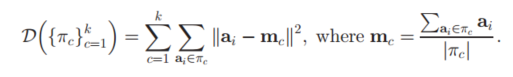前段时间学习了并行与分布式技术,为了写了篇关于KMeans算法的并行和分布式的编程写法,上网找了挺久,没想到网上并没有很多资料,那今天就来说一下我是怎么写的吧。
首先来讲一下K-Means的思想原理吧!
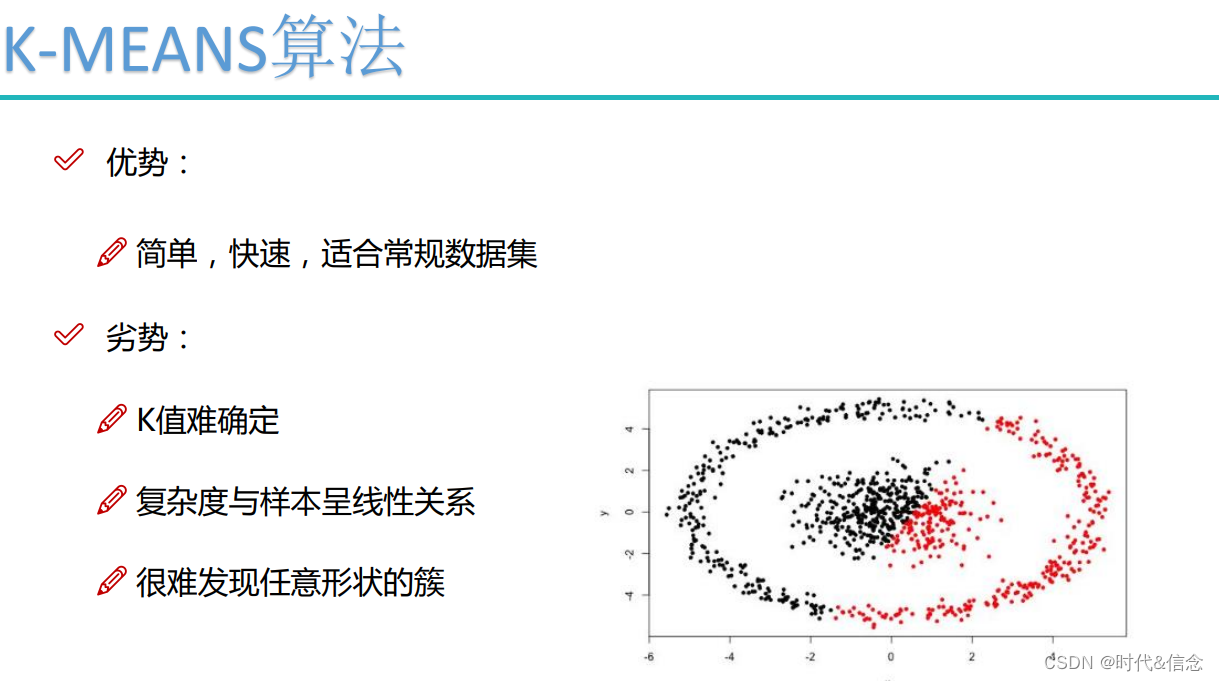
K-Means算法思想原理
K-means算法是根据给定 n n n个对象的数据集,构建 K K K个划分聚类方法,每个划分聚类称为簇。在这K个簇中,每个簇至少有一个数据对象,且每个数据对象有且只可属于一个簇。簇中的数据还有一个必须遵守的法则:同一个簇内的数据对象相似度高,不同簇的数据对象相似度低。这里的相似度将采用距离来衡量。
根据下图,可以看到K-means算法包括初始中心点的选择,对剩余数据对象遍历,进行相似度(距离)的计算,将相似度最高的数据点划分至该簇,重新计算中心点,再次相似度计算,直至代价函数达到最小值,即数据中心不再移动为止。

算法步骤总结
step1: 随机初始化 K K K个聚类中心点,循环Z次, ε = 1 0 − 5 \varepsilon=10^{-5} ε=10−5。
step2: 遍历其余样本点计算与各中心点的距离,选择相似度最高的聚为一类。
\step3: 计算代价函数 J J J,若 ∣ J ∣ ≤ ε |J|\leq\varepsilon ∣J∣≤ε或所有的观测值不再被分配或 k k k大于指定循环次数则退出循环, k = k + 1 k = k + 1 k=k+1。
step4: 重新计算新聚类中心点,返回step2。
接下来就是代码实现啦!
首先来看看只是用Numpy是怎么写的吧!
使用Numpy实现
为了方便理解,附上流程图如下:

