本博客地址:https://security.blog.csdn.net/article/details/123710121
一、联邦强化学习介绍
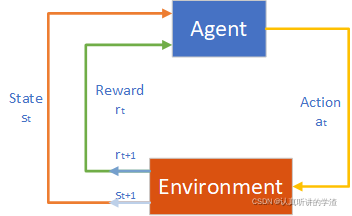
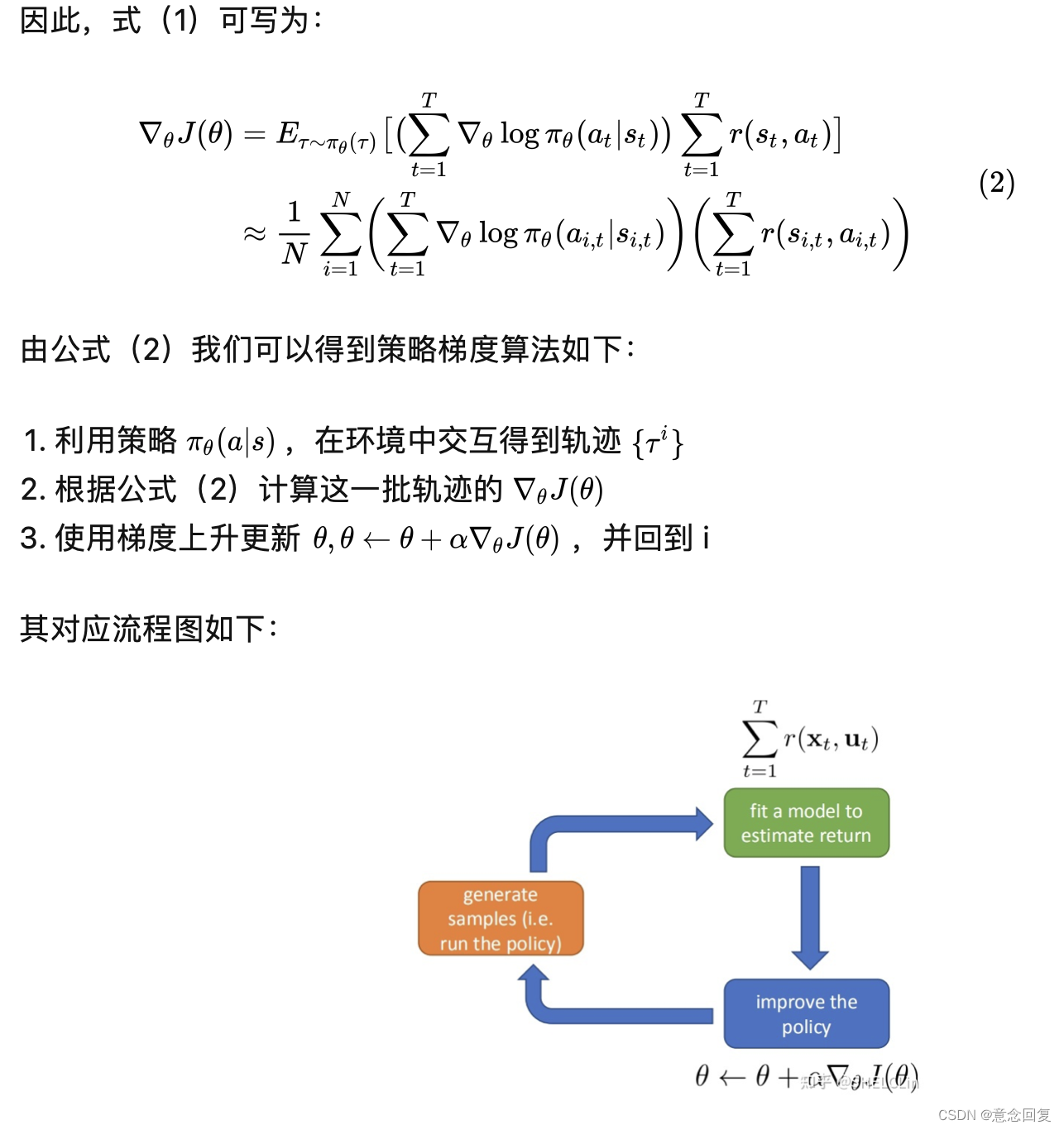
强化学习(RL)是机器学习的一个分支,主要研究序列决策问题,强化学习系统通常由一个动态环境和与环境进行交互的一个或多个智能体(agent)组成。智能体根据当前环境条件选择动作决策,环境在智能体决策的影响下发生相应改变,智能体可以根据自身的决策以及环境的改变过程得出奖励。
对于智能体的周期,智能体首先会观察环境的状态,然后基于这个状态选择动作,同时智能体期望根据所选的动作从环境中得到奖励,智能体的奖励与其上一步的状态、下一步状态和所做出的决策等因素有关。因此,智能体会在【状态-动作-奖励-状态-动作】周期(SARSA)中循环移动。
除了智能体和环境,强化学习系统还包括四个关键子元素:
● 策略。策略定义了智能体在给定状态时选择动作的方式。
● 奖励。奖励定义了在强化学习问题中,环境到智能体的即时反馈。
● 价值函数。价值函数是一种在给定状态下测量动作的长期回报奖励的方法。
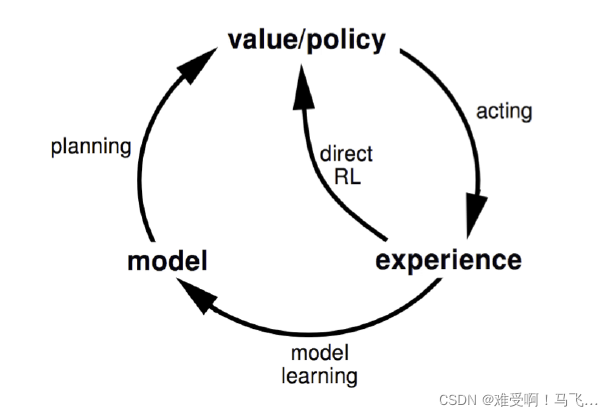
● 环境模型。环境模型是一种模拟环境动作的虚拟模型。
二、强化学习算法
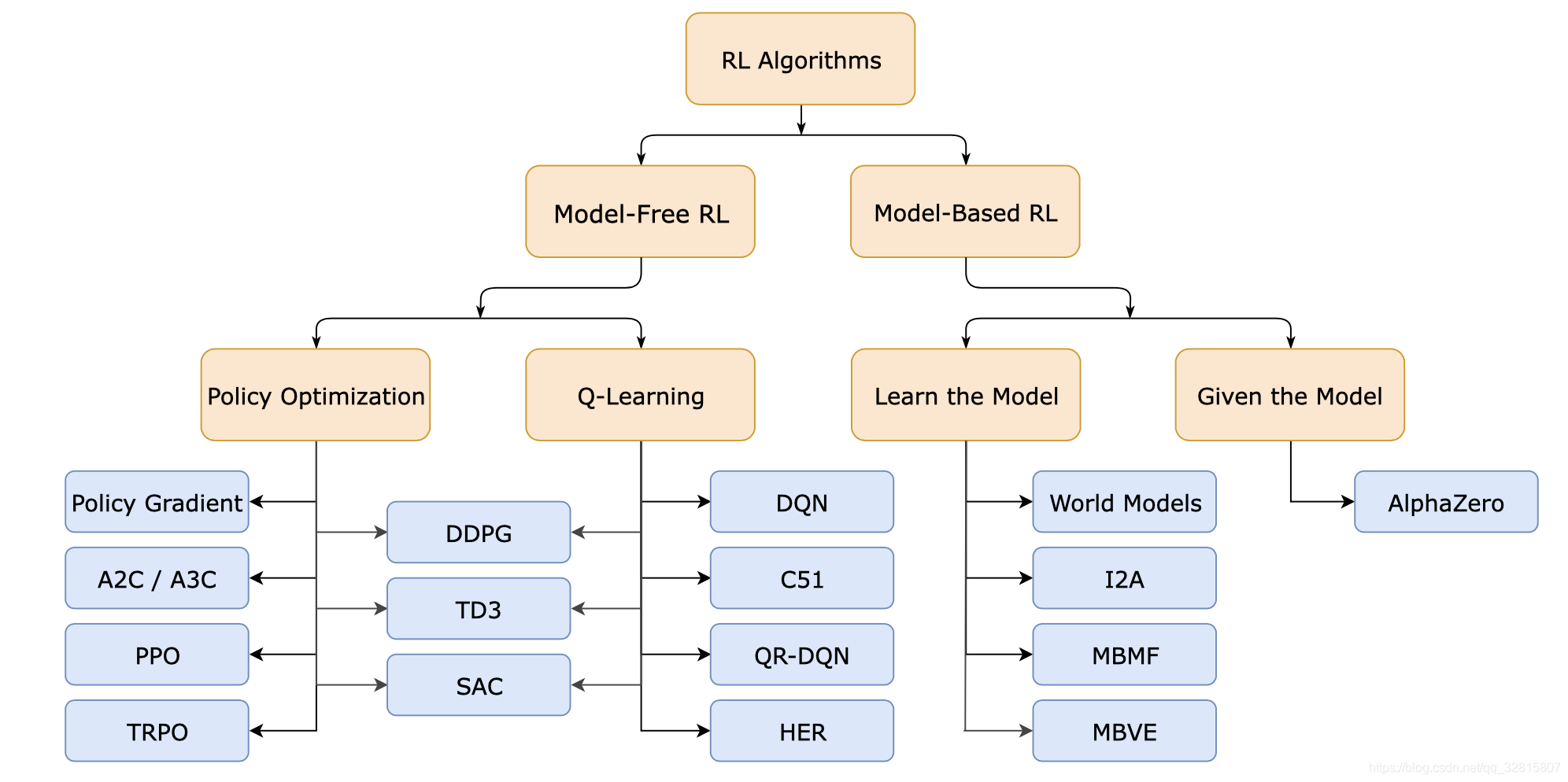
强化学习算法的分类:
1、基于模型与无模型
