Jieba
- jieba的安装
- 主要功能
- 1.主要有三种模式:
- 2. 加载词典
- 3.词性标注
- 4.关键词提取
- 5.Tokenize:返回词语在原文的起止位置
jieba的安装
先在 [http://pypi.python.org/pypi/jieba/]下载 ,解压后运行 python setup.py install
或者pin install jieba
import jieba
'''
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式print("Paddle Mode: " + '/'.join(list(seg_list))) #join 列表格式化输出 通过 / 来 连接各个字符串
'''
seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多。", cut_all=True)
print("Full Mode(全模式): " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多.", cut_all=False)
print("Default Mode(精准模式): " + "/ ".join(seg_list)) # 精确模式seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多.") # 默认是精确模式
print("默认为精准",'/'.join(seg_list))seg_list = jieba.cut_for_search("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多。") # 搜索引擎模式
print("搜索引擎模式",'/'.join(seg_list))

可以使用,则说明安装成功。
(但在安装paddle出现了问题,在python37环境是可以使用,在conda下就出现报错,待解决)
conda也有jieba,paddle第三方库。

主要功能
1.主要有三种模式:
- 全模式
- 精准模式
- 搜索引擎模式
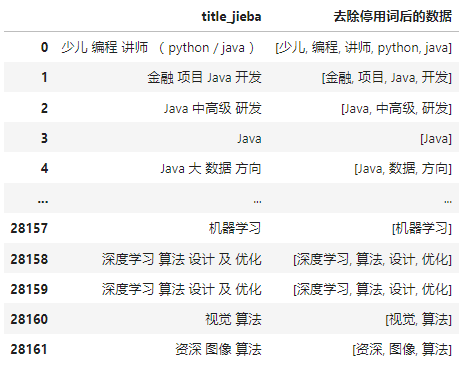
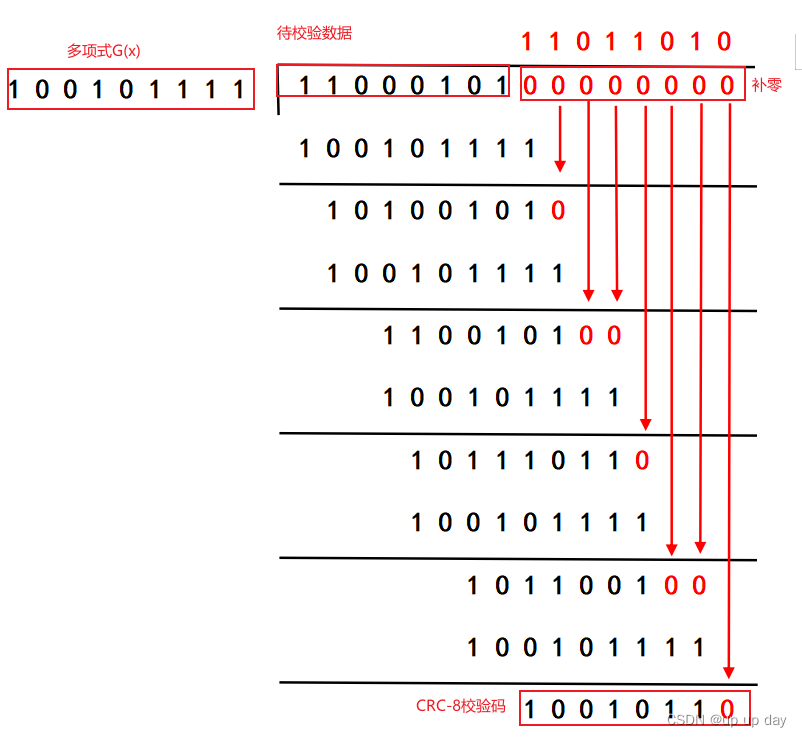
如上图(1)所示
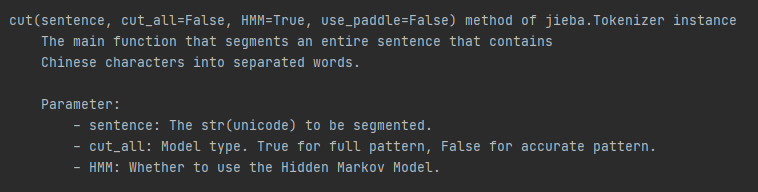
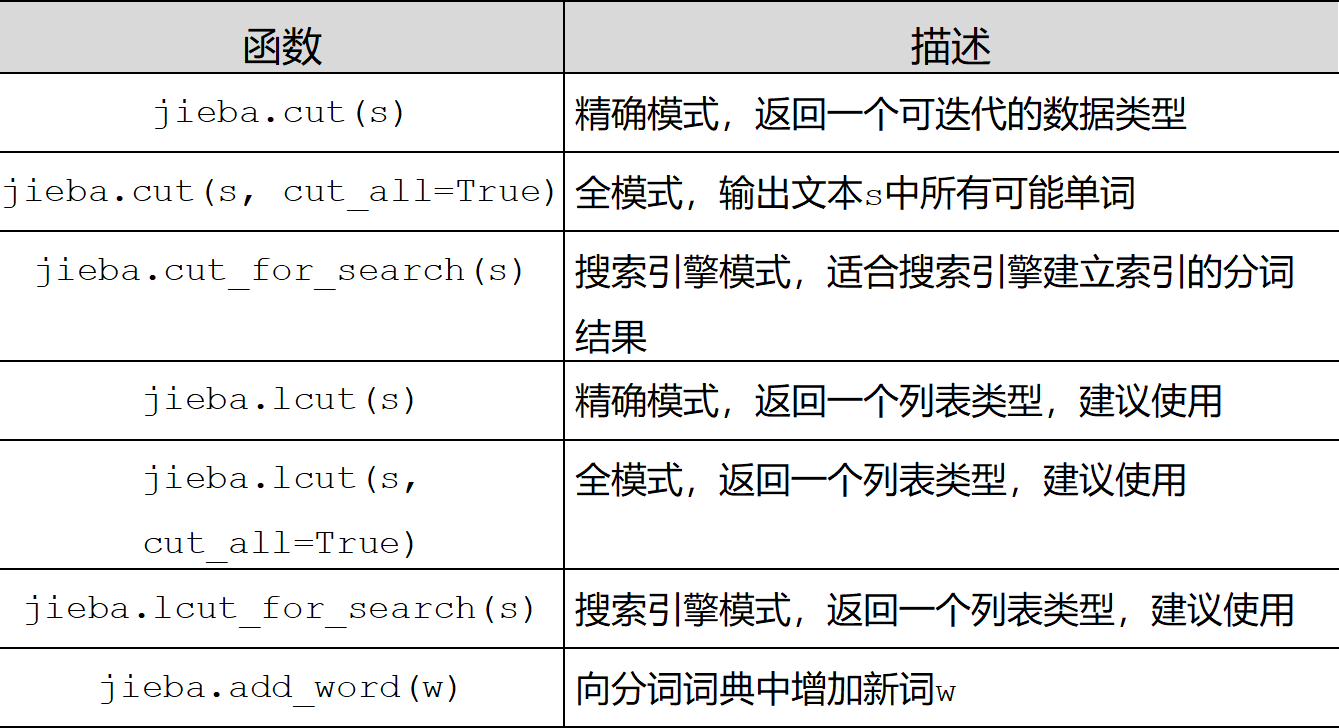
jieba.cut()有四个参数:sentence, 句子(str)、cut_all是否使用全模式, HMM是否使用HMM(默认使用), use_paddle是否启动paddle模式
jieba.cut_for_search()有两个参数,需要分词的字符串;是否使用 HMM 模型
jieba.cut() 和jieba.cut_for_search() 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语
或者
