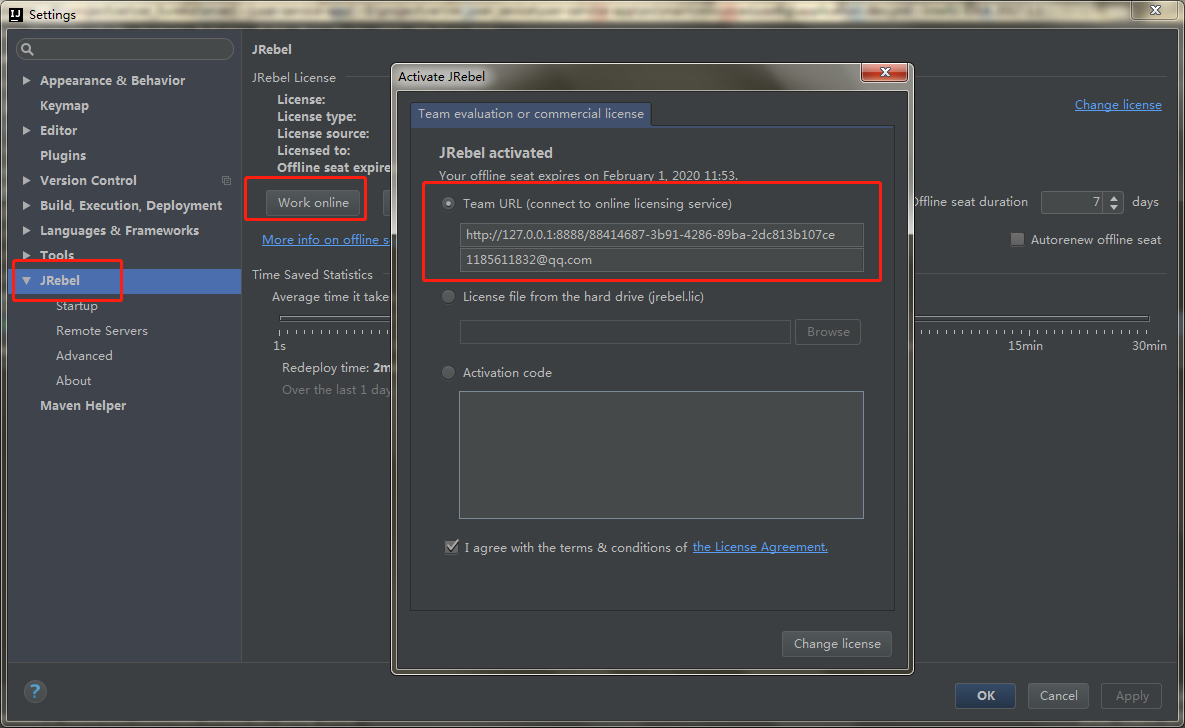
前言
最近在复习一些深度学习和机器学习的基础知识,看到分类和回归,这里记录一下。
一、回归
首先,回归应用的场景是用来输出一系列连续的值,然后用于预测等任务。回归的目的是为了找到最优拟合的曲线,这个曲线可以最好的接近数据集中的各个点。回归是对真实值的一种逼近预测,值不确定,当预测值与真实值相近时,误差较小时,认为这是一个好的回归。回归分析用在神经网络上,其最上层是不需要加上softmax函数的,而是直接对前一层累加即可。
1.线性回归
一般先采用线性回归方法得到最佳拟合直线,当出现欠拟合时,可采用局部加权线性回归,如果样本特征比样本数还多,就考虑使用缩减方法岭回归、lasso和前向逐步回归(即正则化)。
1)最小二乘法
直接上图:

这里求到W的最优解。
2)从概率角度看:
可以看作噪声为高斯分布,也可推出此结论。
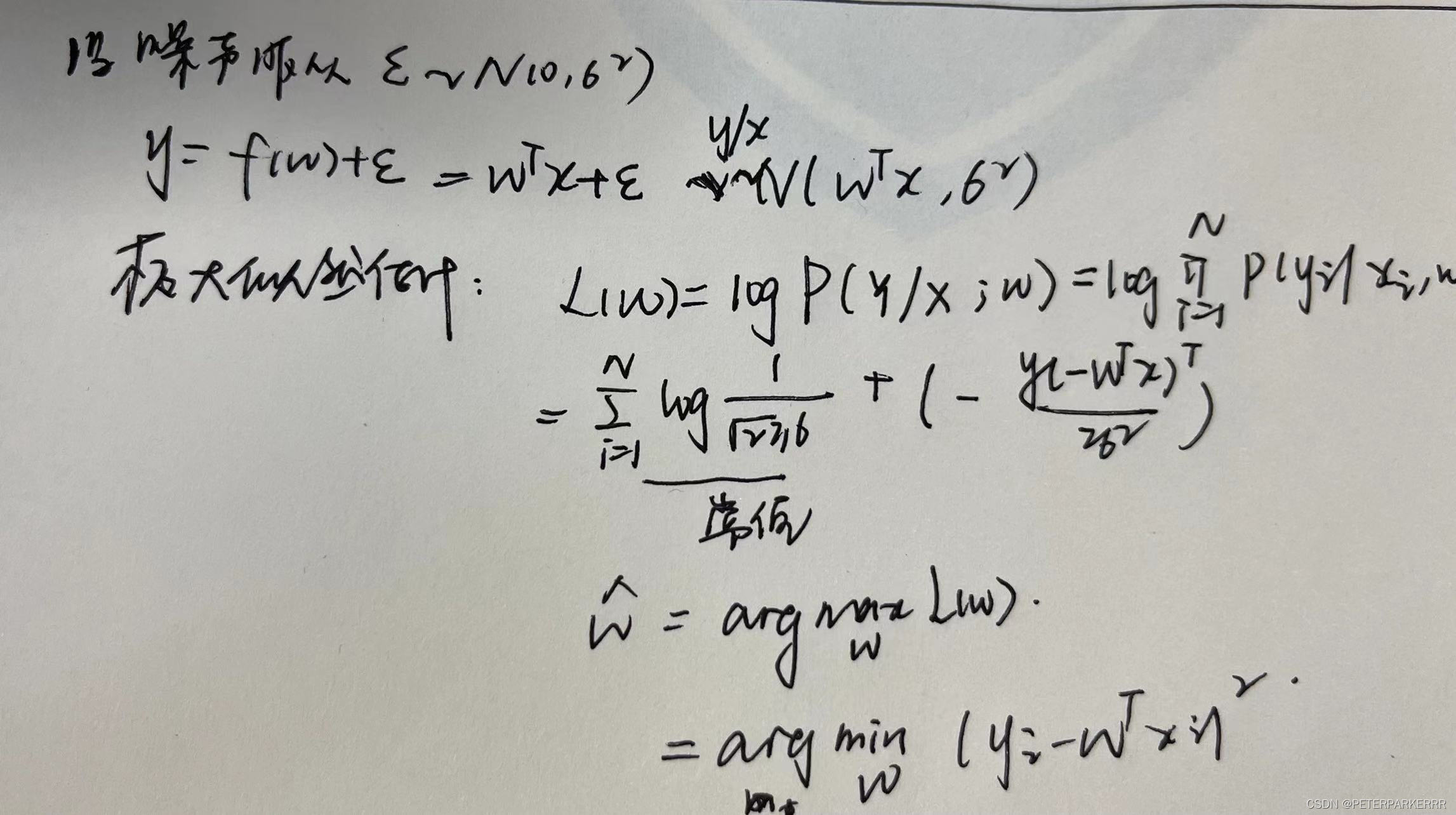
3)正则化
当样本维度高,样本数少时,会过拟合,例如极限情况,只有一个样本点那么将会有无数种拟合方式,那么解决办法有一是增加数据量,二是将样本维度降下来,三可以对参数增加正则化约束。
L1正则化(lasso):L1正则化是指权值向量w中各个元素的绝对值之和,可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择(为什么?