时间轮
Kafka 中存在大量的延时操作,比如延时生产、延时拉取和延时删除等。Kafka 并没有使用 JDK 自带的 Timer 或 DelayQueue 来实现延时的功能,而是基于时间轮的概念自定义实现了一个用于延时功能的定时器(SystemTimer)。JDK 中 Timer 和 DelayQueue 的插入和删除操作的平均时间复杂度为 O(nlogn) 并不能满足 Kafka 的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为 O(1)。时间轮的应用并非 Kafka 独有,其应用场景还有很多,在 Netty、Akka、Quartz、ZooKeeper 等组件中都存在时间轮的踪影。

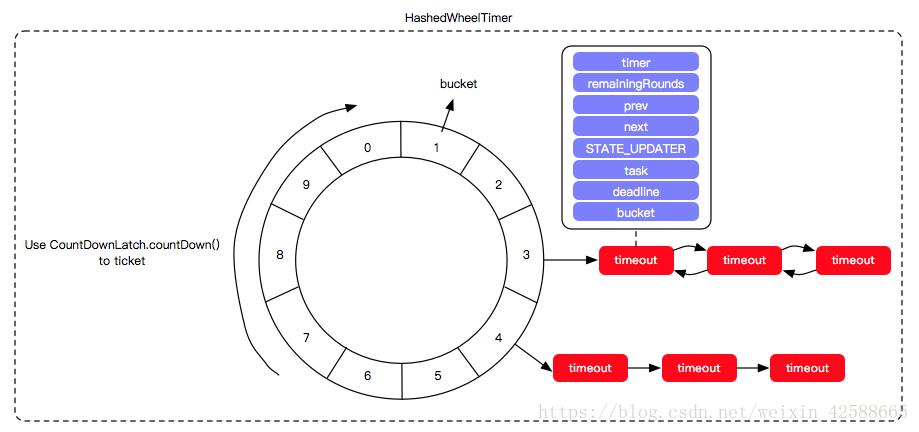
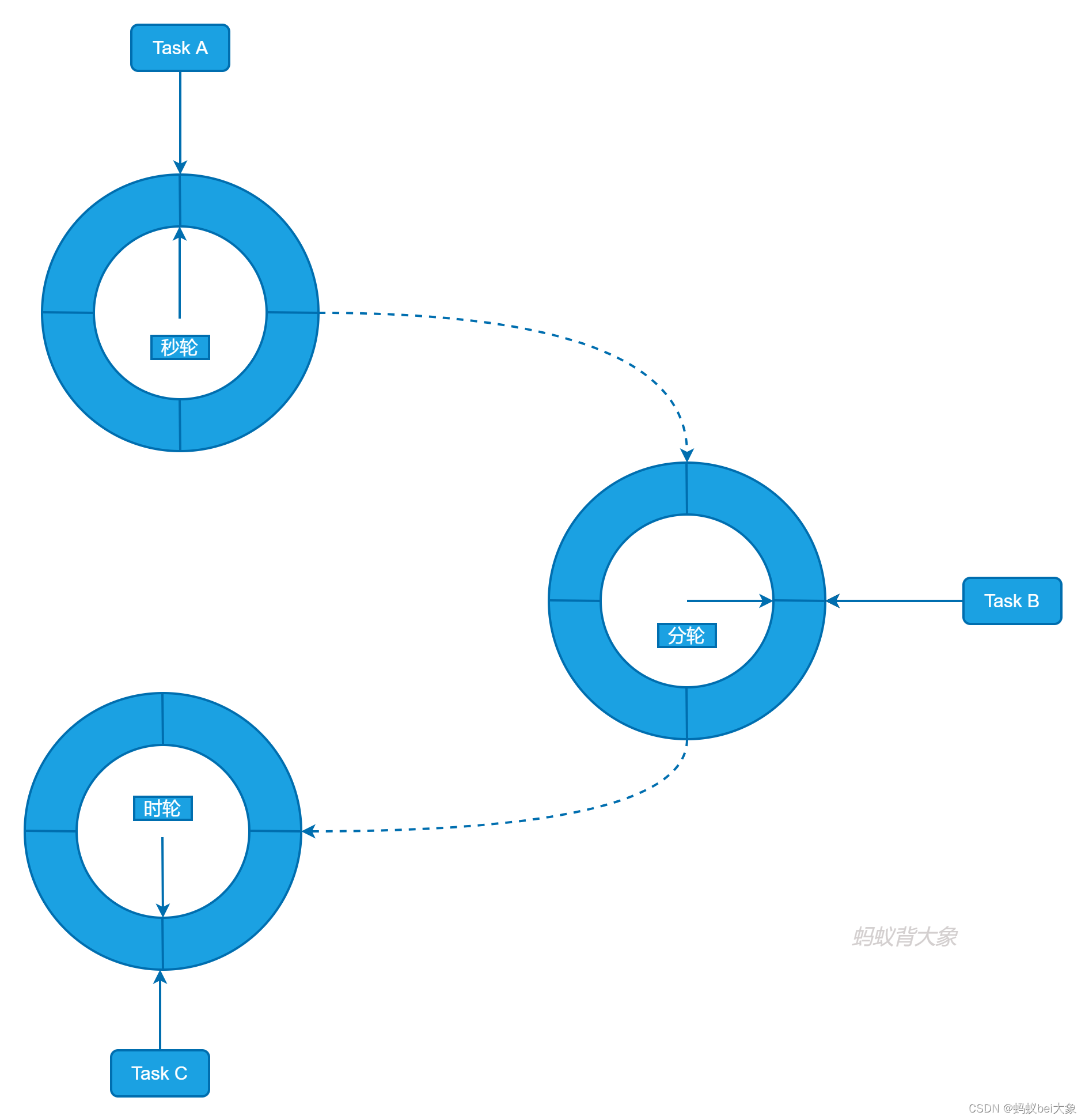
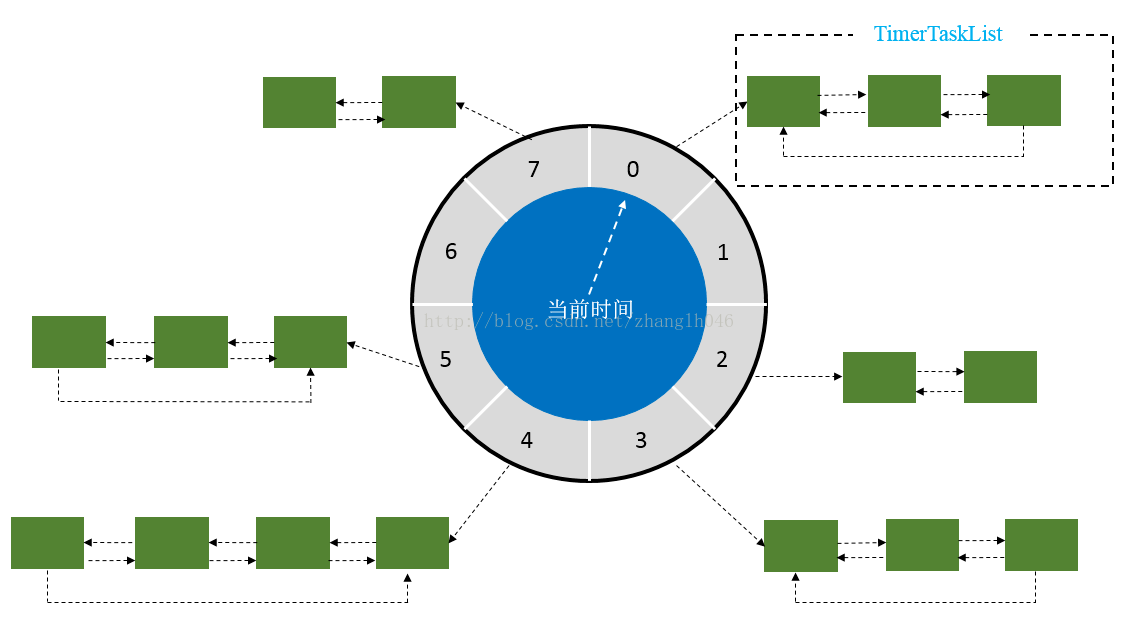
如上图所示,Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList 是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
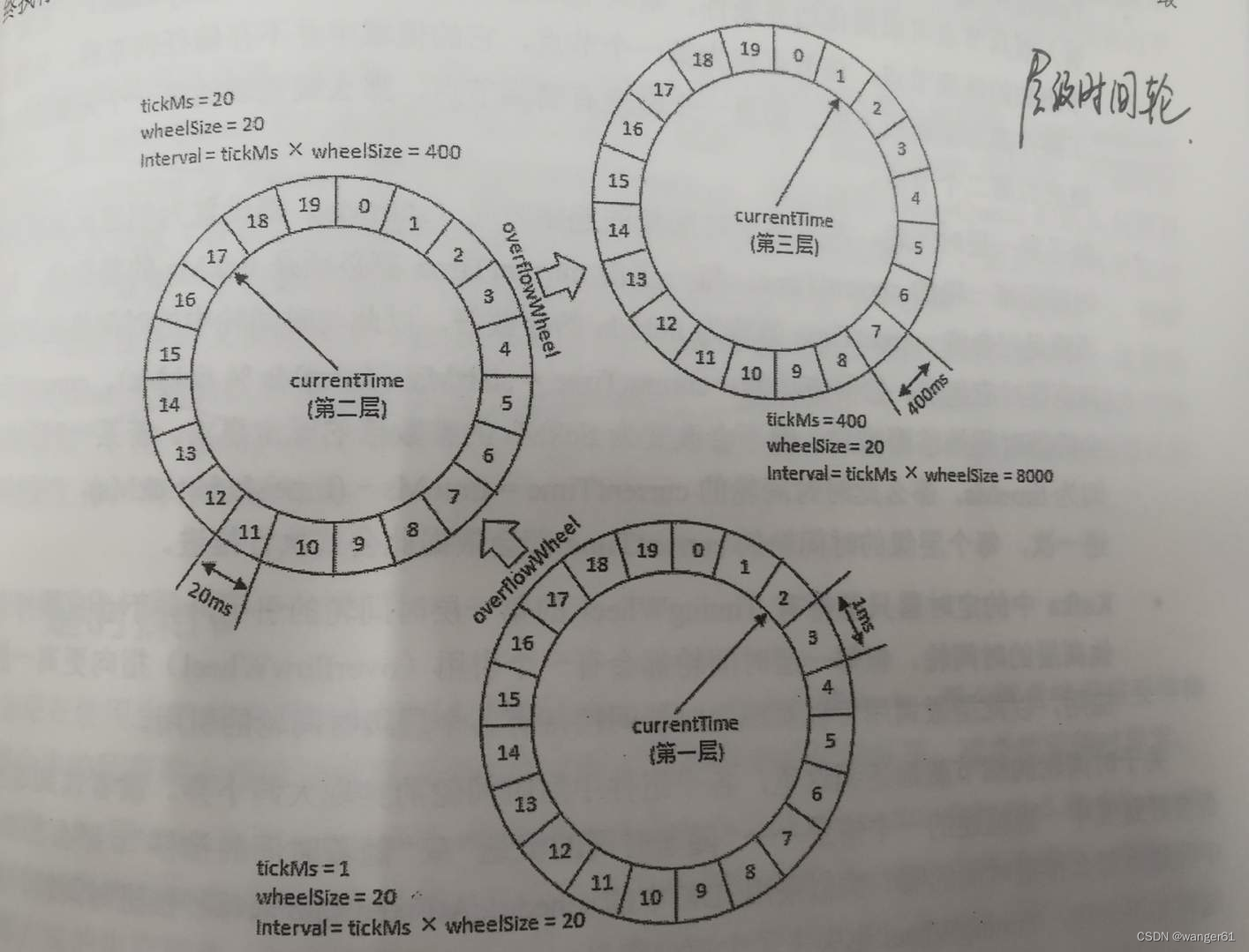
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。时间轮的时间格个数是固定的,可用 wheelSize 来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs×wheelSize 计算得出。