基于模型的方法首先尝试建立环境的虚拟模型,然后根据虚拟模型得出的最佳策略进行操作。无模型方法假设环境模型不能被建立,并通过反复迭代来修正价值函数和智能体策略。
2、基于价值与基于策略
基于价值的方法试图学习价值函数,并从中得到最优策略。基于策略的方法直接从策略参数中进行搜索,寻找最优策略。
3、蒙特卡洛更新与时间差分更新
蒙特卡洛更新通过使用整个周期内的积累奖励来评估策略,它需要大量的迭代次数才能收敛。时间差分更新计算的是误差,即价值函数的新估计值和旧估计值的差值,它减小了方差,但同时由于过程的全局视图没有被考虑到,可能会导致偏差增大。
4、在策略与离策略
在策略的方法使用当前策略来生成动作并以此更新当前策略。离策略的方法使用一个不同的探索性策略来生成动作,目标策略将基于这些动作来更新。
下表总结了常见的强化学习算法及分类:
| 算法 | 无模型 | 基于模型 | 基于策略 | 基于价值 | 蒙特卡洛更新 | 时间差分更新 | 离策略 | 在策略 |
|---|---|---|---|---|---|---|---|---|
| Q-Learning | √ | √ | √ | √ | √ | |||
| SARSA | √ | √ | √ | √ | √ | |||
| 策略梯度 | √ | √ | √ | √ | ||||
| Actor-critic | √ | √ | ||||||
| 蒙特卡洛学习 | √ | |||||||
| SARSA匿名函数 | √ | |||||||
| 深度Q-网络 | √ |
三、分布式强化学习
1、异步优势动作评价算法(A3C)
