概述
时间轮是一个高性能,低消耗的数据结构,它适合用非准实时,延迟的短平快任务,例如心跳检测。在netty和kafka中都有使用。
比如Netty动辄管理100w+的连接,每一个连接都会有很多超时任务。比如发送超时、心跳检测间隔等,如果每一个定时任务都启动一个Timer,不仅低效,而且会消耗大量的资源。
在Netty中的一个典型应用场景是判断某个连接是否idle,如果idle(如客户端由于网络原因导致到服务器的心跳无法送达),则服务器会主动断开连接,释放资源。得益于Netty NIO的优异性能,基于Netty开发的服务器可以维持大量的长连接,单台8核16G的云主机可以同时维持几十万长连接,及时掐掉不活跃的连接就显得尤其重要。
A optimized for approximated I/O timeout scheduling.
You can increase or decrease the accuracy of the execution timing by.
- specifying smaller or larger tick duration in the constructor. In most
- network applications, I/O timeout does not need to be accurate. Therefore,
- the default tick duration is 100 milliseconds and you will not need to try
- different configurations in most cases.
大概意思是一种对“适当”I/O超时调度的优化。因为I/O timeout这种任务对时效性不需要准确。时间轮的概念最早由George Varghese和Tony Lauck在1996年的论文中提出,有兴趣的可以阅读一下。
《Hashed and Hierarchical Timing Wheels: Efficient Data Structures for Implementing a Timer Facility》
使用场景
HashedWheelTimer本质是一种类似延迟任务队列的实现,那么它的特点如上所述,适用于对时效性不高的,可快速执行的,大量这样的“小”任务,能够做到高性能,低消耗。
应用场景大致有:
- 心跳检测(客户端探活)
- 会话、请求是否超时
- 消息延迟推送
- 业务场景超时取消(订单、退款单等)
使用方式
引入netty依赖:
<dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId>