稀疏表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小,因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系),一定程度上,L1也可以防止过拟合。数学表示:p(w) = ||w||1
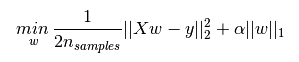
L2正则化(Ridage岭回归):也称作权重衰减(weight_decay),可以防止模型过拟合(overfitting),数学表示是权值向量w中各个元素的平方和然后再求平方根。
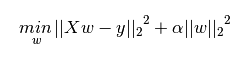
图片转自https://blog.csdn.net/zhaomengszu/article/details/81537197?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163849411116780366564498%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163849411116780366564498&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v29_name-2-81537197.first_rank_v2_pc_rank_v29&utm_term=l1%E6%AD%A3%E5%88%99%E5%8C%96&spm=1018.2226.3001.4187
推导过程:

这里插一句,在pytorch的代码中的权重衰减weight_decay对应什么,如下图。那么为什么权重衰减后就会避免过拟合?原理在于 (1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。

加入正则化以后的结果:
加入正则化后,loss下降的速度会变慢,准确率Accuracy的上升速度会变慢,并且未加入正则化模型的loss和Accuracy的浮动比较大(或者方差比较大),而加入正则化的模型训练loss和Accuracy,表现的比较平滑。并且随着正则化的权重lambda越大,表现的更加平滑。这其实就是正则化的对模型的惩罚作用,通过正则化可以使得模型表现的更加平滑,即通过正则化可以有效解决模型过拟合的问题。
2.逻辑回归
之前我们了解到了多元线性回归是用线性的关系来拟合一个事情的发生规律,找到这个规律的表达公式,将得到的数据带入公式以用来实现预测的目的,我们习惯将这类预测未来的问题称作回归问题。机器学习中按照目的不同可以分为两大类:回归和分类,逻辑回归就可以用来完成分类任务。重点:逻辑回归不是回归
应用场景:比如根据人的饮食,作息,工作和生存环境等条件预测一个人"有"或者"没有"得恶性肿瘤,可以先通过回归任务来预测人体内肿瘤的大,取一个平均值作为阈值,假如平均值为y,肿瘤大小超过y为恶心肿瘤,无肿瘤或大小小于y的为非恶性。这就是一个二分类问题。
所以逻辑回归需要做两件事:
1、选定一个阈值进行分类。
2、解决有些样本偏离群体太多的问题
1)sigmoid函数