时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime 是 tickMs 的整数倍。currentTime 可以将整个时间轮划分为到期部分和未到期部分,currentTime 当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的 TimerTaskList 中的所有任务。
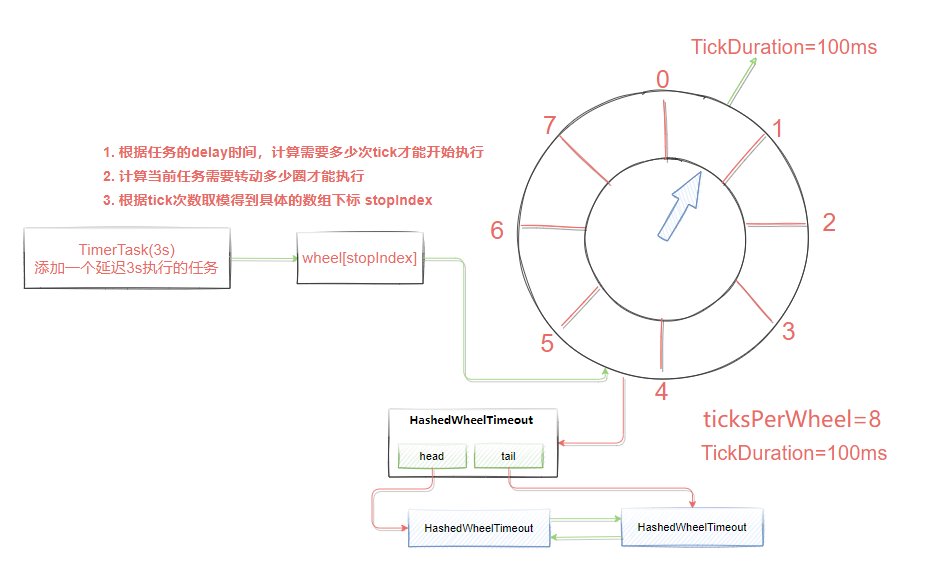
若时间轮的 tickMs 为 1ms 且 wheelSize 等于20,那么可以计算得出总体时间跨度 interval 为20ms。
初始情况下表盘指针 currentTime 指向时间格0,此时有一个定时为2ms的任务插进来会存放到时间格为2的 TimerTaskList 中。随着时间的不断推移,指针 currentTime 不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2对应的 TimeTaskList 中的任务进行相应的到期操作。此时若又有一个定时为8ms的任务插进来,则会存放到时间格10中,currentTime 再过8ms后会指向时间格10。
