文章目录
- 定时器
- 最小堆实现定时器
- 时间轮
- 单层级时间轮
- 多层级时间轮
定时器
有些时候我们需要延迟执行一些功能,比如每10s进行一次数据采集。或者告知用户技能冷却有多少时间,如果我们将执行这些功能的任务交给主线程,就会造成主线程的阻塞。因此我们可以选择一个创建一个子线程,让其检测定时器中的任务,当有任务的时间到了的时候,就去执行这个任务。
最小堆实现定时器
定时器可以由很多种数据结构实现,比如最小堆、红黑树、跳表、甚至数组都可以,其本质都是拿到最小时间的任务,然后取出该任务并执行。
综合实现难度和效率来看,最小堆是最容易实现定时器的数据结构。
最小堆主要有以下接口:
#pragma once#include <vector>
#include <map>
using namespace std;typedef void (*TimerHandler)(struct TimerNode *node);
//获取系统时间,单位是毫秒
static uint32_t current_time()
{uint32_t t;struct timespec ti;clock_gettime(CLOCK_MONOTONIC, &ti);t = (uint32_t)ti.tv_sec * 1000;t += ti.tv_nsec / 1000000;return t;
}struct TimerNode
{//该任务在最小堆中的下标位置int idx = 0;//该任务是第几号任务int id = 0;//几毫秒后执行该任务unsigned int expire = 0;//回调函数TimerHandler cb = NULL;
};class MinHeapTimer
{
public:MinHeapTimer(){_heap.clear();_map.clear();}int Count();//加入任务,expire为该任务的失效时间,expire过后就要执行回调函数cbint AddTimer(uint32_t expire, TimerHandler cb);//删除一个任务bool DelTimer(int id);//获取一个任务void ExpireTimer();private://用于比较两个任务的过期时间bool _compare(int lhs, int rhs);//向下调整算法,每次删除一个节点就要向下调整void _shiftDown(int parent);//向上调整算法,每添加一个数都要调用向上调整算法,保证根节点为最小节点void _shiftUp(int child);//删除的子函数void _delNode(TimerNode *node);void resign(int pos);private://数组中存储任务节点vector<TimerNode *> _heap;//存储值和响应节点的映射关系map<int, TimerNode *> _map;//任务的个数,注意不是_heap的sizeint _count = 0;
};
具体的实现以及测试为:
#pragma once#include <vector>
#include <map>
using namespace std;typedef void (*TimerHandler)(struct TimerNode *node);
//获取系统时间,单位是毫秒
static uint32_t current_time()
{uint32_t t;struct timespec ti;clock_gettime(CLOCK_MONOTONIC, &ti);t = (uint32_t)ti.tv_sec * 1000;t += ti.tv_nsec / 1000000;return t;
}struct TimerNode
{//该任务在最小堆中的下标位置int idx = 0;//该任务是第几号任务int id = 0;unsigned int expire = 0;//回调函数TimerHandler cb = NULL;
};class MinHeapTimer
{
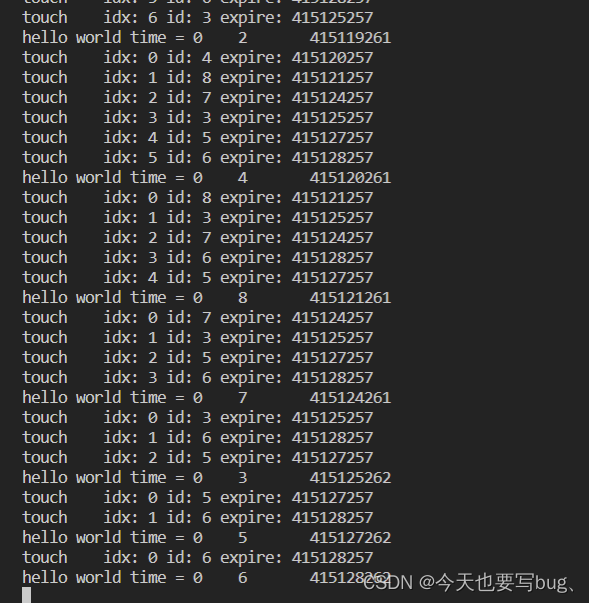
public:MinHeapTimer(){_heap.clear();_map.clear();}int Count(){return ++_count;}//加入任务,expire为该任务的失效时间,expire过后就要执行回调函数cbint AddTimer(uint32_t expire, TimerHandler cb){int64_t timeout = current_time() + expire;TimerNode *node = new TimerNode;int id = Count();node->id = id;node->expire = timeout;node->cb = cb;node->idx = (int)_heap.size();_heap.push_back(node);_shiftUp((int)_heap.size() - 1);_map.insert(make_pair(id, node));return id;}//删除一个任务bool DelTimer(int id){auto iter = _map.find(id);if (iter == _map.end())return false;_delNode(iter->second);return true;}//获取一个任务void ExpireTimer(){if (_heap.empty()){return;}//获取当前时间uint32_t now = current_time();while (!