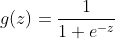
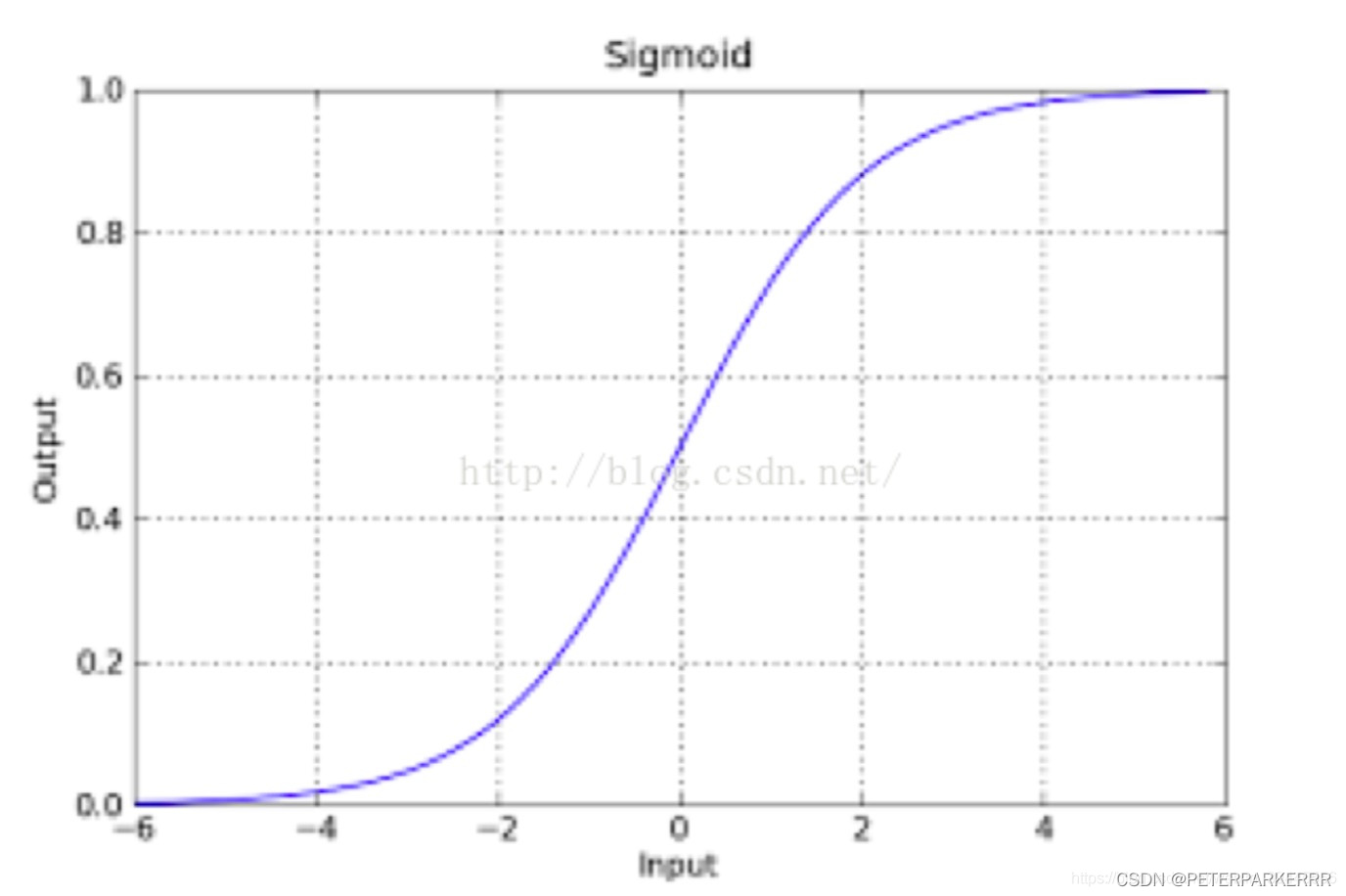
该函数具有很强的鲁棒性,并且将函数的输入范围(-∞,∞)映射到了输出的(0,1)之间,相当于把函数强制掰弯,这样就解决了函数离群值太大的问题,且具有概率意义,将一个样本输入到我们学习到的函数中概率范围为(0,1)。
2)选定阈值
当我选阈值为0.5,那么小于0.5的当作是负例,这样选不一定准确,具有误差,无论怎么选,误差都是存在的.所以我们选定阈值的时候就是在选择可以接受误差的程度。这里只是用0.5来举例,具体阈值的选择要根据情况具体分析。
3)逻辑回归的损失函数
用最大似然估计求解

求解损失函数就是用SGD方法。
注:逻辑回归在正负数据样本比例相差悬殊时效果不好,原因在于它是利用极大似然估计求解的,表示的意义是所有样本都被预测正确的最大概率,所以正负样本比例应该在一个平衡,此时我们需要对数据进行欠采样/重采样来让正负例保持一个差不多的平衡。
二、分类
上面说过逻辑回归可以看作二分类,分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一幅图片上的动物是花还是树,分类通常是建立在回归之上,多分类问题的最后一层通常要使用softmax函数。分类并没有逼近的概念,最终正确结果只有一个,对就是对,错就是错,不会有相近的概念。线性分类分为硬输出和软输出。
1、**硬输出:**输出为离散的0和1。