如果同时有一个定时为19ms的任务插进来怎么办?新来的 TimerTaskEntry 会复用原来的 TimerTaskList,所以它会插入原本已经到期的时间格1。总之,整个时间轮的总体跨度是不变的,随着指针 currentTime 的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在 currentTime 和 currentTime+interval 之间。
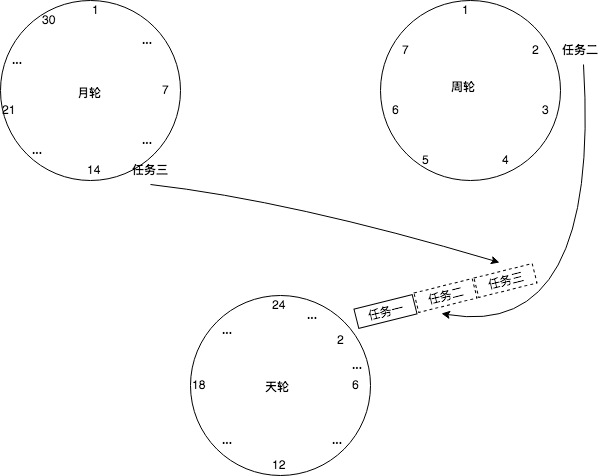
如果此时有一个定时为 350ms 的任务该如何处理?直接扩充 wheelSize 的大小?Kafka 中不乏几万甚至几十万毫秒的定时任务,这个 wheelSize 的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如100万毫秒,那么这个 wheelSize 为100万毫秒的时间轮不仅占用很大的内存空间,而且也会拉低效率。Kafka 为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。

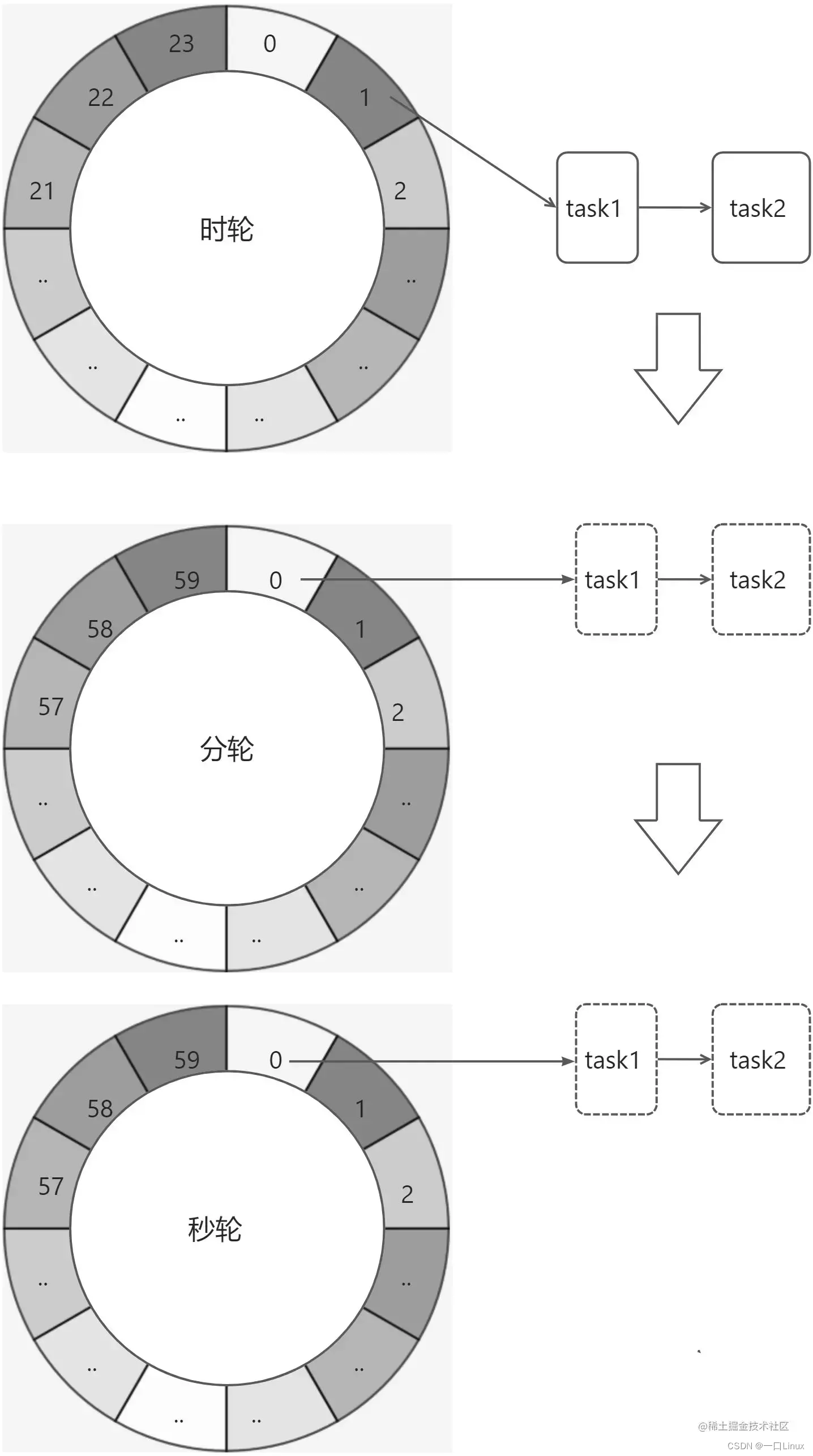
如上图所示,复用之前的案例,第一层的时间轮 tickMs=1ms、wheelSize=20、interval=20ms。第二层的时间轮的 tickMs 为第一层时间轮的 interval,即20ms。每一层时间轮的 wheelSize 是固定的,都是20,那么第二层的时间轮的总体时间跨度 interval 为400ms。以此类推,这个400ms也是第三层的 tickMs 的大小,第三层的时间轮的总体时间跨度为8000ms。