_heap.empty()){//获取最近的一个任务TimerNode *node = _heap.front();//当最近一个任务的时间大于当前时间,说明没有任务要执行if (now < node->expire){break;}//遍历一下堆,这一步可以不加for (int i = 0; i < _heap.size(); i++){std::cout << "touch idx: " << _heap[i]->idx<< " id: " << _heap[i]->id << " expire: "<< _heap[i]->expire << std::endl;}//执行最近任务的回调函数if (node->cb){node->cb(node);}//执行完就删掉这个任务_delNode(node);}}private://用于比较两个任务的过期时间bool _compare(int lhs, int rhs){return _heap[lhs]->expire < _heap[rhs]->expire;}//向下调整算法,每次删除一个节点就要向下调整void _shiftDown(int parent){int child = parent * 2 + 1;while (child < _heap.size() - 1){if (child + 1 < _heap.size() - 1 && !_compare(child, child + 1)){child++;}if (!_compare(parent, child)){std::swap(_heap[parent], _heap[child]);_heap[parent]->idx = parent;_heap[child]->idx = child;parent = child;child = parent * 2 + 1;}else{break;}}}//向上调整算法,每添加一个数都要调用向上调整算法,保证根节点为最小节点void _shiftUp(int child){int parent = (child - 1) / 2;while (child > 0){if (!_compare(parent, child)){std::swap(_heap[parent], _heap[child]);_heap[parent]->idx = parent;_heap[child]->idx = child;child = parent;parent = (child - 1) / 2;}else{break;}}}//删除的子函数void _delNode(TimerNode *node){int last = (int)_heap.size() - 1;int idx = node->idx;if (idx != last){std::swap(_heap[idx], _heap[last]);_heap[idx]->idx = idx;resign(idx);}_heap.pop_back();_map.erase(node->id);delete node;}void resign(int pos){//向上调整和向下调整只会发生一个_shiftDown(pos);_shiftUp(pos);}private://数组中存储任务节点vector<TimerNode *> _heap;//存储值和响应节点的映射关系map<int, TimerNode *> _map;//任务的个数,注意不是_heap的sizeint _count = 0;
};
#include <time.h>
#include <unistd.h>
#include <iostream>#include "minheap.h"void print_hello(TimerNode *te)
{std::cout << "hello world time = " << te->idx << "\t" << te->id << "\t" << current_time() << std::endl;
}int main()
{MinHeapTimer mht;//一号任务,立刻执行mht.AddTimer(0, print_hello);//二号任务,一秒后执行mht.AddTimer(1000, print_hello);mht.AddTimer(7000, print_hello);mht.AddTimer(2000, print_hello);mht.AddTimer(9000, print_hello);mht.AddTimer(10000, print_hello);mht.AddTimer(6000, print_hello);mht.AddTimer(3000, print_hello);while (1){mht.ExpireTimer();// usleep(10000);sleep(1);}return 0;
}
时间轮
上面的定时器在任务数量很多时,效率会很低,因为我们需要用最小堆来维护这些任务,并且每删除一个任务,都要进行调整。其主要原因是我们不知道其他任务什么时候执行,所以我们只能进行调整,将最近的任务放到堆顶。
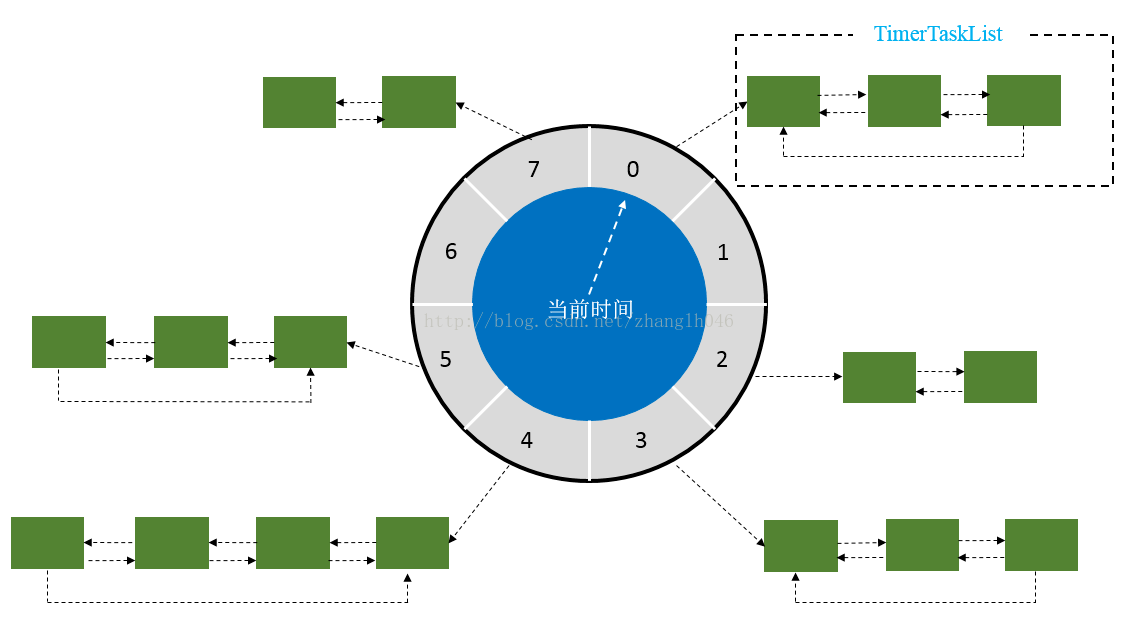
如果我们能够向哈希桶那样,将要执行的任务形成链表,挂到要执行的位置,当时间走到那个位置的时候,就执行这些任务,效率岂不是更高?
