首先不要将回归问题和logistic回归算法混为一谈,logistic回归不是回归算法,而是分类算法。
之前的分类问题的目标是预测输入数据点所对应的单一离散的标签,而这节要预测一个连续的而不是离散的标签,比如根据气象数据预测明天的气温等。
波士顿房价预测数据集
所包含的数据点相对较少,只有506个,分为404个训练样本和102个测试样本,输入数据的每个特征都有不同的取值范围,例如有些特性是比例取值是0-1,有的取值是1-12,还有的取值是0-100等等。
实现过程
加载数据集
(train_data,train_target),(test_data,test_target) = boston_housing.load_data()

每个样本都有13个数值特征,比如人均犯罪率,每个住宅的平均房间数等

准备数据
# 数据标准化
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
构建网络
def build_model():model = models.Sequential()model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))model.add(layers.Dense(64, activation='relu'))# 线性层,标量回归的典型设置(预测单一连续值的回归),添加激活函数将会限制输出范围model.add(layers.Dense(1))# mse是均放误差,预测值和目标值之差的平方# mae是平均绝对误差,它是预测值和目标值只差的绝对值model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])return model
网络的最后一层只有一个单元,没有激活,是一个线性层,这是标量回归的典型设置,因为如果添加激活函数就会限制输出范围。例如,如果最后一层添加sigmoid函数,网络只能预测0-1之间的值,这里最后一层纯线性,所以网络可以学会预测任意范围内的值。
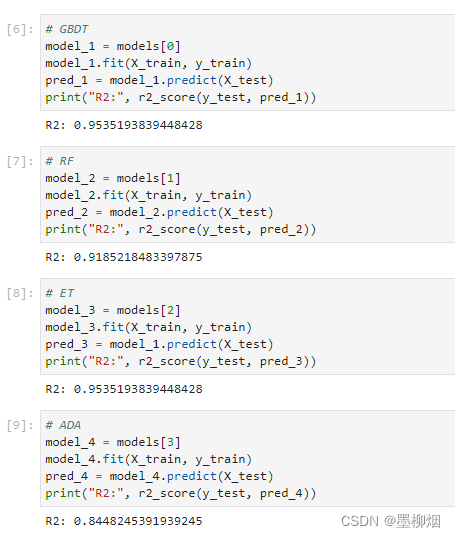
回归问题常用的损失函数是mse损失函数,也就是均方误差。
mae是平均绝对误差,它是预测值和目标值之差的绝对值,如果mae等于0.5,代表预测的房价和实际价格平均相差500美元。
利用k折验证来验证方法
由于数据点很少,验证集就非常少,因此验证集的划分方式可能会造成验证分数上有很大方差,这样就无法对模型进行可靠的评估。这种情况下最好的做法是k折交叉验证,这种方法可以把可用数据划分为k个分区(k通常取4或5),实例化k个相同模型,将每个模型在k-1个分区上训练,并在剩下一个分区上评估,模型的验证分数等于k个验证分数的平均值。

concentrate的作用
>>> a=np.array([1,2,3])
>>> b=np.array([11,22,33])
>>> c=np.array([44,55,66])
>>> np.concatenate((a,b,c),axis=0) # 默认情况下,axis=0可以不写
array([ 1, 2, 3, 11, 22, 33, 44, 55, 66]) #对于一维数组拼接,axis的值不影响最后的结果
k = 4
num_val_samples = len(train_data)//k
num_epochs = 500
all_scores=[]
for i in range(k):print('processing fold #', i)# 准备验证数据,第k个分区val_data = train_data[i*num_val_samples:(i+1)*num_val_samples]val_targets = train_target[i*num_val_samples:(i+1)*num_val_samples]# 准备训练数据:其他所有分区数据# 一次完成多个数组的拼接partial_train_data = np.concatenate([train_data[:i*num_val_samples],train_data[(i+1)*num_val_samples:]],axis=0)partial_train_targets = np.concatenate([train_target[:i*num_val_samples],train_target[(i+1)*num_val_samples:]],axis=0)model = build_model()# 保存每折的验证结果history = model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=1, verbose=0)
# 在验证数据上评估模型mae_history = history.history['val_mean_absolute_error']all_scores.append(mae_history)
# 计算所有轮次的k折验证分数平均值
average_mae_history = [np.mean([x[i] for x in all_scores]) for i in range(num_epochs)]

删除前10个数据点,因为它们的取值范围和曲线上其他点不一样,将每个数据点替换成前面数据点的指数移动平均值,以得到光滑的曲线。
绘制验证分数(删除前10个数据):
# 验证数据分数
def smooth_curve(points, factor=0.9):smoothed_points = []for point in points:if smoothed_points:previous = smoothed_points[-1]smoothed_points.append(previous*factor + point*(1-factor))else:smoothed_points.append(point)return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1,len(smooth_mae_history)+1),smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.legend()
plt.show()

完整代码:
from tensorflow.keras.datasets import boston_housing
from tensorflow.keras import layers,models
(train_data,train_target),(test_data,test_target) = boston_housing.load_data()
import numpy as np
# 数据标准化
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
def build_model():model = models.Sequential()model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))model.add(layers.Dense(64, activation='relu'))# 线性层,标量回归的典型设置(预测单一连续值的回归),添加激活函数将会限制输出范围model.add(layers.Dense(1))# mse是均放误差,预测值和目标值之差的平方# mae是平均绝对误差,它是预测值和目标值只差的绝对值model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])return model
model = build_model()
history = model.fit(train_data, train_target, epochs=80, batch_size=16, verbose=0)
test_mse_score,test_mae_score = model.evaluate(test_data,test_target)
print(test_mae_score)