对于之前所说的 350ms 的定时任务,显然第一层时间轮不能满足条件,所以就升级到第二层时间轮中,最终被插入第二层时间轮中时间格17所对应的 TimerTaskList。如果此时又有一个定时为 450ms 的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入第三层时间轮中时间格1的 TimerTaskList。注意到在到期时间为 [400ms,800ms) 区间内的多个任务(比如 446ms、455ms 和 473ms 的定时任务)都会被放入第三层时间轮的时间格1,时间格1对应的 TimerTaskList 的超时时间为 400ms。
随着时间的流逝,当此 TimerTaskList 到期之时,原本定时为 450ms 的任务还剩下 50ms 的时间,还不能执行这个任务的到期操作。这里就有一个时间轮降级的操作,会将这个剩余时间为 50ms 的定时任务重新提交到层级时间轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为 [40ms,60ms) 的时间格中。再经历 40ms 之后,此时这个任务又被“察觉”,不过还剩余 10ms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到第一层时间轮到期时间为 [10ms,11ms) 的时间格中,之后再经历 10ms 后,此任务真正到期,最终执行相应的到期操作。
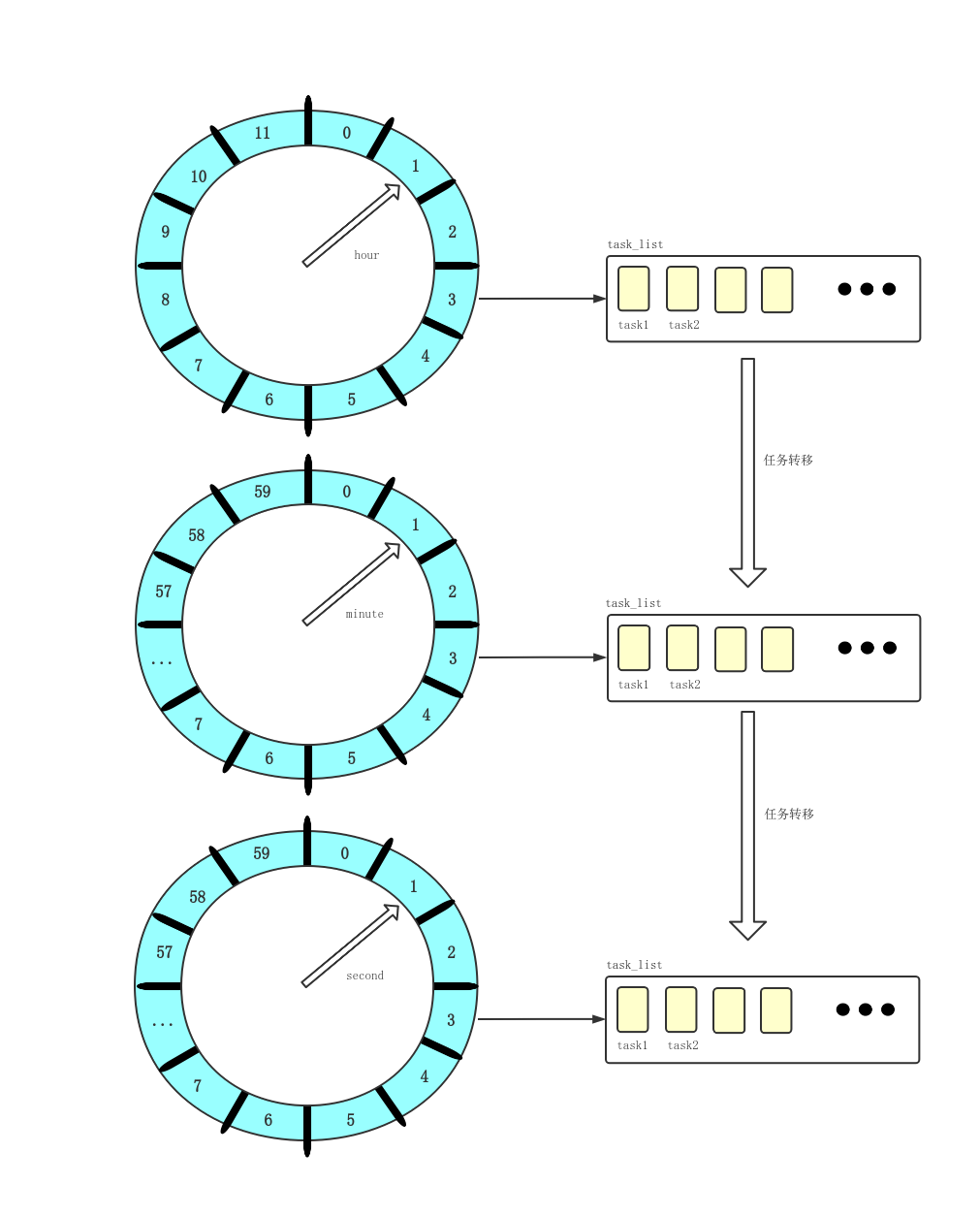