单层级时间轮
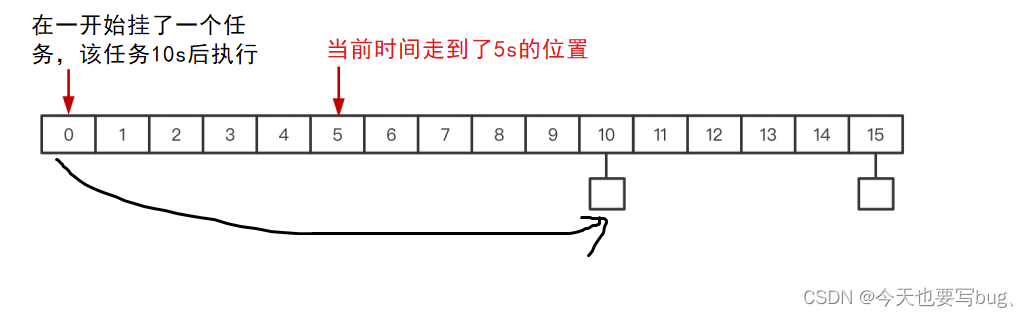
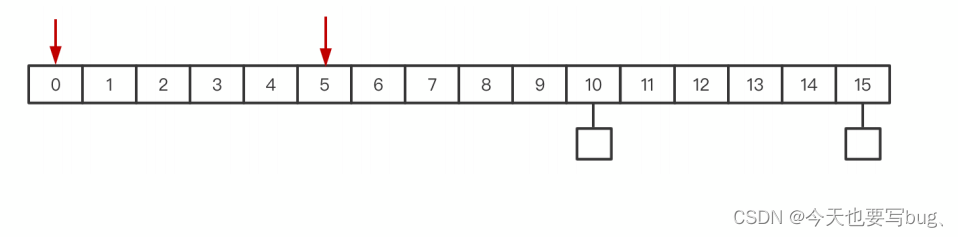
客户端每 5 秒钟发送⼼跳包;服务端若 10 秒内没收到⼼跳数据,则清除连接。
考虑到正常情况下 5 秒钟发送⼀次⼼跳包,10 秒才检测⼀次,如下图到索引为 10 的时候并不能踢掉连接;所以需要每收到⼀次⼼跳包则 used++ ,每检测⼀次 used-- ;当检测到used == 0 则踢掉连接;
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdint.h>#include <sys/time.h>
#include <time.h>#define MAX_CONN ((1 << 16) - 1)//连接的节点,用来记录心跳包发送的次数
typedef struct conn_node
{struct conn_node *next;//引用计数的次数,当used==0,相当于自动销毁uint8_t used;int id;
} conn_node_t;
//用数组记录所有的连接
static conn_node_t nodes[MAX_CONN] = {0};
static uint32_t iter = 0;//获取一个空的连接节点
conn_node_t *get_node()
{iter++;while (nodes[iter & MAX_CONN].used > 0){iter++;}return &nodes[iter];
}//哈希桶的个数
#define TW_SIZE 16
//检测心跳包的延迟时间,由于哈希桶的个数有限,所以心跳包发送时间不能够超过6
#define EXPIRE 10
//取余操作
#define TW_MASK (TW_SIZE - 1)
static uint32_t tick = 0;
//哈希桶
typedef struct link_list
{conn_node_t head;//一个tail,能够进行快速插入conn_node_t *tail;
} link_list_t;
//添加连接
void add_conn(link_list_t *tw, conn_node_t *node, int delay)
{//获取对应的哈希桶link_list_t *list = &tw[(tick + EXPIRE + delay) & TW_MASK];list->tail->next = node;list->tail = node;node->next = NULL;node->used++;
}
//清楚这个哈希桶
void link_clear(link_list_t *list)
{list->head.next = NULL;list->tail = &(list->head);
}
//检测哈希桶
void check_conn(link_list_t *tw)
{int32_t itick = tick;tick++;//取到对应哈希桶的链表link_list_t *list = &tw[itick & TW_MASK];//检测哈希桶对应的链表conn_node_t *current = list->head.next;while (current){conn_node_t *temp = current;current = current->next;temp->used--;if (temp->used == 0){printf("连接:%d 断开\n", temp->id);temp->next = NULL;continue;}printf("这个链接:%d 心跳包还剩:%d个需要检测\n", temp->id, temp->used);}link_clear(list);
}
//获取时间,单位是s
static time_t current_time()