</dependency>
编写测试:
CountDownLatch countDownLatch = new CountDownLatch(1);HashedWheelTimer timer = new HashedWheelTimer(1, TimeUnit.SECONDS, 16);
log.info("current timestamp={}",System.currentTimeMillis());
timer.newTimeout((timeout) -> {log.info("task execute,current timestamp={}",System.currentTimeMillis());countDownLatch.countDown();}, 2000, TimeUnit.MILLISECONDS);countDownLatch.await();
timer.stop();
原理分析
1.数据结构

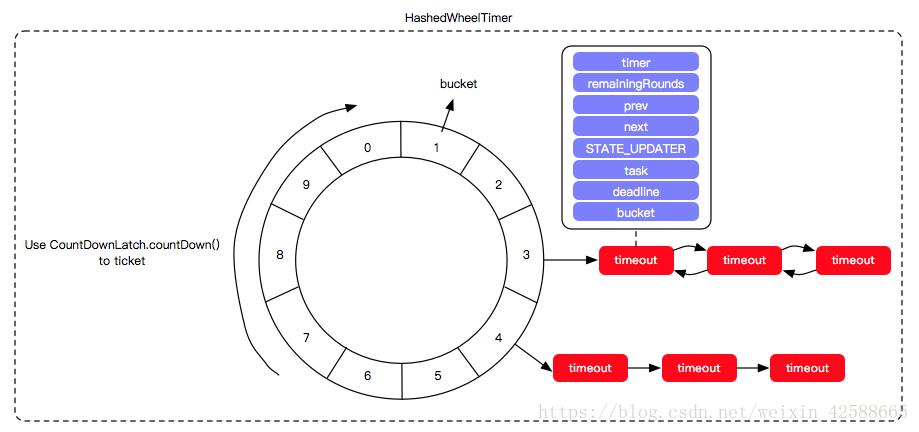
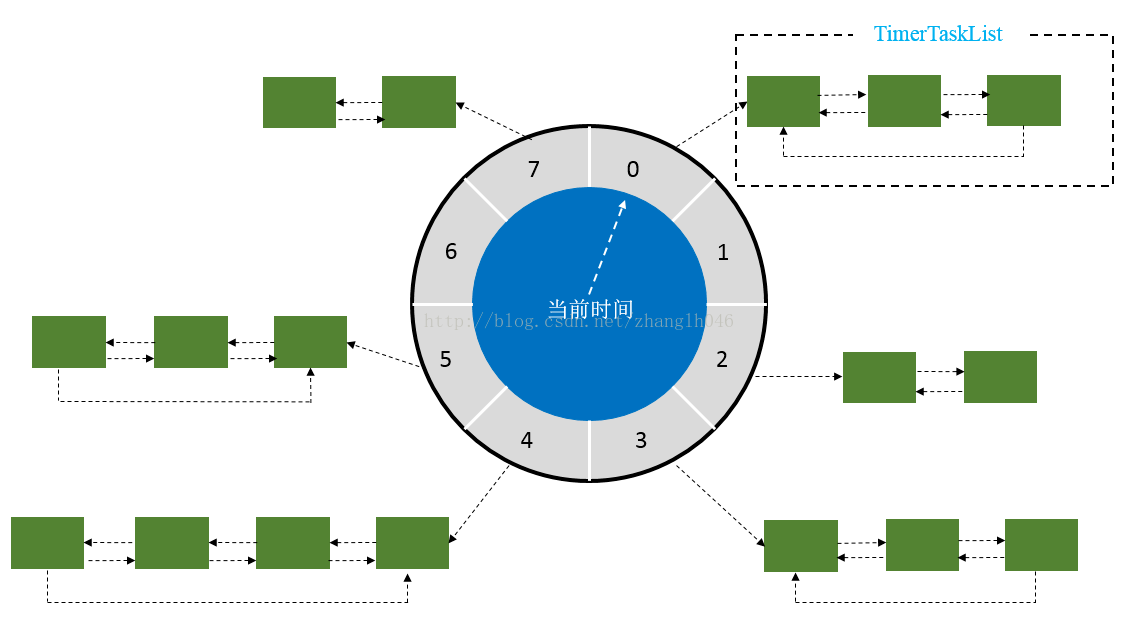
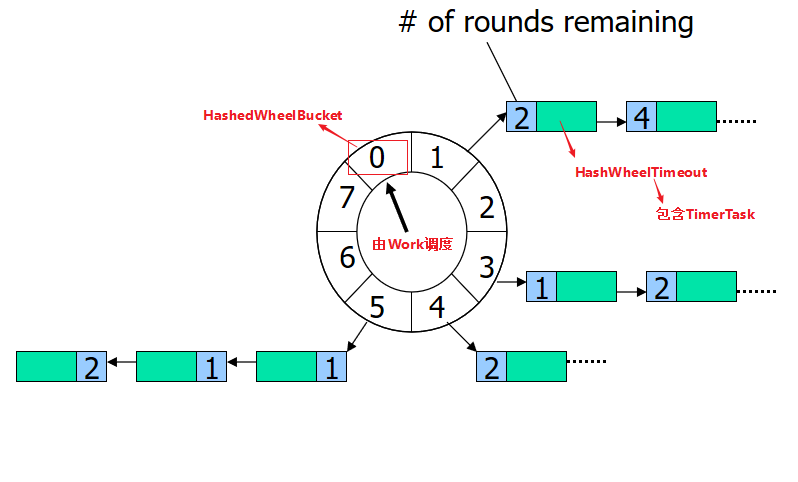
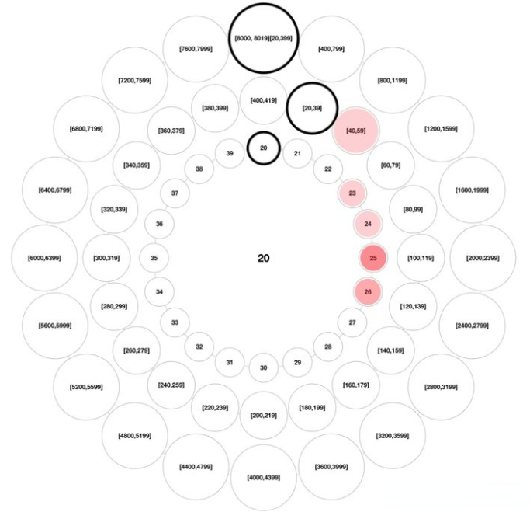
时间轮其实就是一种环形的数据结构,其设计参考了时钟转动的思维,可以想象成时钟,分成很多格子,一个格子代表一段时间(时间越短,精度越高,过段没有意义,根据具体使用场景裁定)。并用一个链表表示该格子上的到期任务,一个指针随着时间一格一格转动,并执行相应格子中的到期任务。任务通过取摸决定放入那个格子。如下图所示:

中间的圆轮代表一个时间周期,轮子上的每个节点关联的链表代表该时间点要触发的任务。如上图所示,假设一个格子是1秒,则整个wheel能表示的时间段为8s,假如当前指针指向2,此时需要调度一个3s后执行的任务,显然应该加入到(2+3=5)的方格中,指针再走3次就可以执行了;如果任务要在10s后执行,应该等指针走完一个round零2格再执行,因此应放入4,同时将round(1)保存到任务中。检查到期任务时应当只执行round为0的,格子上其他任务的round应减1。
2.源码分析

Timer
public interface Timer {Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);Set<Timeout> stop();
}
HashedWheelTimer本质上是一个Timer,用于将任务定时执行,newTimeout用于添加任务,stop用于终止Timer执行.