设计源于生活。我们常见的钟表就是一种具有三层结构的时间轮,第一层时间轮 tickMs=1s、wheelSize=60、interval=1min,此为秒钟;第二层 tickMs=1min、wheelSize=60、interval=1hour,此为分钟;第三层 tickMs=1hour、wheelSize=12、interval=12hours,此为时钟。
在 Kafka 中,第一层时间轮的参数同上面的案例一样:tickMs=1ms、wheelSize=20、interval=20ms,各个层级的 wheelSize 也固定为20,所以各个层级的 tickMs 和 interval 也可以相应地推算出来。Kafka 在具体实现时间轮 TimingWheel 时还有一些小细节:
- TimingWheel 在创建的时候以当前系统时间为第一层时间轮的起始时间(startMs),这里的当前系统时间并没有简单地调用 System.currentTimeMillis(),而是调用了 Time.SYSTEM.hiResClockMs,这是因为 currentTimeMillis() 方法的时间精度依赖于操作系统的具体实现,有些操作系统下并不能达到毫秒级的精度,而 Time.SYSTEM.hiResClockMs 实质上采用了 System.nanoTime()/1_000_000 来将精度调整到毫秒级。
- TimingWheel 中的每个双向环形链表 TimerTaskList 都会有一个哨兵节点(sentinel),引入哨兵节点可以简化边界条件。哨兵节点也称为哑元节点(dummy node),它是一个附加的链表节点,该节点作为第一个节点,它的值域中并不存储任何东西,只是为了操作的方便而引入的。如果一个链表有哨兵节点,那么线性表的第一个元素应该是链表的第二个节点。