{time_t t;struct timespec ti;clock_gettime(CLOCK_MONOTONIC, &ti);t = (time_t)ti.tv_sec;return t;
}int main()
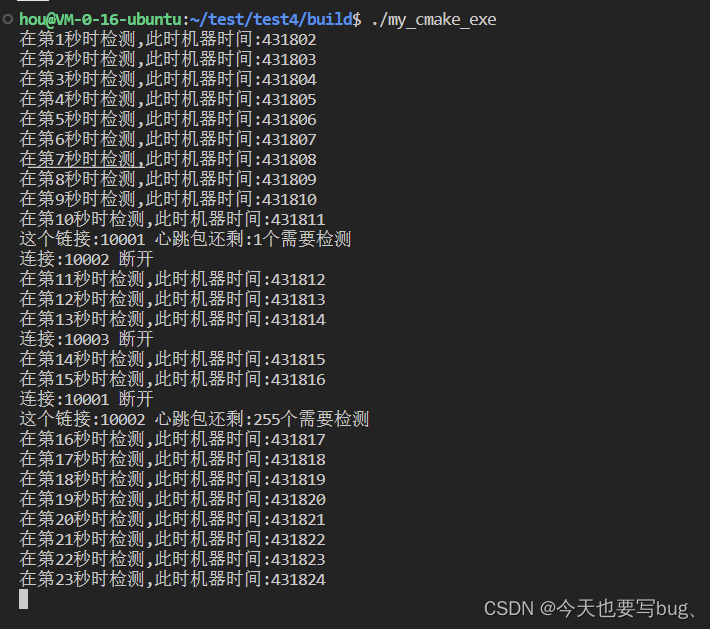
{memset(nodes, 0, MAX_CONN * sizeof(conn_node_t));// init link listlink_list_t tw[TW_SIZE];memset(tw, 0, TW_SIZE * sizeof(link_list_t));for (int i = 0; i < TW_SIZE; i++){link_clear(&tw[i]);}// 第一个连接对应的心跳包,在0和5时进行发送//所以会在10s和15s时进行检测,15s时把该连接断开{conn_node_t *node = get_node();node->id = 10001;add_conn(tw, node, 0);add_conn(tw, node, 5);}//第二个连接发送的心跳包,在第10s时进行检测{conn_node_t *node = get_node();node->id = 10002;add_conn(tw, node, 0);}//第二个连接发送的心跳包,在第13s时检测{conn_node_t *node = get_node();node->id = 10003;add_conn(tw, node, 3);}time_t start = current_time();while (1){time_t now = current_time();if (now - start > 0){for (int i = 0; i < now - start; i++)check_conn(tw);start = now;printf("在第%d秒时检测,此时机器时间:%d\n", tick, now);}}return 0;
}
上面的时间轮受哈希桶大小和延迟10s收到心跳包的影响,只能在[0,6]秒内发送数据心跳包,如果想要延迟长时间,则需要扩大哈希桶的大小。
如果我们不发送心跳包,而是改成在若干秒后执行一个任务,比如50s后执行任务,但哈希桶大小只有16,我们可以在任务节点中增加一个参数round,用来记录需要走多少遍哈希桶,比如50s,对应到大小为16的哈希桶则round=3,idx=2。
不过这样做,在check_conn取任务时就不能够把整个链表都取出来,而是需要取出round==0的任务。
typedef struct node
{struct conn_node *next;//需要走多少轮哈希桶,当round==0时,则说明需要执行这个任务int round;int id;
} node_t;
这样做能解决时间轮刻度范围过大造成的空间浪费,但是却带来了另一个问题:时间轮每次都需要遍历任务列表,耗时增加,当时间轮刻度粒度很小(秒级甚至毫秒级),任务列表又特别长时,这种遍历的办法是不可接受的。
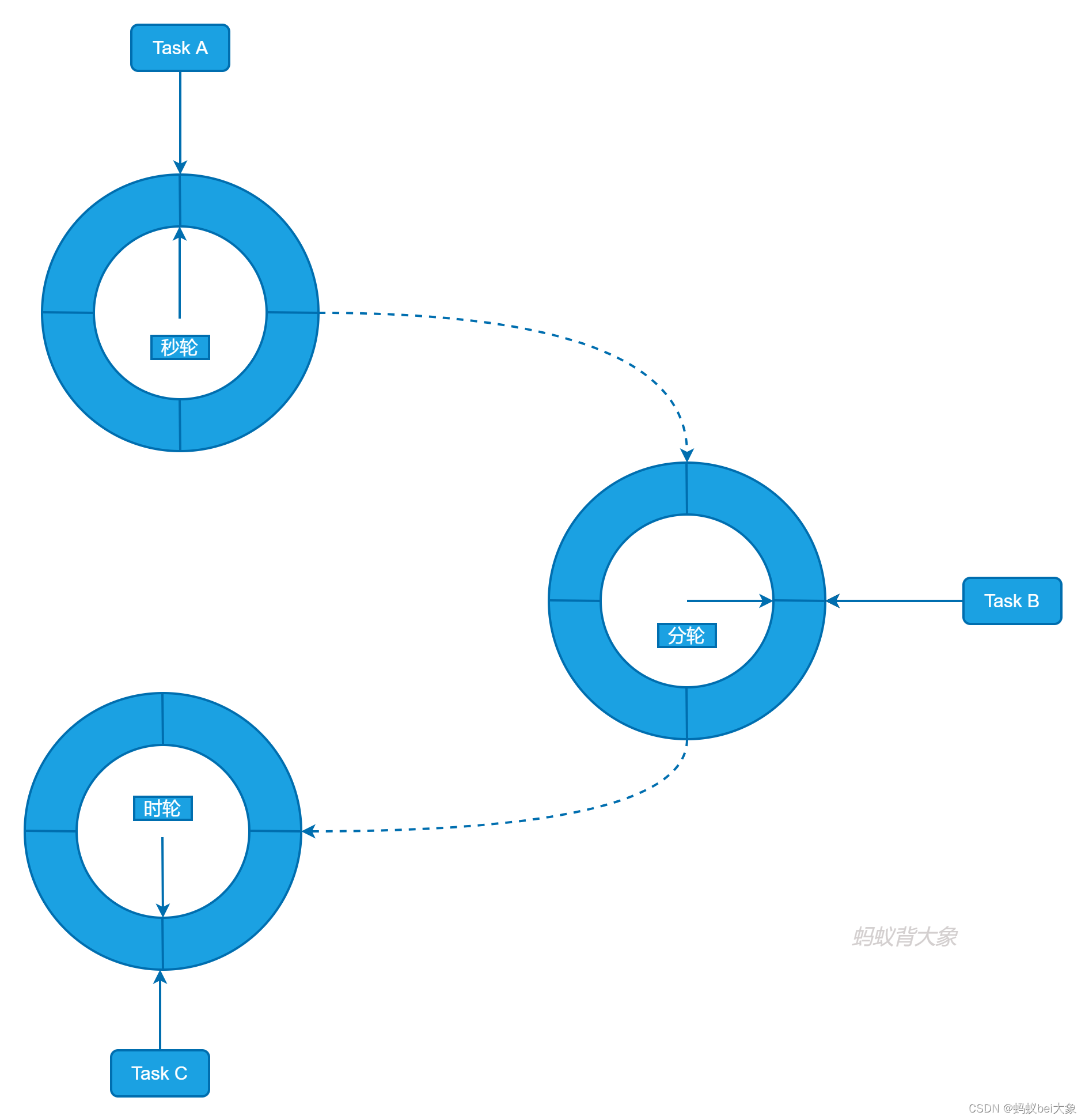
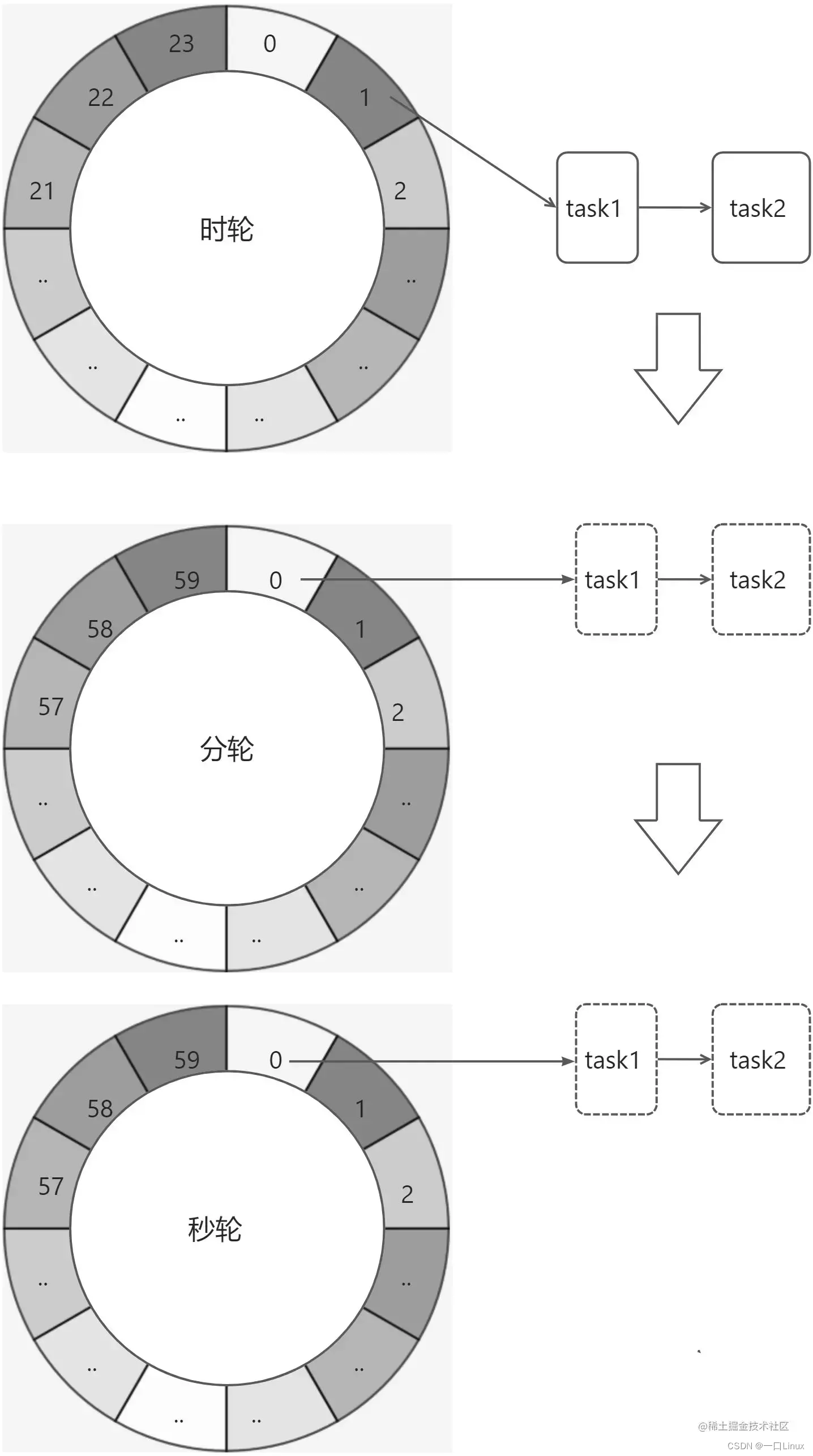
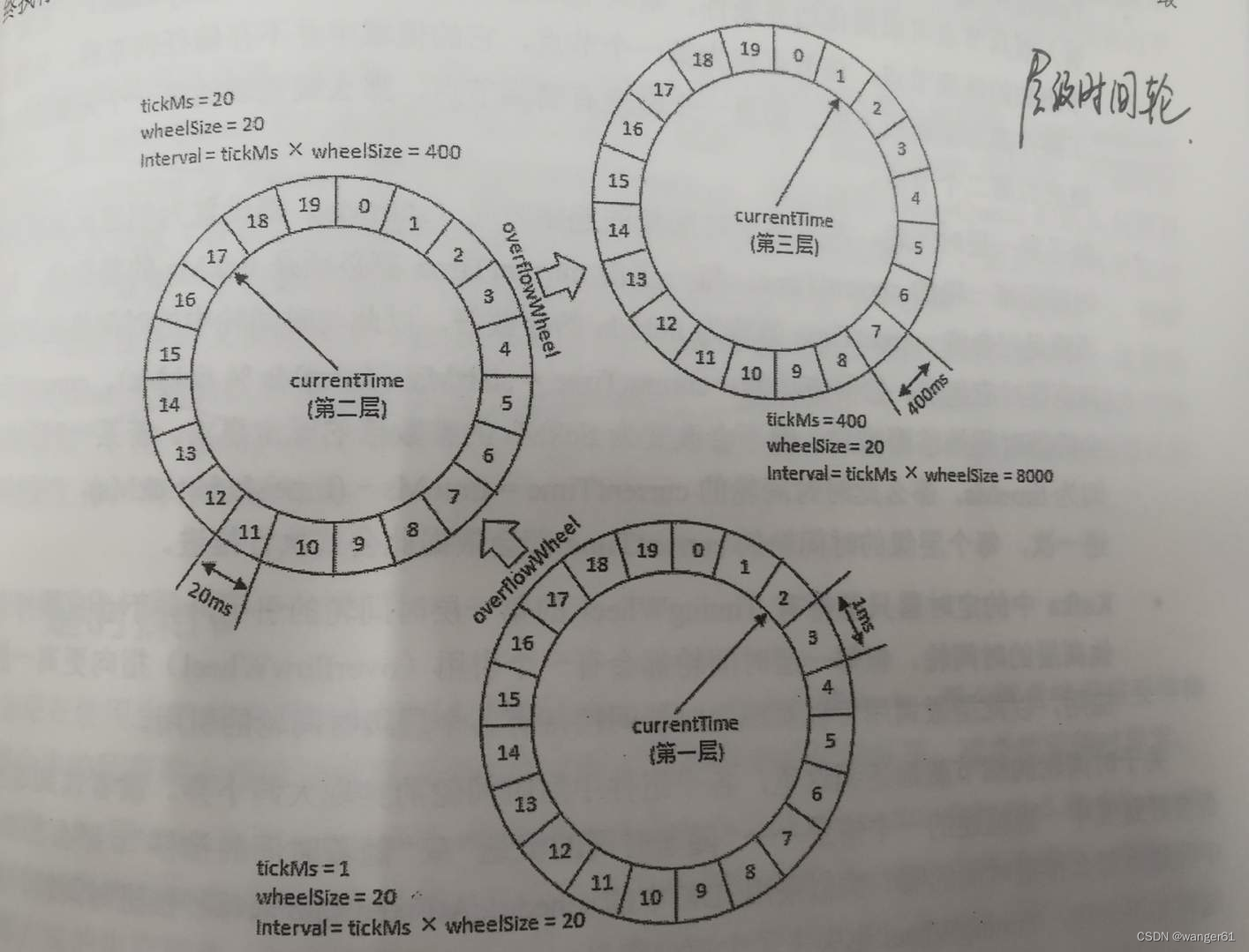
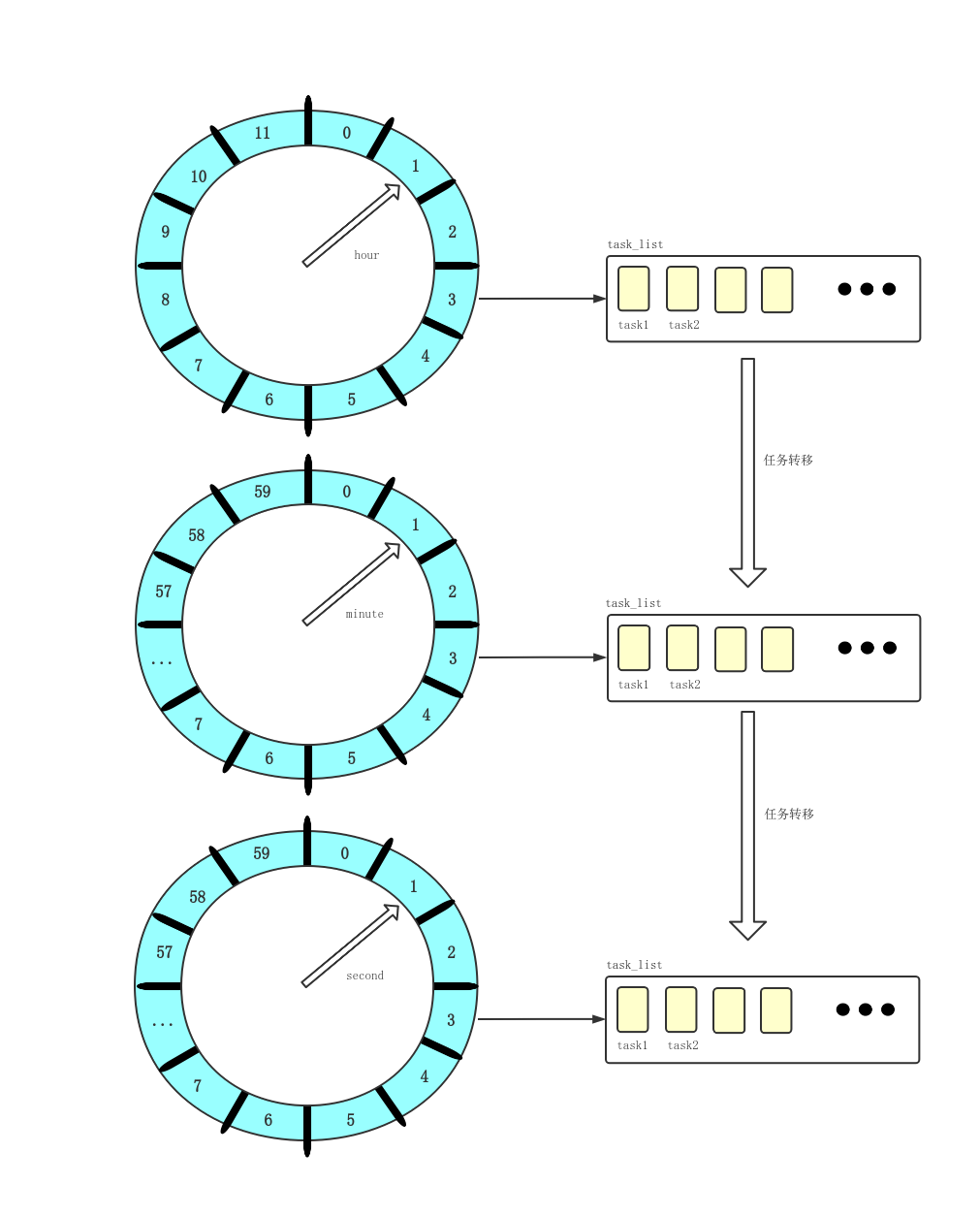
多层级时间轮
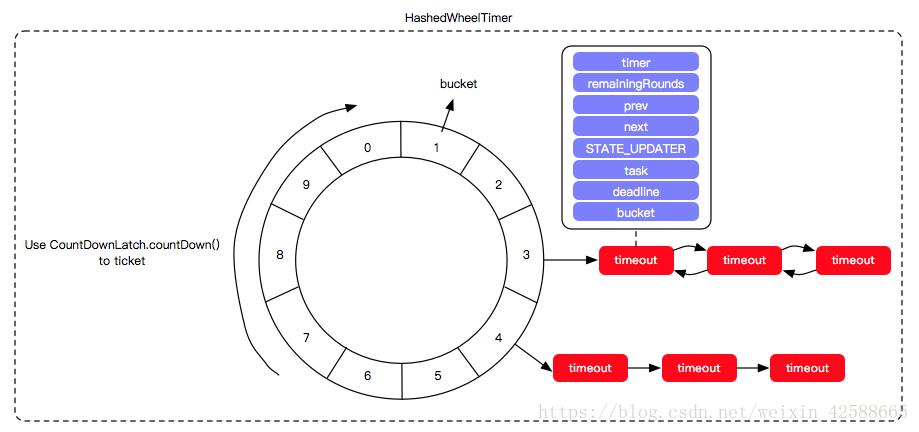
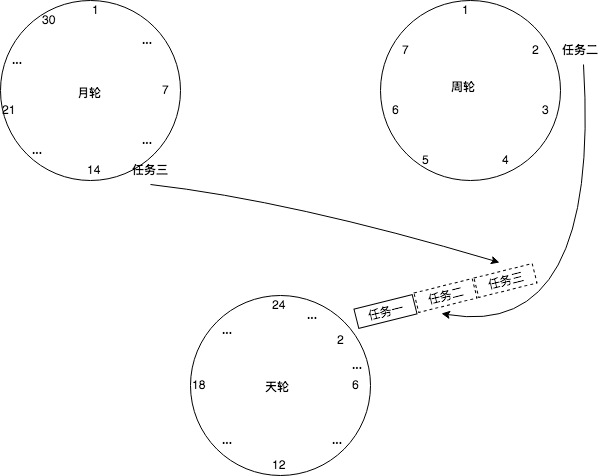
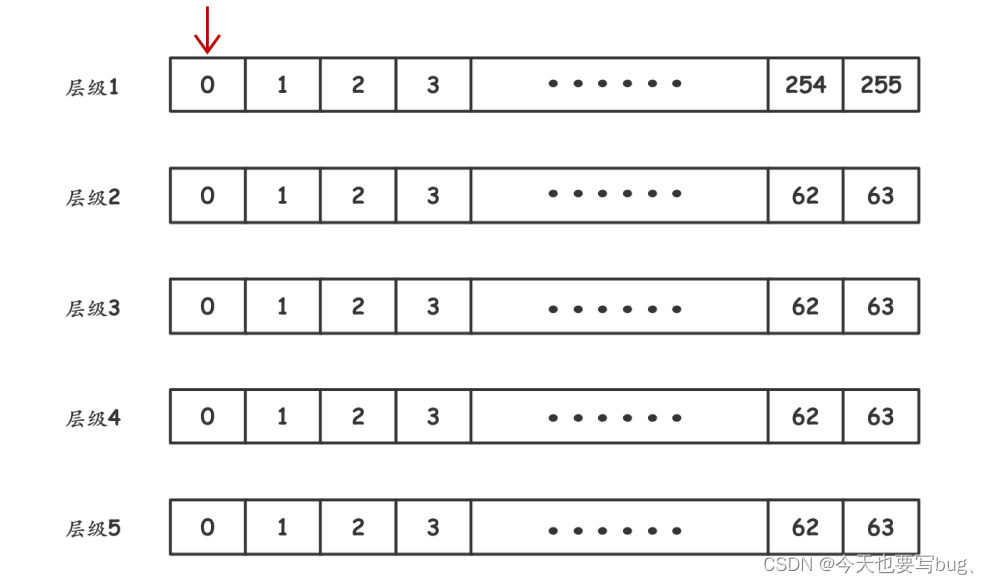
参照时钟表盘的运转规律,可以将定时任务根据触发的紧急程度,分布到不同层级的时间轮中;
假设时间精度为 10ms ;在第 1 层级每 10ms 移动⼀格;每移动⼀格执⾏该格⼦当中所有的定时任务;