在分析源码之前我们先看一下netty时间轮实现中的核心组件,以便于分析过程中有比较清晰的脉络关系:

HashedWheelTimeout超时任务
private static final class HashedWheelTimeout implements Timeout {private static final int ST_INIT = 0;private static final int ST_CANCELLED = 1;private static final int ST_EXPIRED = 2;private static final AtomicIntegerFieldUpdater<HashedWheelTimeout> STATE_UPDATER =AtomicIntegerFieldUpdater.newUpdater(HashedWheelTimeout.class, "state");private final HashedWheelTimer timer;private final TimerTask task;private final long deadline;@SuppressWarnings({"unused", "FieldMayBeFinal", "RedundantFieldInitialization" })private volatile int state = ST_INIT;// remainingRounds will be calculated and set by Worker.transferTimeoutsToBuckets() before the// HashedWheelTimeout will be added to the correct HashedWheelBucket.long remainingRounds;// This will be used to chain timeouts in HashedWheelTimerBucket via a double-linked-list.// As only the workerThread will act on it there is no need for synchronization / volatile.HashedWheelTimeout next;HashedWheelTimeout prev;// The bucket to which the timeout was addedHashedWheelBucket bucket;...}
HashedWheelTimeout封装了待执行的任务TimerTask,并记录属于哪个时间轮,被添加到哪个bucket上,以及前后节点信息,并提供了任务取消、删除和超时执行的能力
Worker任务执行线程
private final class Worker implements Runnable {private final Set<Timeout> unprocessedTimeouts = new HashSet<Timeout>();private long tick;@Overridepublic void run() {// Initialize the startTime.startTime = System.nanoTime();if (startTime == 0) {// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.startTime = 1;}// Notify the other threads waiting for the initialization at start().startTimeInitialized.countDown();do {final long deadline = waitForNextTick();if (deadline > 0) {int idx = (int) (tick & mask);processCancelledTasks();HashedWheelBucket bucket =wheel[idx];transferTimeoutsToBuckets();bucket.expireTimeouts(deadline);tick++;}} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);// Fill the unprocessedTimeouts so we can return them from stop() method.for (HashedWheelBucket bucket: wheel) {bucket.clearTimeouts(unprocessedTimeouts);}for (;;) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (!timeout.isCancelled()) {unprocessedTimeouts.add(timeout);}}processCancelledTasks();}...
}
Worker封装了线程执行任务的能力,具体执行逻辑后续分析.
HashedWheelBucket存储任务的bucket
private static final class HashedWheelBucket {// Used for the linked-list datastructureprivate HashedWheelTimeout head;private HashedWheelTimeout tail;/*** Add {@link HashedWheelTimeout} to this bucket.*/public void addTimeout(HashedWheelTimeout timeout) {assert timeout.bucket == null;timeout.bucket = this;if (head == null) {head = tail = timeout;} else {tail.next = timeout;timeout.prev = tail;tail = timeout;}}...
}
HashedWheelBucket维护了存储待执行任务的双向链表,并提供了添加、删除和超时执行任务的能力。
2.初始化
回到刚开始创建时间轮的代码:
HashedWheelTimer timer = new HashedWheelTimer(1, TimeUnit.SECONDS, 16);
构造器有3个参数(时间单位不介绍):
- tickDuration:时间间隔;HashedWheelTimer 会在每个tick中检查是否有任何 TimerTask 落后于计划并执行它们。你可以通过在构造函数中指定更小或更大的时间间隔来提高或降低执行时间的准确性。在大多数网络应用程序中,I/O 超时不需要准确。因此,默认时间间隔为 100 毫秒,大多数情况下您不需要尝试不同的配置
- ticksPerWheel:时间轮的刻度,简单地说,轮子是一个TimerTasks的哈希表,它的哈希函数是“任务的超时时间”。每个轮子的默认刻度数(即轮子的大小)是 512。如果你要安排很多超时,你可以指定一个更大的值。
初始化会调用另外一个构造器:
public HashedWheelTimer(long tickDuration, TimeUnit unit, int ticksPerWheel) {this(Executors.defaultThreadFactory(), tickDuration, unit, ticksPerWheel);
}public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel) {this(threadFactory, tickDuration, unit, ticksPerWheel, true);
}
传入线程工厂,最后调用:
public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,long maxPendingTimeouts) {if (threadFactory == null) {throw new NullPointerException("threadFactory");}if (unit == null) {throw new NullPointerException("unit");}if (tickDuration <= 0) {throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);}if (ticksPerWheel <= 0) {throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);}// Normalize ticksPerWheel to power of two and initialize the wheel.wheel = createWheel(ticksPerWheel);mask = wheel.length - 1;// Convert tickDuration to nanos.long duration = unit.toNanos(tickDuration);// Prevent overflow.if (duration >= Long.MAX_VALUE / wheel.length) {throw new IllegalArgumentException(String.format("tickDuration: %d (expected: 0 < tickDuration in nanos < %d",tickDuration, Long.MAX_VALUE / wheel.length));}if (duration < MILLISECOND_NANOS) {if (logger.isWarnEnabled()) {logger.warn("Configured tickDuration %d smaller then %d, using 1ms.",tickDuration, MILLISECOND_NANOS);}this.tickDuration = MILLISECOND_NANOS;} else {this.tickDuration = duration;}workerThread = threadFactory.newThread(worker);leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null;this.maxPendingTimeouts = maxPendingTimeouts;if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {reportTooManyInstances();}
