1 所需的样本数量过大
深度强化学习一个严重的问题在于需要巨大的样本量。举个例子,玩Atari游戏
图 19.17 中纵轴是算法的分数与 人类分数的比值, 100% 表示达到人类玩家的水准。图中横轴是收集到的游戏帧数,即样本数量。Rainbow DQN 需要 1 千 8 百万帧才能达到人类玩 家水平,超过 1 亿帧还未收敛

再举几个例子。AlphaGo Zero 用了 2 千 9 百万局自我博弈,每一局约有 100 个状态和动作。
TD3 算法 在 MuJoCo 物理仿真环境中训练 Half-Cheetah、Ant、Hopper 等模拟机器人,虽然只有几个关节需要控制,但是在样本数量 100 万时尚未收敛。甚至 连 Pendulum、Reacher 这种只有一两个关节的最简单的控制问题,TD3 也需要超过 10 万 个样本。
现实世界中的问题远远比 Atari 、 MuJoCo 复杂,其状态空间、动作空间都远大于 Atari、MuJoCo.
强化学习所需的样本量太大,这会限制强化学习在现实中 的应用。
2 探索阶段代价太大
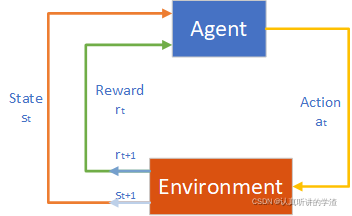
强化学习要求智能体与环境交互,用收集到的经验去更新策略。在交互的过程中,智能体会改变环境。在仿真、游戏的环境中,智能体对环境造成任何影响都无所谓。但是在现实世界中,智能体对环境的影响可能会造成巨大的代价。
在强化学习初始的探索阶段,策略几乎是随机的。如果是物理世界中的应用,智能体的动作难免造成很大的代价。如果应用到推荐系统中,如果上线一个随机的推荐策略,那么用户的体验会极差,很低的点击率也会给网站造成收入的损失。如果应用到自动驾驶中,随机的控制策略会导致车辆撞毁。如果应用到医疗中,随机的治疗方案会致死致残。
- 在物理世界的应用中,不能直接让初始的随机策略与环境交互,而应该先对策略做预训练,再在真实环境中部署。
- 一种方法是事先准备一个数据集,用行为克隆等监督学习方法做预训练。
- 另一种方法是搭建模拟器,在模拟器中预训练策略。比如阿里巴巴提出的“虚拟淘宝”系统 是对真实用户的模仿,用这样的模拟器预训练推荐策略。
- 离线强化学习 (Offline RL) 是一个热门而又有价值的研究方向
- Offline reinforcement learning: tutorial, review, and perspectives on open problems.
3 超参数的影响非常大
深度强化学习对超参数的设置极其敏感,需要很小心调参才能找到好的超参数。超参数分两种:神经网络结构超参数、算法超参数。这两类超参数的设置都严重影响实验效果。换句话说,完全相同的方法,由不同的人实现,效果会有天壤之别。
3.1 结构超参数
神经网络结构超参数包括层的数量、宽度、激活函数,这些都对结果有很大影响。
拿激活函数来说,在监督学习中,在隐层中用不同的激活函数(比如 ReLU 、 Leaky ReLU)对结果影响很小,因此总是用 ReLU 就可以。
但是在深度强化学习中,隐层激活函数对结果的影响很大;有时 ReLU 远好于 Leaky ReLU ,而有时 Leaky ReLU 远 好于 ReLU [Deep reinforcement learning that matters ]。由于这种不一致性,我们在实践中不得不尝试不同的激活函数。
3.2 算法超参数
- 强化学习中的算法超参数很多,包括学习率、批大小 (Batch Size)、经验回放的参数、探索用的噪声。
- 学习率(即梯度算法的步长)对结果的影响非常大,必须要很仔细地调。DDPG、 TD3、A2C 等方法中不止有一个学习率。策略网络、价值网络、目标网络中都有各自的学习率。
- 如果用经验回放,那么还需要调几个超参数,比如回放数组的大小、经验回放的起始时间等。
- 回放数组的大小对结果有影响,过大或者过小的数组都不好。
- 经验回放的起始时间需要调,比如 Rainbow 在收集到 8 万条四元组的时候开始经验回放,而标准的 DQN 则最好是在收集到 20 万条之后开始经验回放
-
- 在探索阶段,DQN、DPG 等方法的动作中应当加入一定噪声。噪声的大小是需要调的超参数,它可以平衡探索 (Exploration) 和利用 (Exploitation)。
- 除了设置初始的噪声的幅度,我们还需要设置噪声的衰减率,让噪声逐渐变小。
4 实验效果严重依赖于实现的好坏
上面的讨论目的在于说明超参数对结果有重大影响。
对于相同的方法,不同的人会有不同的实现,比如用不同的网络结构、激活函数、训练算法、学习率、经验回放、噪声。哪怕是一些细微的区别,也会影响最终的效果。
论文 [ 48 ] 使用了几个比较有名的开源代码,它们都有 TRPO 和 DDPG 方法在 Half-Cheetah 环境中的实验。论文使用了它们的默认设置,比较了实验结果,如图 19.18 所示。

很显然, 相同的方法,不同人的编程实现,实验效果差距巨大。
5 实验对比的可靠性问题
如果一篇学术论文提出一种新的方法,往往要在 Atari 、 MuJoCo 等标准的实验环境中做实验,并与 DQN 、 DDPG 、 TD3 、 A2C 、 TRPO 等有名的基线做实验对照。通常只有当新的方法效果显著优于基线时,论文才有可能发表。
但是 论文实验中报告的结果真的可信吗?从图 19.18 中不难看出,基线算法的表现严重依赖于编程实现的好坏。如果你提出一种新的方法,你把自己的方法实现得非常好,而你从开源的实现中选一个不那么好的基线做实验对比,那么你可以轻松打败基线算法。
6 稳定性极差
强化学习训练的过程中充满了随机性。除了环境的随机性之外,随机性还来自于神经网络随机初始化、决策的随机性、经验回放的随机性。
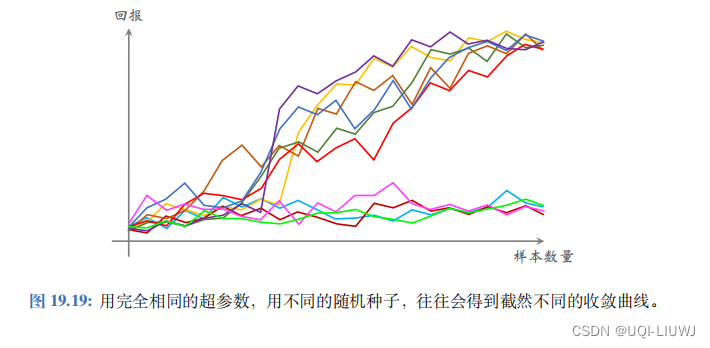
想必大家都有这样的经历:用完全相同的程序、完全相同的超参数,仅仅更改随机种子 (Random Seed) ,就会导致训练的效果有天壤之别。
如示意图 19.19 所示,如果重复训练十次,往往会有几次完全不收敛。哪怕是非常简单的问题,也会出现这种不收敛的情形。
在监督学习中,由于随机初始化和随机梯度中的随机性,即使用同样的超参数,训练出的模型表现也会不一致,测试准确率可能会差几个百分点。但是监督学习中几乎不 会出现图 19.19 中这种情形;如果出现了,几乎可以肯定代码中有错。
但是强化学习确实 会出现完全不收敛的情形,哪怕代码和超参数都是对的。