当第 1 层指针从 255 格开始移动,此时层级 2 移动⼀格;层级 2 移动⼀格的⾏为定义为,将该格当中的定时任务重新映射到层级 1 当中;同理,层级 2 当中从 63 格开始移动,层级 3 格⼦中的定时任务重新映射到层级 2 ; 以此类推层级 4 往层级 3 映射,层级 5 往层级 4 映射。
只有任务在第一层时才会被执行,其他层都是将任务重新映射到上一层。
- timewheel.h:
#pragma once#include <stdint.h>#define TIME_NEAR_SHIFT 8
#define TIME_NEAR (1 << TIME_NEAR_SHIFT)
#define TIME_LEVEL_SHIFT 6
#define TIME_LEVEL (1 << TIME_LEVEL_SHIFT)
#define TIME_NEAR_MASK (TIME_NEAR - 1)
#define TIME_LEVEL_MASK (TIME_LEVEL - 1)typedef struct timer_node timer_node_t;
typedef void (*handler_pt)(struct timer_node *node);struct timer_node
{struct timer_node *next;uint32_t expire; //时间handler_pt callback; //回调函数uint8_t cancel; //是否删除int id; // 此时携带参数
};timer_node_t *add_timer(int time, handler_pt func, int threadid);void expire_timer(void);void del_timer(timer_node_t *node);void init_timer(void);void clear_timer();
- spinlock.h:
#pragma oncestruct spinlock
{int lock;
};void spinlock_init(struct spinlock *lock)
{lock->lock = 0;
}void spinlock_lock(struct spinlock *lock)
{while (__sync_lock_test_and_set(&lock->lock, 1)){}
}int spinlock_trylock(struct spinlock *lock)
{return __sync_lock_test_and_set(&lock->lock, 1) == 0;
}void spinlock_unlock(struct spinlock *lock)
{__sync_lock_release(&lock->lock);
}void spinlock_destroy(struct spinlock *lock)
{(void)lock;
}
- timewheel.cpp:
#include "spinlock.h"
#include "timewheel.h"
#include <string.h>
#include <stddef.h>
#include <stdlib.h>
#include <time.h>typedef struct link_list
{timer_node_t head;timer_node_t *tail;
} link_list_t;//多级时间轮
typedef struct timer
{//第一级link_list_t near[TIME_NEAR];// 2-4级link_list_t t[4][TIME_LEVEL];struct spinlock lock;uint32_t time;uint64_t current;uint64_t current_point;