Numpy的实现其实就是把所有数据丢进一个矩阵,然后算算算就好了😀
import numpy as np
import pandas as pd# 找出最优簇选择(初始)
def initial_value(n, k):minJ = np.min(data, axis=0)maxJ = np.max(data, axis=0)rangeJ = maxJ - minJcentroids = minJ + rangeJ * np.random.rand(k, 1)return centroids# 算每个的距离,,取最小距离的索引
def distance(data, centroids):d = np.sqrt(((data-centroids[:, np.newaxis])**2).sum(axis=2))return np.argmin(d, axis=0)# 更新簇中心
def update(res, K):return np.array([data[res==k].mean(axis=0) for k in range(K)])def main(k, data, iters):m, n = np.shape(data)centroids = initial_value(n, k) # 初始点for i in range(iters):res = distance(data, centroids) # 最小距离索引new_centroids = update(res, k) # 更新簇if (new_centroids == centroids).all(): # 若更新前后中心相同,跳出循环breakcentroids = new_centroidsreturn resif __name__ == '__main__':data = pd.read_csv('data.csv').valuesk, iters = 2, 100result = main(k, data, iters)print(result)
这种方式在数据量不大的时候其实还是很好用的,但如果数据量特大,和并行和分布式比起来就不是很占优势了。
多进程并行实现
老规矩,附上流程图:

在并行中,你会发现欸,怎么这流程不太一样了。。。
其实为了加快计算速度,我把数据分为8份丢到8个矩阵中同时计算,是不是听着就觉得快很多了呢!然后根据计算结果分别求平均值,最后找到新的中心点,循环到满意就ok啦。
至于我为什么是分8个矩阵,进程分配主要看自己的电脑,我的电脑是8核的。
import numpy as np
import pandas as pd
import multiprocessing# 找出最优簇选择(初始)
def initial_value(n, k):minJ = np.min(data, axis=0)maxJ = np.max(data, axis=0)rangeJ = maxJ - minJcentroids = minJ + rangeJ * np.random.rand(k, 1)return centroids# 算每个的距离,,取最小距离的索引
def distance(data, centroids):d = np.sqrt(((data-centroids[:, np.newaxis])**2).sum(axis=2))return np.argmin(d, axis=0)# 每个进程平均值
def avg(K, centroids, data):res = distance(data, centroids)return np.array([data[res==k].mean(axis=0) for k in range(K)]), res def job(z):return avg(z[0], z[1], z[2])def main(k, data, iters):m, n = np.shape(data)centroids = initial_value(n, k) # 初始点pool = multiprocessing.Pool(processes=8)data_lst = [(k, centroids, data)]for i in range(iters):update = pool.map(job, data_lst) # 求得每个进程平均part_centroids, res = update[0][0], update[0][1]new_centroids = part_centroids.mean(axis=0)if (centroids == new_centroids).all(): # 若更新前后中心相同,跳出循环breakcentroids = new_centroidsreturn resif __name__ == '__main__':data = pd.read_csv('data.csv').valuesk, iters = 2, 100result = main(k, data, iters)print(result)
Dask分布式实现
嗯,上图!

其实并行和分布式感觉上的流程是差不多的,浅显的理解一下,分布式就是利用电脑上的多个部件疯狂肝,分布式是通过局域网在多台电脑上疯狂肝。
import numpy as np
import dask.array as da
import dask.dataframe as dd
import pandas as pd
from dask.distributed import Client# 找出最优簇选择(初始)
def initial_value(n, k):minJ = da.min(data, axis=0)maxJ = da.max(data, axis=0)rangeJ = maxJ - minJcentroids = minJ + rangeJ * np.random.rand(k, 1)return centroids.compute()# 算每个的距离,,取最小距离的索引
def distance(data, centroids):d = da.sqrt(((data-centroids[:, np.newaxis])**2).sum(axis=2))return np.argmin(d, axis=0)# 每个进程平均值
def avg(K, centroids, data):res = distance(data, centroids)return da.array([data[res==k].mean(axis=0) for k in range(K)]) def job(z):return avg(z[0], z[1], z[2])def main(k, data, iters):m, n = da.shape(data)centroids = initial_value(n, k) # 初始点data_lst = [(k, centroids, data)]for i in range(iters):update = client.map(job, data_lst) # 求得每个进程平均new_centroids_sum = client.submit(sum, update)new_centroids = new_centroids_sum.result()/len(update)if (centroids == new_centroids.compute()).all(): # 若更新前后中心相同,跳出循环breakcentroids = new_centroidsres = distance(data, centroids)return res.compute()if __name__ == '__main__':client = Client('192.168.0.106:8786')data = pd.read_csv('data.csv').valuesk, iters = 2, 100result = main(k, data, iters)print(result)
结果对比
从下表中可以看到,速度从快到慢为:并行>Numpy>分布式>for循环。
| 方法 | 耗时 ( s ) (s) (s) |
|---|---|
| for循环 | 5296.72 |
| Numpy | 383.95 |
| 并行 | 36.26 |
| 分布式 | 450.92 |
是不是很震惊,并行和分布式的速度居然差这么多!在我的理解上,分布式的速度快慢更多的是与网络好坏有关,可能小编的网真的很差吧😔!
这次的分享就到这啦,有什么意见或者建议可以在评论区里说说哟!