}
构造器中有两个核心点,创建HashedWheelBucket数组和创建工作线程,创建工作线程比较简单,我们直接看createWheel:
private static HashedWheelBucket[] createWheel(int ticksPerWheel) {if (ticksPerWheel <= 0) {throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);}if (ticksPerWheel > 1073741824) {throw new IllegalArgumentException("ticksPerWheel may not be greater than 2^30: " + ticksPerWheel);}ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];for (int i = 0; i < wheel.length; i ++) {wheel[i] = new HashedWheelBucket();}return wheel;
}
设计比较巧妙的是normalizeTicksPerWheel方法:
private static int normalizeTicksPerWheel(int ticksPerWheel) {int normalizedTicksPerWheel = 1;while (normalizedTicksPerWheel < ticksPerWheel) {normalizedTicksPerWheel <<= 1;}return normalizedTicksPerWheel;
}
初始化ticksPerWheel的值为不小于ticksPerWheel的最小2的n次方,这里其实性能不太好,因为当ticksPerWheel的值很大的时候,这个方法会循环很多次,方法执行时间不稳定,效率也不够。可以参考java8 HashMap的做法,推算过程比较稳定:
private int normalizeTicksPerWheel(int ticksPerWheel) {int n = ticksPerWheel - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;// 这里1073741824 = 2^30,防止溢出return (n < 0) ? 1 : (n >= 1073741824) ? 1073741824 : n + 1;
}
3.添加任务与启动
添加任务实现Timer接口的方法:
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {if (task == null) {throw new NullPointerException("task");}if (unit == null) {throw new NullPointerException("unit");}long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {pendingTimeouts.decrementAndGet();throw new RejectedExecutionException("Number of pending timeouts ("+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "+ "timeouts (" + maxPendingTimeouts + ")");}start();// Add the timeout to the timeout queue which will be processed on the next tick.// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;// Guard against overflow.if (delay > 0 && deadline < 0) {deadline = Long.MAX_VALUE;}HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);timeouts.add(timeout);return timeout;
}
此处有两个功能,启动时间轮和把任务添加到队列中,那么就有两个问题.
Q:为什么在添加任务的时候启动时间轮?
A:避免没有任务的情况下时间轮空转,造成cpu损耗
Q:为什么没有把任务添加到时间格里,而是放入了队列?
A:把包装后的任务放到了Mpsc高性能队列,等到下一个tick的时候随用随取
我们接着看任务启动实现:
public void start() {switch (WORKER_STATE_UPDATER.get(this)) {case WORKER_STATE_INIT:if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {workerThread.start();}break;case WORKER_STATE_STARTED:break;case WORKER_STATE_SHUTDOWN:throw new IllegalStateException("cannot be started once stopped");default:throw new Error("Invalid WorkerState");}// Wait until the startTime is initialized by the worker.while (startTime == 0) {try {startTimeInitialized.await();} catch (InterruptedException ignore) {// Ignore - it will be ready very soon.}}
}
通过原子变量AtomicIntegerFieldUpdater获取时间轮的workerState,如果是初始状态就通过原子操作执行启动,这里使用了AtomicIntegerFieldUpdater,也是JUC里面的类,原理是利用反射进行原子操作。有比AtomicInteger更好的性能和更低得内存占用。
最后while循环是等待worker线程启动完成,由于是多线程所以采用了CountDownLatch类型的startTimeInitialized.await.
3.任务超时操作
时间轮创建和初始化完成后,worker线程启动,开始处理任务超时操作,worker实现了Runnable接口重写run方法:
@Override
public void run() {// Initialize the startTime.startTime = System.nanoTime();if (startTime == 0) {// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.startTime = 1;}// Notify the other threads waiting for the initialization at start().startTimeInitialized.countDown();do {final long deadline = waitForNextTick();if (deadline > 0) {int idx = (int) (tick & mask);processCancelledTasks();HashedWheelBucket bucket =wheel[idx];transferTimeoutsToBuckets();bucket.expireTimeouts(deadline);tick++;}} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);// Fill the unprocessedTimeouts so we can return them from stop() method.for (HashedWheelBucket bucket: wheel) {bucket.clearTimeouts(unprocessedTimeouts);}for (;;) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (!timeout.isCancelled()) {unprocessedTimeouts.add(timeout);}}processCancelledTasks();
}
首先通知其他等待启动的线程结束等待,然后如果时间轮状态是启动,就一直轮训,通过线程休眠的方式等待到下一个tick,计算出格子的索引,移除被取消的任务,然后从Mpsc队列中取出来任务并放到对应的bucket中,然后通过idx索引找到对应的bucket触发超时操作.