} s_timer_t;static s_timer_t *TI = NULL;timer_node_t *link_clear(link_list_t *list)
{timer_node_t *ret = list->head.next;list->head.next = 0;list->tail = &(list->head);return ret;
}
//链接一个节点
void link(link_list_t *list, timer_node_t *node)
{list->tail->next = node;list->tail = node;node->next = 0;
}void add_node(s_timer_t *T, timer_node_t *node)
{uint32_t time = node->expire;uint32_t current_time = T->time;uint32_t msec = time - current_time;//根据时间if (msec < TIME_NEAR){ //[0, 0x100)link(&T->near[time & TIME_NEAR_MASK], node);}else if (msec < (1 << (TIME_NEAR_SHIFT + TIME_LEVEL_SHIFT))){ //[0x100, 0x4000)link(&T->t[0][((time >> TIME_NEAR_SHIFT) & TIME_LEVEL_MASK)], node);}else if (msec < (1 << (TIME_NEAR_SHIFT + 2 * TIME_LEVEL_SHIFT))){ //[0x4000, 0x100000)link(&T->t[1][((time >> (TIME_NEAR_SHIFT + TIME_LEVEL_SHIFT)) & TIME_LEVEL_MASK)], node);}else if (msec < (1 << (TIME_NEAR_SHIFT + 3 * TIME_LEVEL_SHIFT))){ //[0x100000, 0x4000000)link(&T->t[2][((time >> (TIME_NEAR_SHIFT + 2 * TIME_LEVEL_SHIFT)) & TIME_LEVEL_MASK)], node);}else{ //[0x4000000, 0xffffffff]link(&T->t[3][((time >> (TIME_NEAR_SHIFT + 3 * TIME_LEVEL_SHIFT)) & TIME_LEVEL_MASK)], node);}
}
//增加事件
timer_node_t *add_timer(int time, handler_pt func, int threadid)
{timer_node_t *node = (timer_node_t *)malloc(sizeof(*node));spinlock_lock(&TI->lock);node->expire = time + TI->time; // 每10ms加1 0node->callback = func;node->id = threadid;if (time <= 0){node->callback(node);free(node);spinlock_unlock(&TI->lock);return NULL;}add_node(TI, node);spinlock_unlock(&TI->lock);return node;
}void move_list(s_timer_t *T, int level, int idx)
{timer_node_t *current = link_clear(&T->t[level][idx]);while (current){timer_node_t *temp = current->next;add_node(T, current);current = temp;}
