OpenAI gym

OpenAI gym是强化学习最常用的标准库,如果研究强化学习,肯定会用到gym。
gym有几大类控制问题,第一种是经典控制问题,比如cart pole和pendulum。
Cart pole要求给小车一个左右的力,移动小车,让他们的杆子恰好能竖起来,pendulum要求给钟摆一个力,让钟摆也恰好能竖起来。

第二种是你最常见的Atari games,小时候在小霸王游戏机上玩的。pong里面的agent是这个乒乓球拍,你让球拍上下运动目标是接住对手的球,并且让对手接不住你的球。
Space invader里面的agent是这个小飞机,可以左右移动,也可以发射炮弹。
Break oUt里面的agent是下面的球拍,可以左右移动,目标是接触球,并且把上面的砖头尽可能多的打掉。

第三种问题是连续控制问题,比如控制蚂蚁人,还有猎豹走路,这个模拟叫做MuJoCo,它可以模拟重力等物理量,AI需要控制这些机器人站立和走路,如果设计出一种强化学习的算法,你怎么知道你的算法是否比别人的算法更好或者更快?
这就需要在标准数据集上检验算法的效果。
所有搞强化学习的学者都会用gym来测试算法的优劣,比如你可以用MuJoCo库里面人形机器人来检验你的算法,一开始这个机器人总是会摔倒,慢慢的他就能站一会儿了,慢慢的站的时间越来越长,慢慢的机器人还能没病走两步,随后会学会小跑了,然后越跑越远,经过多次迭代之后它能跑得挺远的。

用gym这个系统来做实验很容易,首先要按照官方文done来安装gym,安装好之后就可以在Python里面调用gym的函数了。
首先是import gym,然后要生成环境,需要用gym.make()这个函数。
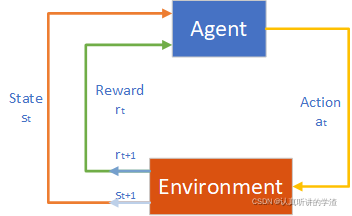
如果要训练AI解CartPole这个问题,就用CartPole作为make函数的输入,make函数返回env这个对象,env就是环境environment,AI可以控制小车跟环境交互,AI让这个小车向左或者向右走,环境根据车和棒子的位置和运动,然后用力学定律去算这根棒子的力和运动得到新的状态,得到环境env之后,就像下面这段代码一样,让agent跟环境交互,首先用env.reset()函数去重置环境,不管小车和棒子之前在哪儿,都会回到原点,这个函数会告诉我们初始状态即为State,然后就是重复下面的循环了,每一轮循环里agent作为一个动作,然后环境会更新状态给出奖励。

Env.render()是渲染,把游戏里面发生的展示给人看,运行render函数,python就会自动弹出一个窗口来显示cart pole这个游戏。
Action=env.action_space.sample(),这个函数随机均匀的抽样一个动作即为action。
实际上我们要根据policy函数或者是Q函数来算出一个action。
到了这一步,agent知道该做什么动作,但是还没真正的执行这个动作。
下一行把action输入env.Step()函数,这时候agent就真正做这个动作了,环境会更新状态State,给一个奖励reward,还有done和info这两个返回值。
done的意思是游戏到了这一步结束了没有。
如果游戏结束done就等于一,没结束的话done就等于0。
info这个返回值我们先不用管,如果游戏结束了就用break终止循环,如果没结束就开始下一轮循环。