- 除了第一层时间轮,其余高层时间轮的起始时间(startMs)都设置为创建此层时间轮时前面第一轮的 currentTime。每一层的 currentTime 都必须是 tickMs 的整数倍,如果不满足则会将 currentTime 修剪为 tickMs 的整数倍,以此与时间轮中的时间格的到期时间范围对应起来。修剪方法为:currentTime = startMs - (startMs % tickMs)。currentTime 会随着时间推移而推进,但不会改变为 tickMs 的整数倍的既定事实。若某一时刻的时间为 timeMs,那么此时时间轮的 currentTime = timeMs - (timeMs % tickMs),时间每推进一次,每个层级的时间轮的 currentTime 都会依据此公式执行推进。
- Kafka 中的定时器只需持有 TimingWheel 的第一层时间轮的引用,并不会直接持有其他高层的时间轮,但每一层时间轮都会有一个引用(overflowWheel)指向更高一层的应用,以此层级调用可以实现定时器间接持有各个层级时间轮的引用。
关于时间轮的细节就描述到这里,各个组件中对时间轮的实现大同小异。读者读到这里是否会好奇文中一直描述的一个情景—“随着时间的流逝”或“随着时间的推移”,那么在 Kafka 中到底是怎么推进时间的呢?类似采用 JDK 中的 scheduleAtFixedRate 来每秒推进时间轮?显然这样并不合理,TimingWheel 也失去了大部分意义。