}void timer_shift(s_timer_t *T)
{int mask = TIME_NEAR;uint32_t ct = ++T->time;if (ct == 0){move_list(T, 3, 0);}else{// ct / 256uint32_t time = ct >> TIME_NEAR_SHIFT;int i = 0;// ct % 256 == 0while ((ct & (mask - 1)) == 0){int idx = time & TIME_LEVEL_MASK;if (idx != 0){move_list(T, i, idx);break;}mask <<= TIME_LEVEL_SHIFT;time >>= TIME_LEVEL_SHIFT;++i;}}
}void dispatch_list(timer_node_t *current)
{do{timer_node_t *temp = current;current = current->next;if (temp->cancel == 0)temp->callback(temp);free(temp);} while (current);
}void timer_execute(s_timer_t *T)
{int idx = T->time & TIME_NEAR_MASK;while (T->near[idx].head.next){timer_node_t *current = link_clear(&T->near[idx]);spinlock_unlock(&T->lock);dispatch_list(current);spinlock_lock(&T->lock);}
}void timer_update(s_timer_t *T)
{spinlock_lock(&T->lock);timer_execute(T);timer_shift(T);timer_execute(T);spinlock_unlock(&T->lock);
}void del_timer(timer_node_t *node)
{node->cancel = 1;
}s_timer_t *timer_create_timer()
{s_timer_t *r = (s_timer_t *)malloc(sizeof(s_timer_t));memset(r, 0, sizeof(*r));int i, j;for (i = 0; i < TIME_NEAR; i++){link_clear(&r->near[i]);}for (i = 0; i < 4; i++){for (j = 0; j < TIME_LEVEL; j++){link_clear(&r->t[i][j]);}}spinlock_init(&r->lock);r->current = 0;return r;
}uint64_t gettime()
{uint64_t t;struct timespec ti;clock_gettime(CLOCK_MONOTONIC, &ti);t = (uint64_t)ti.tv_sec * 100;t += ti.tv_nsec / 10000000;return t;
}void expire_timer(void)
{uint64_t cp = gettime();if (cp != TI->current_point){uint32_t diff = (uint32_t)(cp - TI->current_point);TI->current_point = cp;int i;for (i = 0; i < diff; i++){timer_update(TI);}}
}void init_timer(void)
{TI = timer_create_timer();TI->current_point = gettime();