jieba.lcut() 和 jieba.lcut_for_search() 返回则是list
2. 加载词典
虽然jieba具有识别新词的功能,但也可以自行添加自己的创建的词典,提高自己的正确率。
jieba,load_userdict(file_name) file_name 为文件类对象或自定义词典的路径
词典格式:一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
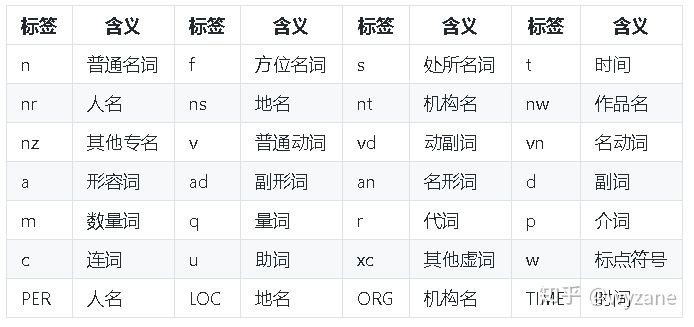
3.词性标注
提供paddle模式下的词性标注功能。paddle模式采用延迟加载方式,通过enable_paddle()安装paddlepaddle-tiny,并且import相关代码;
import jieba
import jieba.posseg as pseg
'''
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式print("Paddle Mode: " + '/'.join(list(seg_list))) #join 列表格式化输出 通过 / 来 连接各个字符串seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多。", cut_all=True)
print("Full Mode(全模式): " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多.", cut_all=False)
print("Default Mode(精准模式): " + "/ ".join(seg_list)) # 精确模式seg_list = jieba.cut("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多.") # 默认是精确模式
print("默认为精准",'/'.join(seg_list))seg_list = jieba.cut_for_search("随着移动互联网的快速发展,我们进入了信息爆炸时代。当前通过互联网提供服务的平台越来越多。") # 搜索引擎模式
print("搜索引擎模式",'/'.join(seg_list))print(help(jieba.cut))
'''
jieba.load_userdict('./data/dict.txt.big')
test_sent = (
"近年来,智能控制已成为先进控制的一个热点,该控制主要包括专家系统、模糊控制、神经网络等。专家系统可用于故障诊断、过程的监督控制等,它作为智能控制的一种重要工具,")
word = pseg.cut("我叫方小明,来自于北京,喜欢打篮球和游泳。") #jieba默认模式
words = jieba.cut(test_sent)
for word_1,flag in word :print('%s %s'%(word_1,flag))
print('/'.join(words))
jieba.enable_paddle() #启动paddle模式。 0.40版之后开始支持,早期版本不支持