private void transferTimeoutsToBuckets() {// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just// adds new timeouts in a loop.for (int i = 0; i < 100000; i++) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {// all processedbreak;}if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {// Was cancelled in the meantime.continue;}long calculated = timeout.deadline / tickDuration;timeout.remainingRounds = (calculated - tick) / wheel.length;final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.int stopIndex = (int) (ticks & mask);HashedWheelBucket bucket = wheel[stopIndex];bucket.addTimeout(timeout);}
}
bucket维度触发超时操作:
public void expireTimeouts(long deadline) {HashedWheelTimeout timeout = head;// process all timeoutswhile (timeout != null) {HashedWheelTimeout next = timeout.next;if (timeout.remainingRounds <= 0) {next = remove(timeout);if (timeout.deadline <= deadline) {timeout.expire();} else {// The timeout was placed into a wrong slot. This should never happen.throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));}} else if (timeout.isCancelled()) {next = remove(timeout);} else {timeout.remainingRounds --;}timeout = next;}
}
这里会执行移除操作、剩余轮数减和超时操作,接着看expire操作:
public void expire() {if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {return;}try {task.run(this);} catch (Throwable t) {if (logger.isWarnEnabled()) {logger.warn("An exception was thrown by " + TimerTask.class.getSimpleName() + '.', t);}}
}
看到这里,瞬间拨云见雾,把HashedWheelTimeout包装的任务取出来执行.
上边操作用图描述如下:

知识扩展
1.Mpsc队列
Mpsc(Multi producer single consumer)即多生产者单消费者队列,是Jctools中的高性能队列,也是netty经常的队列,如EventLoop中的事件队列就用Mpsc而不是jdk自带的队列。常用的有MpscArrayQueue和MpscChunkedArrayQueue,jdk的juc包下的相关并发实现也参考了Mpsc无锁队列.
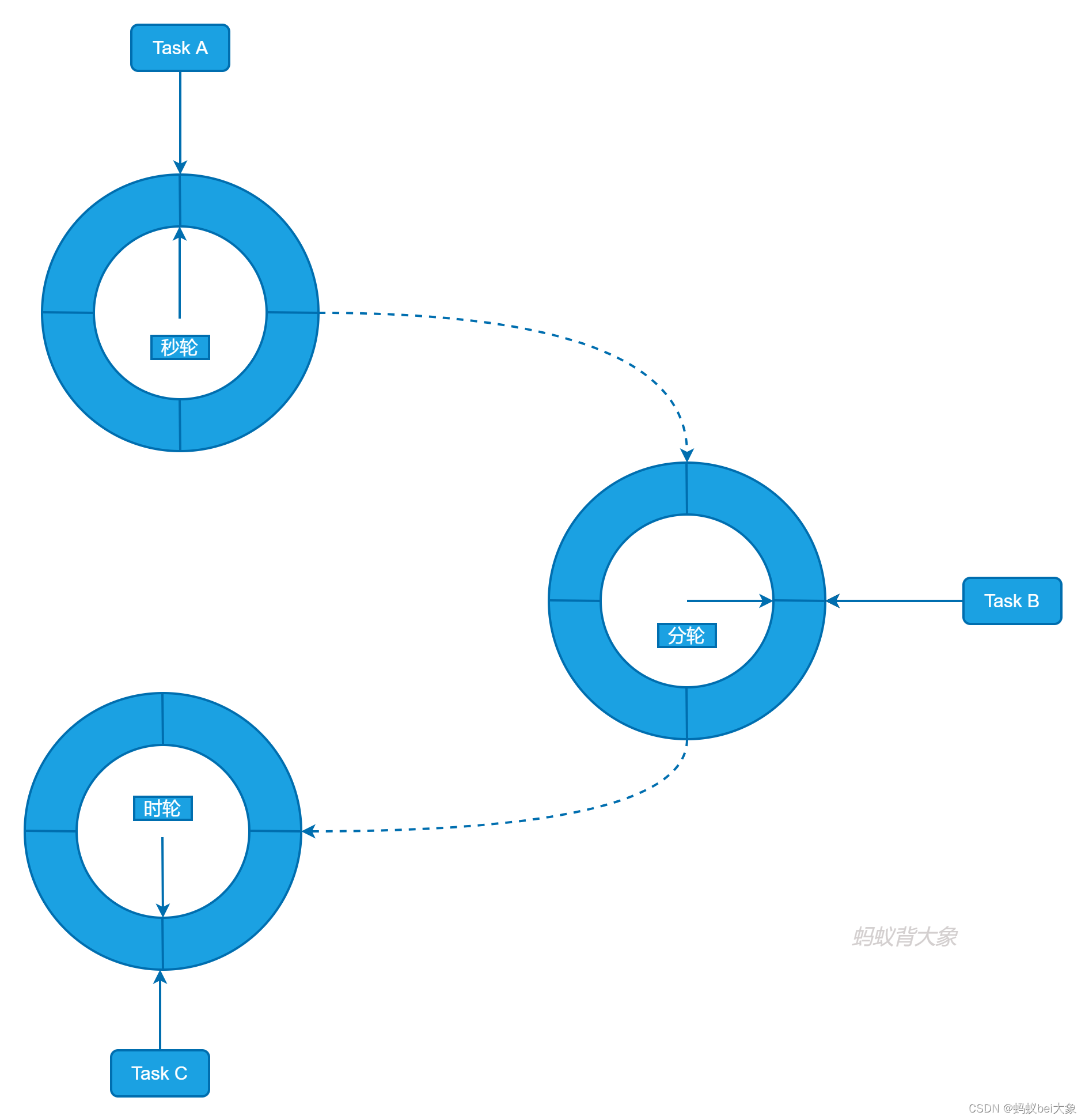