}void clear_timer()
{int i, j;for (i = 0; i < TIME_NEAR; i++){link_list_t *list = &TI->near[i];timer_node_t *current = list->head.next;while (current){timer_node_t *temp = current;current = current->next;free(temp);}link_clear(&TI->near[i]);}for (i = 0; i < 4; i++){for (j = 0; j < TIME_LEVEL; j++){link_list_t *list = &TI->t[i][j];timer_node_t *current = list->head.next;while (current){timer_node_t *temp = current;current = current->next;free(temp);}link_clear(&TI->t[i][j]);}}
}
- tw-timer.cpp:
#include <stdio.h>
#include <unistd.h>#include <pthread.h>
#include <time.h>
#include <stdlib.h>
#include "timewheel.h"struct context
{int quit;int thread;
};struct thread_param
{struct context *ctx;int id;
};static struct context ctx = {0};void do_timer(timer_node_t *node)
{printf("timer expired:%d - thread-id:%d\n", node->expire, node->id);
}void *thread_worker(void *p)
{struct thread_param *tp = (struct thread_param *)p;int id = tp->id;struct context *ctx = tp->ctx;while (!ctx->quit){int expire = rand() % 200;add_timer(expire, do_timer, id);usleep(expire * (10 - 1) * 1000);}printf("thread_worker:%d exit!\n", id);return NULL;
}void do_quit(timer_node_t *node)
{ctx.quit = 1;
}int main()
{srand(time(NULL));ctx.thread = 8;pthread_t pid[ctx.thread];init_timer();add_timer(6000, do_quit, 100);struct thread_param task_thread_p[ctx.thread];int i;for (i = 0; i < ctx.thread; i++){task_thread_p[i].id = i;task_thread_p[i].ctx = &ctx;if (pthread_create(&pid[i], NULL, thread_worker, &task_thread_p[i])){fprintf(stderr, "create thread failed\n");exit(1);}}while (!ctx.quit){expire_timer();usleep(2500);}clear_timer();for (i = 0; i < ctx.thread; i++){pthread_join(pid[i], NULL);}printf("all thread is closed\n");return 0;
}