLjABAAAAdvG-5QlDX6a5LK4UlUfjZijLwZjQ4EY1MLQmUP-MLLQ/",
"group/6761423665880891915//",
"group/6772291799340810760/",
"group/6772291799340810760//",
"group/6772422866760630797/",
"group/6772422866760630797//",
"group/6772146332015526407/",
"c/user/token/MS4wLjABAAAAZrBCawOIX9AQhhbGqsoonR91THQ8gtzVn4dNl5ZmjMI/",
"group/6772146332015526407//",
"group/6768439447143842307/",
"c/user/token/MS4wLjABAAAACypHtQ3e7zQlqqvRn8Jt7gtz5ZgYHVfa1gWUc594KXY/",
"group/6768439447143842307//",
"group/6772388981897167374/",
"group/6772388981897167374//",
"group/6772413207622451723/",
"group/6772307520967934477/",
"group/6772346171089224195/",
"group/1653410007620612/",
"group/6764700745963930119/",
"group/6739082636314018311/",
"group/6772365453856604686/",
"group/6772336329180054027/",
"group/6748073310543675912/",
"group/6772169189479154183/",
"group/6758949786176455175/",
"group/6760264790842540558/",
"about/",
"report/",
"media_partners/",
"cooperation/",
"media_cooperation/",
"contact/",
"user_agreement/",
"privacy_protection/",
"complain/",
"corrupt_report/",
"license/",
"business_license/",
"a3642705768/",
]
到了这一步,新问题又来了。这些都是字符串啊,如何计算彼此间的距离呢,显然欧式距离是行不通的。经过一番搜索,计算字符串的距离应用比较广泛的有两种:编辑距离和余弦距离。
编辑距离:编辑距离算法是根据单个字符来比较的,是一个字符串替换成另一个字符串的难度系数, 对距离很敏感. 两个句子中的字词一样, 但是位置变化, 编辑距离算出来的相似的也变化。
余弦距离:余弦相似度是一词为单位的, 对距离不敏感. "中国你好"和"你好中国"的相似度是1, 因为他们包含相同的词语且词语数量一样.
根据两个距离的计算方式,我直接选择了编辑距离用来计算URL的相似度,因为/ac/和/ca/两个URL是不一样的,所有需要算法对位置敏感。
def edit_distance(str1, str2):len_str1 = len(str1) + 1len_str2 = len(str2) + 1# 创建矩阵matrix = [0 for n in range(len_str1 * len_str2)]#矩阵的第一行for i in range(len_str1):matrix[i] = i# 矩阵的第一列for j in range(0, len(matrix), len_str1):if j % len_str1 == 0:matrix[j] = j // len_str1# 根据状态转移方程逐步得到编辑距离for i in range(1, len_str1):for j in range(1, len_str2):if str1[i-1] == str2[j-1]:cost = 0else:cost = 1matrix[j*len_str1+i] = min(matrix[(j-1)*len_str1+i]+1,matrix[j*len_str1+(i-1)]+1,matrix[(j-1)*len_str1+(i-1)] + cost)return matrix[-1]
既然距离选择好了,那么如何实现算法呢,前面说了算法是先开始随机选择中心然后聚类之后再计算新的中心,问题来了,虽然可以通过编辑距离聚类所有URL,但是如何计算新的中心呢?怎么对URL做算术平均数呢?从数据上看是一维数据,那么能不能用编辑距离将URL映射到一维坐标上呢?应该不能,因为会产生矛盾,字符串’a’到’b’的编辑距离是1,字符串’b’到’c’的编辑距离也是1,'b’到’d’的编辑距离同样是1,而在一维坐标轴上,到同一点的距离相同的只有两种可能,所以这就矛盾了。
在解答这个思路之前,我们先解两道题
第一题:已经字符串a(变量a,不是字符’a’)和字符串b的编辑距离是3,字符串b和字符串c的编辑距离也是3,问字符串a和字符串c的编辑距离?应该是3-6,如果我想的没错的话。从b到a需要增删改三次操作,而从b到c也是增删改三次操作,如果这两个的操作相同或者接近的话,那么b到c也只需要三次;如果这两个操作完全不同,则b到c需要进行3+3次操作。
第二题:已经字符串a和字符串列表L中所有元素编辑距离之和为10,字符串b与L中所有元素编辑距离之和也为10,求a和b的编辑距离最大值。应该是20,当L只有一个元素时取得最大值,原理同上一题。当L元素个数逐渐增大时,a和b的距离逐渐缩小。
结论:如果a、b与L的所有元素距离之和接近,并且L元素个数足够大,我们认为a和b的距离也足够接近。
PS:以上两道题和结论只是我临时想出来的,如果有错误,还请指出。
那么这就引出了我的解决方案:
我们将URL本身作为a,其余URL作为L,计算a与L内所有元素的编辑距离之和,这个值就作为a的特征值。于是我们可以得到下面的一维数组,元素全部都是整数,这就是我们的样本数据。后面只要稍微处理一下,扔到k均值聚类器中就能将这些整数值划分类别。