words = jieba.cut(test_sent,use_paddle=True)
word=pseg.cut("我叫方小明,来自于北京,喜欢打篮球和游泳。",use_paddle=True)
print('/'.join(words))
for word_2 ,flag in word:print('%s %s'%(word_2,flag))

4.关键词提取
- 基于 TF-IDF 算法的关键词抽取
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
-allowPOS 仅包括指定词性的词,默认值为空,即不筛选
import jieba.analyseprint('-'*40)
print(' TF-IDF')
print('-'*40)
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):print('%s %s' % (x, w))
输出如下:

- 基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False,
allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。 - jieba.analyse.TextRank() 新建自定义 TextRank 实例
- jieba.analyse.textrank(sentence, topK=20, withWeight=False,
基本思想:
将待抽取关键词的文本进行分词
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
计算图中节点的PageRank,注意是无向带权图
print('-'*40)
print(' TextRank')
print('-'*40)for x, w in jieba.analyse.textrank(s, withWeight=True):print('%s %s' % (x, w))

5.Tokenize:返回词语在原文的起止位置
jieba.tokenize() 主要有两个参数;原本;模式(mode)。返回list[word;start;end]
mode='search’为搜索模式
result = jieba.tokenize('公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元')
for tk in result:print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))print('-'*40)
print(' 搜索模式')
print('-'*40)result = jieba.tokenize('公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元', mode='search')
for tk in result:print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
‘
参考:结巴学习github