1)感知机
1957年提出,核心思想:错误驱动;感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型。目的是利用一条线或是一个超平面将不同类别的数据分隔开,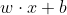 对于这条线的话他的斜率就是w来确定的,实际上这个w是这个平面的法向量(就是直线的斜率)来控制他的倾斜程度的;这个b就是截距,实际上我们要完成的就是通过这两个平面把这两类数据进行一个划分,那么我们可以找到这样一条直线或者说这样一个超平面,正好把两类数据给他切割开,放在这个平面的两边,那么这样的话我们就认为我们的感知机就完成了他的分类的功能,就可以把这些样本分离成正、负两类。对于sign函数看他大于0还是小于0实际上是看他在超平面的哪一侧。也就是说他的夹角,这个每一个样本它对应的向量的夹角,是和法向量夹角之间的一个关系,如果他是正向范围说明他就是一个正例;如果和他是逆向的那么就是说明他在平面的另外一侧。
对于这条线的话他的斜率就是w来确定的,实际上这个w是这个平面的法向量(就是直线的斜率)来控制他的倾斜程度的;这个b就是截距,实际上我们要完成的就是通过这两个平面把这两类数据进行一个划分,那么我们可以找到这样一条直线或者说这样一个超平面,正好把两类数据给他切割开,放在这个平面的两边,那么这样的话我们就认为我们的感知机就完成了他的分类的功能,就可以把这些样本分离成正、负两类。对于sign函数看他大于0还是小于0实际上是看他在超平面的哪一侧。也就是说他的夹角,这个每一个样本它对应的向量的夹角,是和法向量夹角之间的一个关系,如果他是正向范围说明他就是一个正例;如果和他是逆向的那么就是说明他在平面的另外一侧。