[5485, 5408, 5437, 5417, 5623, 5418, 5435, 5467, 5600, 5477, 5435, 5458, 5439, 5492, 5426, 5463, 5432, 5442, 5432, 4893, 6969, 11500, 4947, 4856, 6982, 11405, 4918, 4844, 11390, 4905, 4885, 5783, 11581, 4939, 4879, 5768, 11670, 4934, 4863, 6950, 11523, 4916, 4839, 11443, 4890, 4859, 11416, 4902, 4855, 5818, 4908, 4951, 5920, 11442, 5016, 4911, 5781, 11354, 4961, 4971, 5788, 11357, 5026, 4872, 11378, 4923, 4898, 11418, 4946, 4867, 7064, 4915, 4830, 11410, 4884, 5007, 5770, 11597, 5077, 4858, 11588, 4910, 4972, 11262, 5023, 4875, 4941, 4870, 11525, 4912, 4868, 11519, 4919, 4916, 6942, 11417, 4966, 4876, 4929, 4875, 15107, 4934, 4847, 4900, 4943, 7013, 11375, 5000, 4956, 5013, 4905, 11391, 4960, 4942, 4992, 4910, 5772, 15140, 4967, 4868, 4912, 4860, 4924, 5030, 5769, 11372, 5076, 5008, 5773, 11482, 5050, 4985, 5044, 4899, 11408, 4950, 4974, 5037, 4918, 11427, 4962, 4899, 11467, 4958, 4843, 5789, 11513, 4905, 4872, 4924, 4965, 11659, 5012, 5003, 5782, 5057, 4948, 11537, 4996, 4880, 4929, 4911, 4966, 4852, 11484, 4901, 4983, 11384, 5038, 4894, 4957, 4866, 4879, 4839, 4960, 5009, 5021, 4882, 4848, 4940, 4847, 5023, 4958, 5588, 5481, 5798, 5428, 5844, 5569, 5606, 5789, 5485, 5518, 5749, 5630, 5285]
import numpy as np
import sklearn.cluster as sc
k = 6
x0 = [5485, 5408, 5437, 5417, 5623, 5418, 5435, 5467, 5600, 5477, 5435, 5458, 5439, 5492, 5426, 5463, 5432, 5442, 5432, 4893, 6969, 11500, 4947, 4856, 6982, 11405, 4918, 4844, 11390, 4905, 4885, 5783, 11581, 4939, 4879, 5768, 11670, 4934, 4863, 6950, 11523, 4916, 4839, 11443, 4890, 4859, 11416, 4902, 4855, 5818, 4908, 4951, 5920, 11442, 5016, 4911, 5781, 11354, 4961, 4971, 5788, 11357, 5026, 4872, 11378, 4923, 4898, 11418, 4946, 4867, 7064, 4915, 4830, 11410, 4884, 5007, 5770, 11597, 5077, 4858, 11588, 4910, 4972, 11262, 5023, 4875, 4941, 4870, 11525, 4912, 4868, 11519, 4919, 4916, 6942, 11417, 4966, 4876, 4929, 4875, 15107, 4934, 4847, 4900, 4943, 7013, 11375, 5000, 4956, 5013, 4905, 11391, 4960, 4942, 4992, 4910, 5772, 15140, 4967, 4868, 4912, 4860, 4924, 5030, 5769, 11372, 5076, 5008, 5773, 11482, 5050, 4985, 5044, 4899, 11408, 4950, 4974, 5037, 4918, 11427, 4962, 4899, 11467, 4958, 4843, 5789, 11513, 4905, 4872, 4924, 4965, 11659, 5012, 5003, 5782, 5057, 4948, 11537, 4996, 4880, 4929, 4911, 4966, 4852, 11484, 4901, 4983, 11384, 5038, 4894, 4957, 4866, 4879, 4839, 4960, 5009, 5021, 4882, 4848, 4940, 4847, 5023, 4958, 5588, 5481, 5798, 5428, 5844, 5569, 5606, 5789, 5485, 5518, 5749, 5630, 5285]
#x0.remove(17741)
#print(max(x0))
x = np.array([[i] for i in x0])
model = sc.KMeans(n_clusters=k)
model.fit(x)
pred_y = model.labels_
centers = model.cluster_centers_
print(pred_y)
for i in range(k):if len(x[pred_y==i]) == 4:print(np.argwhere(pred_y==i))
for i in range(k):print(len(x[pred_y==i]))
有时候你会发现,有些网站的URL并不是全部都是整齐的,往往都会出现一些异常URL,当对他做上面的处理时,某些样本特征会很大,这样导致这些被分到一个类,比如我有一次遇到了一个其他都在4000-8000的范围,唯独有几个却是10000多了,这样聚类的效果很不理想,因为这几个样本,削弱了其他样本间的差异,而这几个URL也大都不属于详情页或者列表页的URL。所以我们需要去掉他们。如何让程序自动去掉异常数据呢?
根据需求,我们只需要聚成两类。但如果我聚成三类或者更多的话是不是就可以区分这些异常数据?所以我们一开始先设定K为5或者6然后将类别占比小于5%的剔除,再次聚类为2,这样就达到了去掉噪声的效果。代码改天敲。
最后,我正在学习一些机器学习的算法,对于一些我需要记录的内容我都会分享到博客和微信公众号,欢迎关注。平时的话一般分享一些爬虫或者Python的内容。