本文将介绍强化学习的基本含义,了解什么是强化学习、强化学习的概念与基本框架以及强化学习中常见的问题类型。
什么是强化学习?
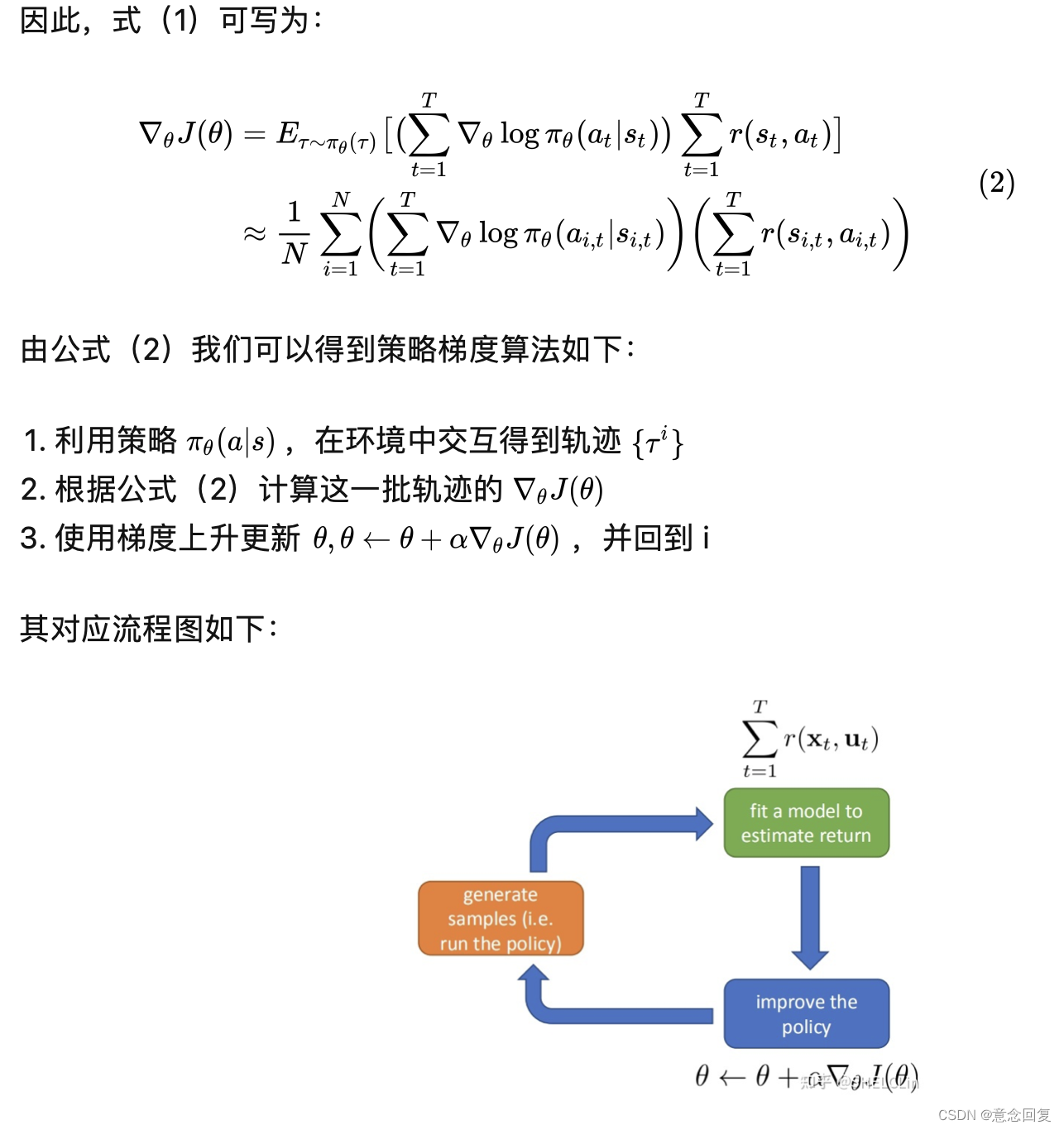
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
以上是百度百科中对强化学习的描述,从这样一句话中我们能捕捉到几点信息:
- 强化学习是一种机器学习方法
- 强化学习关注智能体与环境之间的交互
- 强化学习的目标一般是追求最大回报
换句话说,强化学习是一种学习如何从状态映射到行为以使得获取的奖励最大的学习机制。这样的一个agent需要不断地在环境中进行实验,通过环境给予的反馈(奖励)来不断优化状态-行为的对应关系。因此,反复实验(trial and error)和延迟奖励(delayed reward)是强化学习最重要的两个特征。
与其他机器学习方法的区别
这里其他机器学习方法主要是监督学习和无监督学习,也是我们在理解强化学习的过程中最容易发生混淆的地方。
监督学习是机器学习领域研究最多的方法,已经十分成熟,在监督学习的训练集中,每一个样本都含有一个标签,在理想情况下,这个标签通常指代正确的结果。监督学习的任务即是让系统在训练集上按照每个样本所对应的标签推断出应有的反馈机制,进而在未知标签的样本上能够计算出一个尽可能正确的结果,例如我们熟悉的分类与回归问题。在强化学习中的交互问题中却并不存在这样一个普适正确的“标签”,智能体只能从自身的经验中去学习。
但是强化学习与同样没有标签的无监督学习也不太一样,无监督学习是从无标签的数据集中发现隐藏的结构,典型的例子就是聚类问题。但是强化学习的目标是最大化奖励而非寻找隐藏的数据集结构,尽管用无监督学习的方法寻找数据内在结构可以对强化学习任务起到帮助,但并未从根本上解决最大化奖励的问题。
因此,强化学习是除了监督学习和无监督学习之外的第三种机器学习范式。