Kafka 中的定时器借了 JDK 中的 DelayQueue 来协助推进时间轮。具体做法是对于每个使用到的 TimerTaskList 都加入 DelayQueue,“每个用到的 TimerTaskList”特指非哨兵节点的定时任务项 TimerTaskEntry 对应的 TimerTaskList。DelayQueue 会根据 TimerTaskList 对应的超时时间 expiration 来排序,最短 expiration 的 TimerTaskList 会被排在 DelayQueue 的队头。
Kafka 中会有一个线程来获取 DelayQueue 中到期的任务列表,有意思的是这个线程所对应的名称叫作“ExpiredOperationReaper”,可以直译为“过期操作收割机”,和第4节的“SkimpyOffsetMap”的取名有异曲同工之妙。当“收割机”线程获取 DelayQueue 中超时的任务列表 TimerTaskList 之后,既可以根据 TimerTaskList 的 expiration 来推进时间轮的时间,也可以就获取的 TimerTaskList 执行相应的操作,对里面的 TimerTaskEntry 该执行过期操作的就执行过期操作,该降级时间轮的就降级时间轮。
读到这里或许会感到困惑,开头明确指明的 DelayQueue 不适合 Kafka 这种高性能要求的定时任务,为何这里还要引入 DelayQueue 呢?注意对定时任务项 TimerTaskEntry 的插入和删除操作而言,TimingWheel时间复杂度为 O(1),性能高出 DelayQueue 很多,如果直接将 TimerTaskEntry 插入 DelayQueue,那么性能显然难以支撑。就算我们根据一定的规则将若干 TimerTaskEntry 划分到 TimerTaskList 这个组中,然后将 TimerTaskList 插入 DelayQueue,如果在 TimerTaskList 中又要多添加一个 TimerTaskEntry 时该如何处理呢?对 DelayQueue 而言,这类操作显然变得力不从心。
分析到这里可以发现,Kafka 中的 TimingWheel 专门用来执行插入和删除 TimerTaskEntry 的操作,而 DelayQueue 专门负责时间推进的任务。试想一下,DelayQueue 中的第一个超时任务列表的 expiration 为 200ms,第二个超时任务为 840ms,这里获取 DelayQueue 的队头只需要 O(1) 的时间复杂度(获取之后 DelayQueue 内部才会再次切换出新的队头)。如果采用每秒定时推进,那么获取第一个超时的任务列表时执行的200次推进中有199次属于“空推进”,而获取第二个超时任务时又需要执行639次“空推进”,这样会无故空耗机器的性能资源,这里采用 DelayQueue 来辅助以少量空间换时间,从而做到了“精准推进”。Kafka 中的定时器真可谓“知人善用”,用 TimingWheel 做最擅长的任务添加和删除操作,而用 DelayQueue 做最擅长的时间推进工作,两者相辅相成。