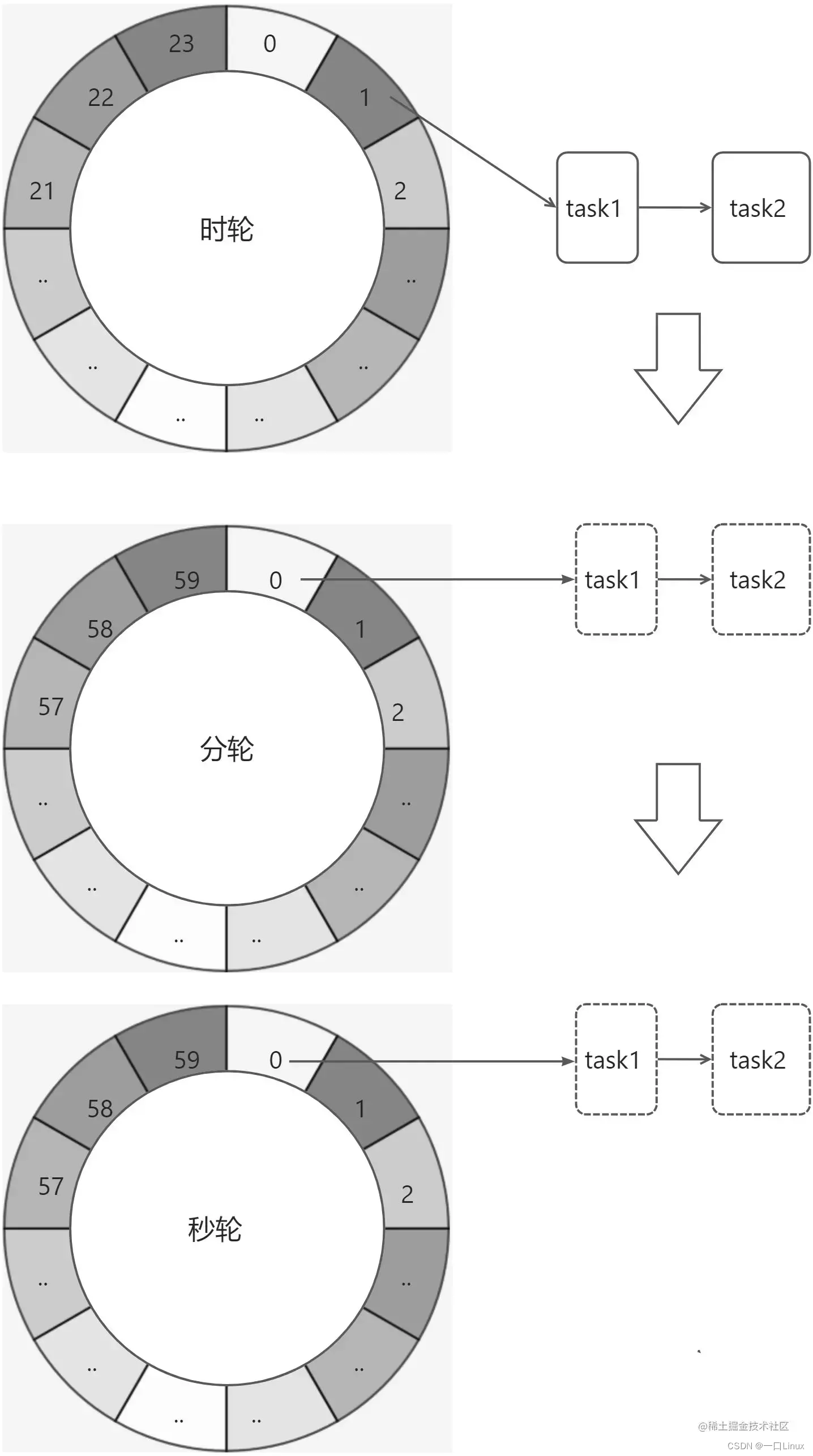
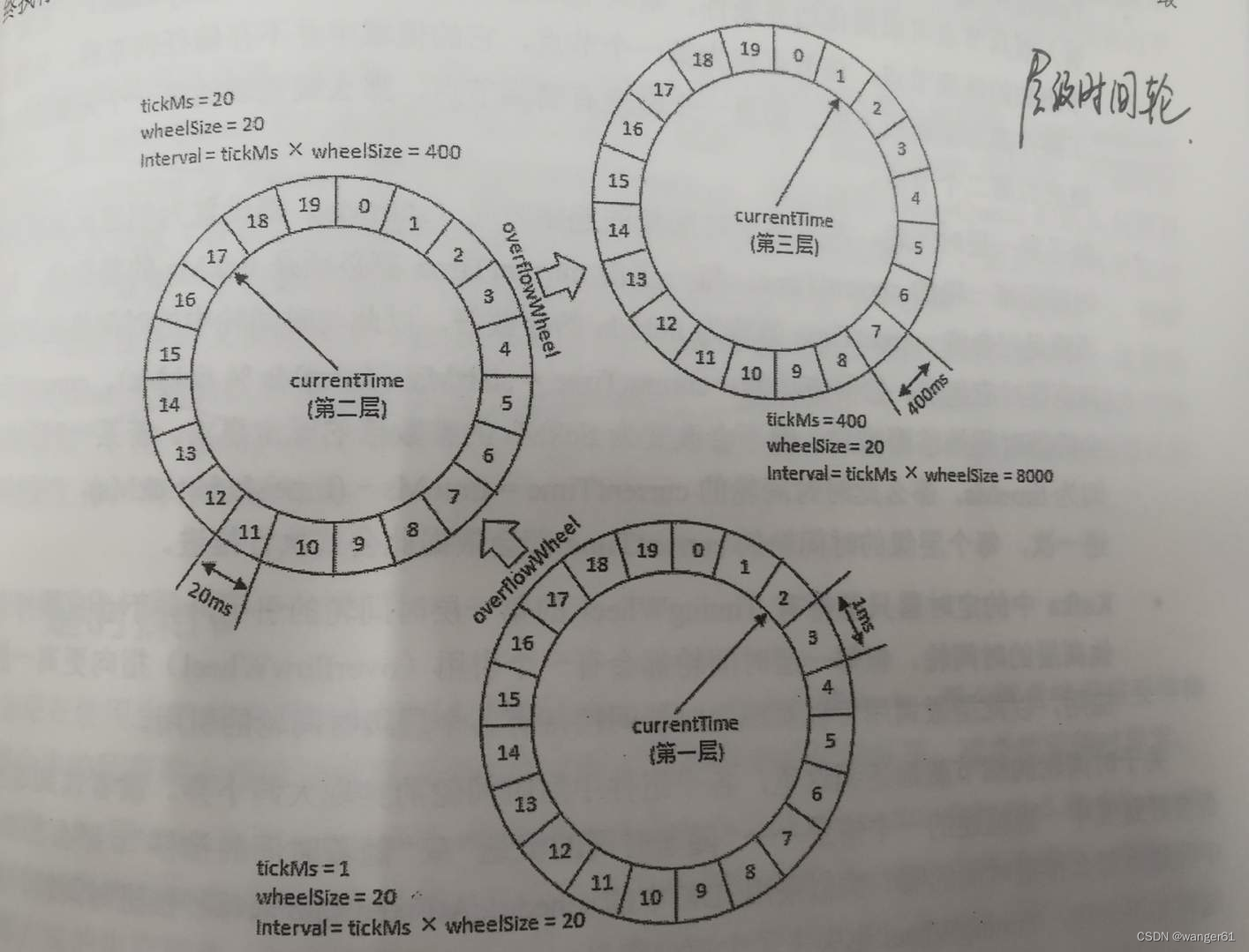
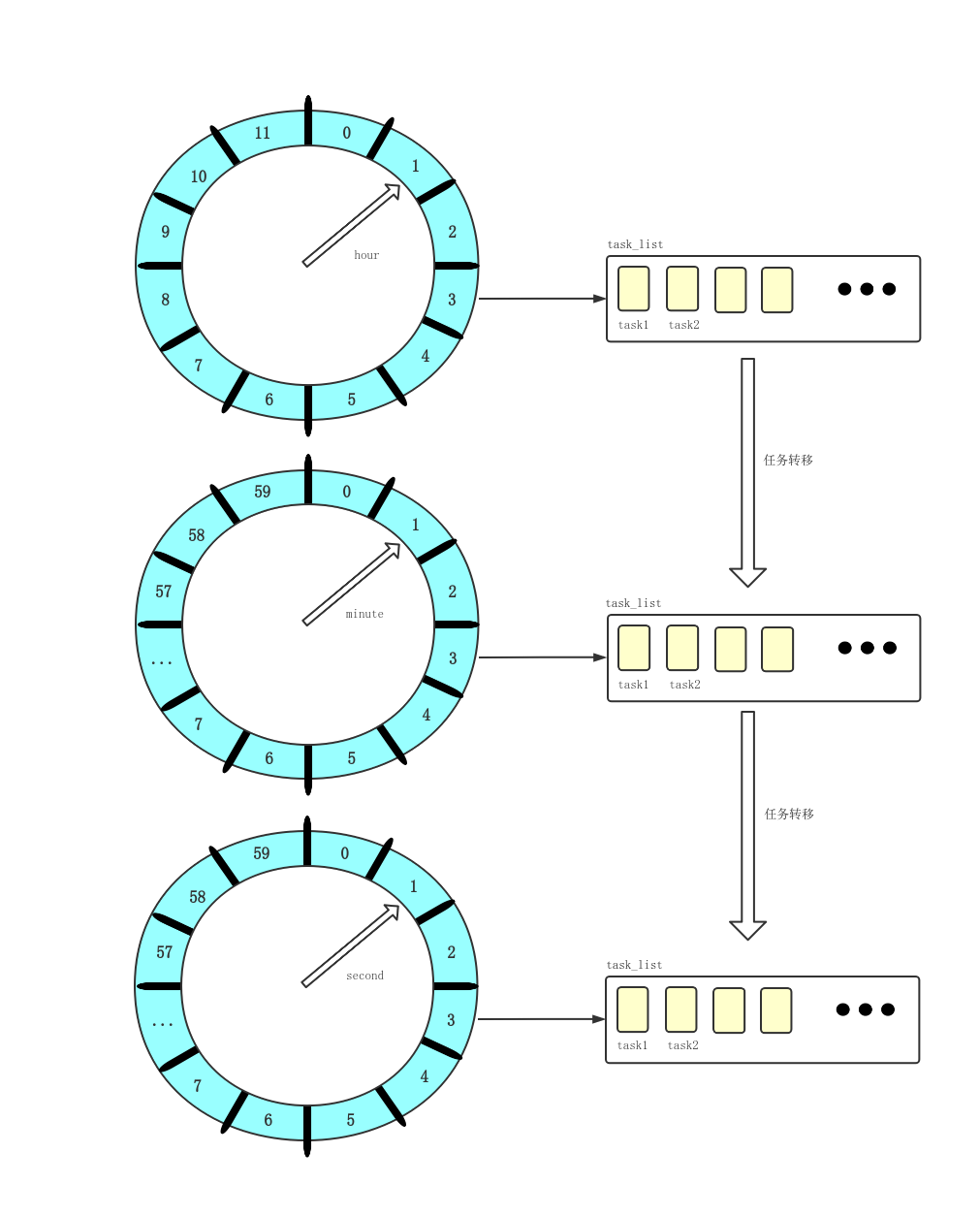
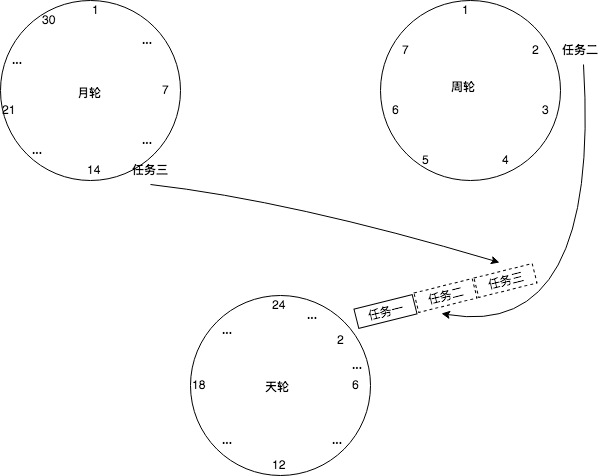
2.多重时间轮
当时间跨度很大时,提升单层时间轮的 tickDuration 可以减少空转次数,但会导致时间精度变低,层级时间轮既可以避免精度降低,又避免了指针空转的次数。如果有时间跨度较长的定时任务,则可以交给层级时间轮去调度。

总结
HashedWheelTimer时间轮是一个高性能,低消耗的数据结构,它适合用非准实时,延迟的短平快任务,比如心跳检测和会话探活,对于可靠性要求比较严格的延迟任务,时间轮目前并不是比较好的解决方案:
- 原生时间轮是单机的,在分布式和多实例部署的场景中乏力
- 宕机重新恢复执行,原生时间轮的存储是Mpsc队列,毫无疑问是内存存储,如果出现宕机或者重启,数据是不可恢复的
- 对于类似订单超时取消的场景,可以考虑时间轮+zk + db的方式实现,zk做中心化控制,避免超时任务在多节点重复执行,也即是数据去重,db做为延时任务的持久化存储,宕机可恢复;具体方案可行性有待考量,感兴趣可以自己推演
如果您喜欢或者对您有帮助,辛苦关注公众号!