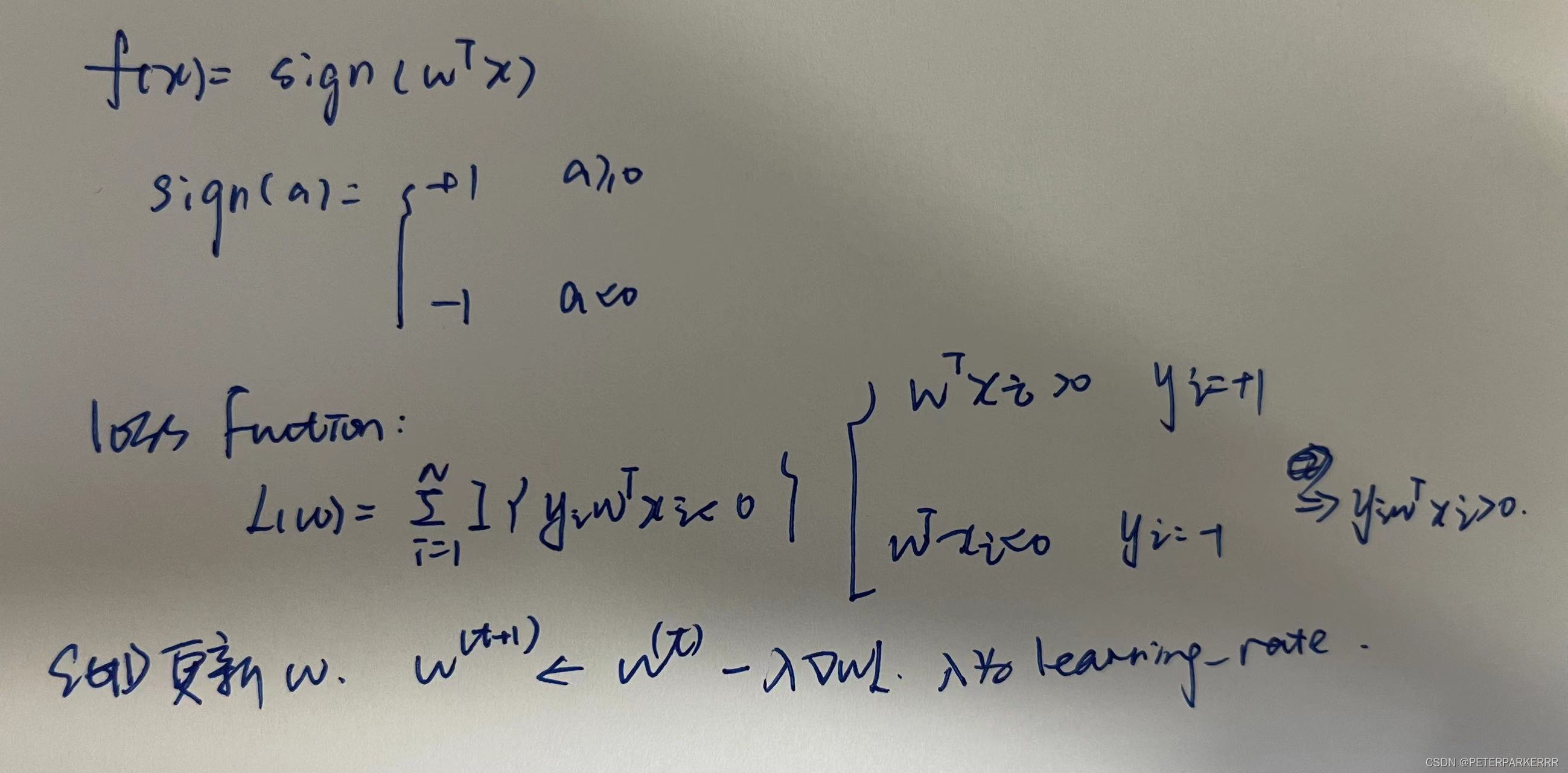
2)线性判别分析(LDA)
将数据在低维度上进行投影,投影后希望同一类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大,总结就是类内小,类间大。数学上来说就是类内方差小,类外的方差大。

2、**软输出:**输出为概率。
这里引入两个概念:
生成模型:学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布,能够学习到数据生成的机制,以统计学和Bayes作为理论基础。
判别模型:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。
数据要求:生成模型需要的数据量比较大,能够较好地估计概率密度;而判别模型对数据样本量的要求没有那么多。
1)概率判别模型:逻辑回归(LR)见上文。
思路:直接求P(y|x)
2)概率生成模型:高斯判别分析(GDA)
GDA的思路:P(y|x)正比于P(x|y)* P(y),求后者。

3)概率生成模型:朴素贝叶斯
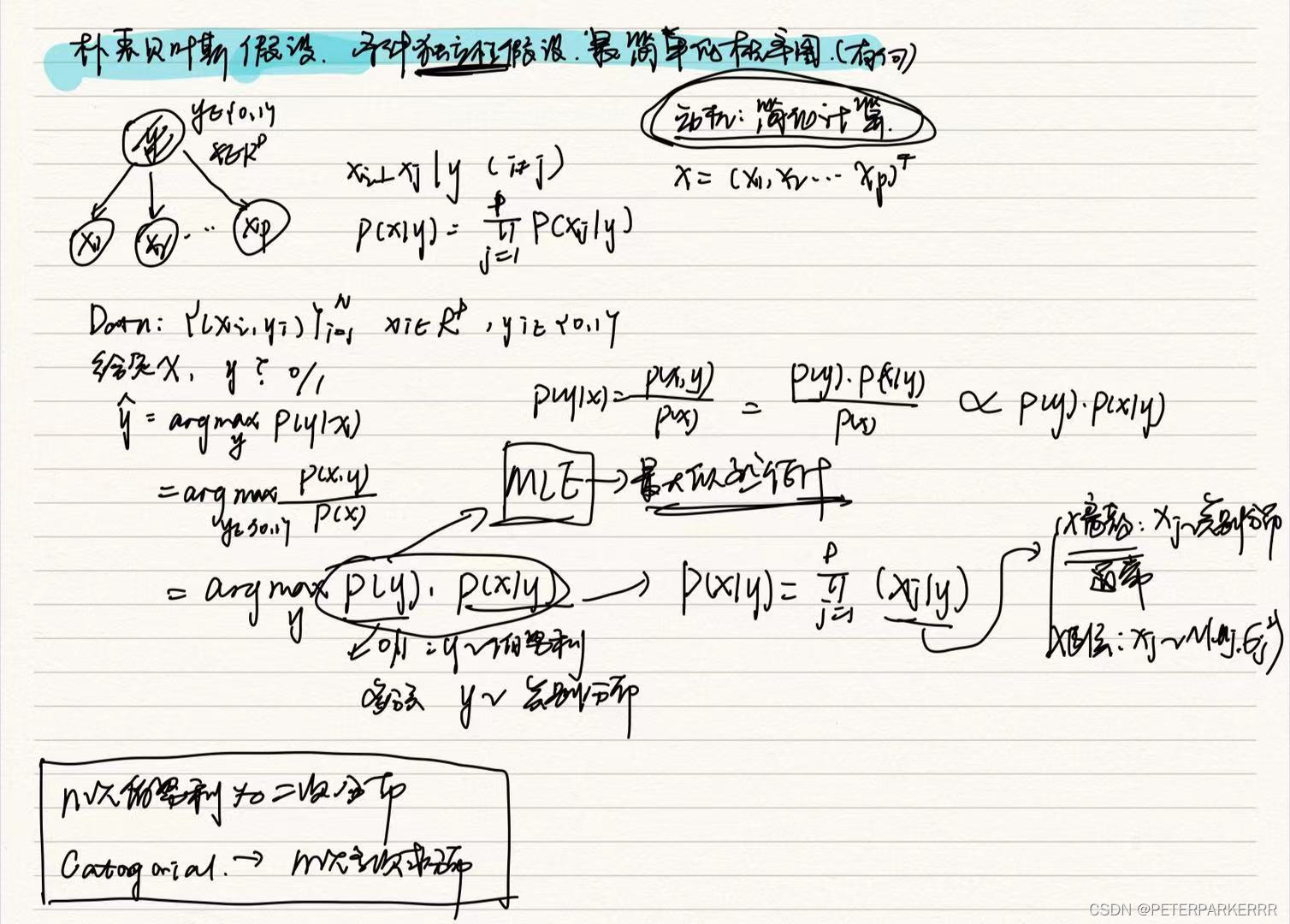
总结
本文主要阐述了分类和回归的区别,注意逻辑回归是分类不是回归,后续有补充我再写。