注:当然还有让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能的半监督学习,它与强化学习也有着本质的差别。
强化学习特点
基于前面的介绍,我们将强化学习的特点总结为以下四点:
- 没有监督者,只有一个奖励信号
- 反馈是延迟的而非即时
- 具有时间序列性质
- 智能体的行为会影响后续的数据
强化学习的要素与架构
四个基本要素
强化学习系统一般包括四个要素:策略(policy),奖励(reward),价值(value)以及环境或者说是模型(model)。接下来我们对这四个要素分别进行介绍。
策略(Policy)
策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。因此我们可以知道策略是强化学习系统的核心,因为我们完全可以通过策略来确定每个状态下的行为。我们将策略的特点总结为以下三点:
- 策略定义智能体的行为
- 它是从状态到行为的映射
- 策略本身可以是具体的映射也可以是随机的分布
奖励(Reward)
奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。我们将奖励的特点总结为以下三点:
- 奖励是一个标量的反馈信号
- 它能表征在某一步智能体的表现如何
- 智能体的任务就是使得一个时段内积累的总奖励值最大
价值(Value)
接下来说说价值,或者说价值函数,这是强化学习中非常重要的概念,与奖励的即时性不同,价值函数是对长期收益的衡量。我们常常会说“既要脚踏实地,也要仰望星空”,对价值函数的评估就是“仰望星空”,从一个长期的角度来评判当前行为的收益,而不仅仅盯着眼前的奖励。结合强化学习的目的,我们能很明确地体会到价值函数的重要性,事实上在很长的一段时间内,强化学习的研究就是集中在对价值的估计。我们将价值函数的特点总结为以下三点:
- 价值函数是对未来奖励的预测
- 它可以评估状态的好坏
- 价值函数的计算需要对状态之间的转移进行分析
环境(模型)
最后说说外界环境,也就是模型(Model),它是对环境的模拟,举个例子来理解,当给出了状态与行为后,有了模型我们就可以预测接下来的状态和对应的奖励。但我们要注意的一点是并非所有的强化学习系统都需要有一个模型,因此会有基于模型(Model-based)、不基于模型(Model-free)两种不同的方法,不基于模型的方法主要是通过对策略和价值函数分析进行学习。我们将模型的特点总结为以下两点:
- 模型可以预测环境下一步的表现
- 表现具体可由预测的状态和奖励来反映
强化学习的架构

我们用这样一幅图来理解一下强化学习的整体架构,大脑指代智能体agent,地球指代环境environment,从当前的状态 S t a S^a_t Sta出发,在做出一个行为 A t A_t At之后,对环境产生了一些影响,它首先给agent反馈了一个奖励信号 R t R_t Rt,接下来我们的agent可以从中发现一些信息,此处用 O t O_t Ot表示,进而进入一个新的状态,再做出新的行为,形成一个循环。强化学习的基本流程就是遵循这样一个架构。
强化学习的问题
强化学习的基本问题按照两种原则进行分类。
- 基于策略和价值的分类,分为三类:
- 基于价值的方法(Value Based):没有策略但是有价值函数
- 基于策略的方法(Policy Based):有策略但是没有价值函数
- 参与评价方法(Actor Critic):既有策略也有价值函数
- 基于环境的分类,分为两类:
- 无模型的方法(Model Free):有策略和价值函数,没有模型
- 基于模型的方法(Model Based):有策略和价值函数,也有模型
我们用下面的韦恩图来清晰地对这些方法做一个展示:

探索(Exploration)和利用(Exploitation)
最后在强化学习的问题这里谈一下探索和利用的问题。强化学习理论受到行为主义心理学启发,侧重在线学习并试图在探索-利用(exploration-exploitation)间保持平衡,不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。
一方面,为了从环境中获取尽可能多的知识,我们要让agent进行探索,另一方面,为了获得较大的奖励,我们要让agent对已知的信息加以利用。鱼与熊掌不可兼得,我们不可能同时把探索和利用都做到最优,因此,强化学习问题中存在的一个重要挑战即是如何权衡探索-利用之间的关系。
总结
强化学习是一种理解和自动化目标导向学习和决策的计算方法,它强调个体通过与环境的直接交互来学习,而不需要监督或是完整的环境模型。
可以认为,强化学习是第一个有效解决从与环境交互中学习以实现长期目标的方法,而这种模式是所有形式的机器学习中最接近人类和其他动物学习的方法,也是目前最符合人工智能发展终极目标的方法。
这是本人写的第一篇博客,文中错谬之处在所难免,若蒙读者诸君不吝告知,将不胜感激。
之后还会继续分享强化学习的基础知识以及其他有价值的内容。
转载或者引用本文内容请注明来源及原作者