在异步场景中,多个智能体分别探索它们自己的环境,并异步地更新一组全局参数。但由于一些智能体的延迟,可能会遇到梯度陈旧问题。
通用强化学习架构(Gorila)是一种用于大规模分布式强化学习的异步框架,它可以创建多个智能体,且将它们备份为包括参与者和学习者在内的不同角色。参与者只能通过环境中的行动来生成经验,收集的经验存储于一个共享的回访内存中,学习者只能通过从回访内存中取样来进行训练。
2、同步分布式强化学习
Sync-Opt同步随机优化:主要用来解决同步强化学习中存在的智能体速度缓慢、分布散乱的问题。
优势动作评价算法(A2C):除以异步优势动作评价算法工作外,它还会在轮次间对所有的智能体进行同步。
四、横向联邦强化学习(HFRL)
4.1、横向联邦强化学习框架
横向联邦强化学习主要用来应对隐私保护问题,其应用了并行强化学习应用的基础设置,并将隐私保护任务作为一项额外约束(同时对于联邦服务器和智能体)。
横向联邦强化学习的基本框架:

执行横向联邦强化学习的基本步骤如下:
● 步骤一:
所有RL智能体在本地独立训练各自的强化学习模型,且不会交换任何数据经验、参数梯度及损失。
● 步骤二:
RL智能体将加密过的模型参数发送给服务器。
● 步骤三:
联邦服务器对来自非同一的RL智能体的模型进行加密和融合,从而得到一个联邦模型。
● 步骤四:
联邦服务器将联邦模型发送给各RL智能体。
● 步骤五:
RL智能体更新本地模型。
4.2、终生联邦强化学习
自主导航设定下的终生联邦强化学习(LFRL),它的主要任务是使得机器人共享各自的经验,从而让它们可以高效地利用前驱知识快速适应环境中产生的新变化。LFRL算法的步骤如下:
● 步骤一:
独立学习。每一个机器人在各自的环境中执行各自的导航任务,环境可以是不同的、相关的或不相关的。另外它是在本地执行终生学习,以学习避免多种类型的障碍。
● 步骤二:
知识融合。机器人从已定义或未定义的环境中抽取相应的知识和技能,之后会通过知识融合过程,将已学到的知识融合成最终的模型。
● 步骤三:
智能体网络更新。各智能体的网络参数将会定期更新,由不同智能体获得的知识可以通过这些参数来进行共享。
4.3、横向联邦强化算法在实践中的价值
横向联邦强化算法在实践中可以带来很多有益的地方,例如:
● 避免非独立同分布样本。HFRL可以为建立一个更精确、更稳定的强化学习系统提供增益。
● 提高样本效率。HFRL可以对不同智能体从非同一环境抽取出的知识进行集中聚合,从而缓解低样本效率问题。
● 加速学习进程。通过与联邦学习框架相结合,从更多非同一分布样本中的学习到的经验可以加速强化学习的进程。
五、纵向联邦强化学习(VFRL)
5.1、纵向联邦强化学习框架
在纵向联邦强化学习中,有不同的RL智能体维持对同一环境的不同一观察,每一个RL智能体维护一个对应的动作策略。协作框架的主要目的是通过利用从不同的协作智能体拥有不同的观察结果中提取的混合知识,训练一个更有效的RL智能体。在训练或推理过程中,任何对原始数据的传递都是被禁止的。下
VFRL框架-联邦DQN:

我们把从环境获得奖励的RL智能体命名为Q-网络智能体(上图中的智能体A),其他智能体命名为协作RL智能体。
● 步骤一:
所有的RL智能体根据当前环境的观察结果和抽取的知识进行动作决策,这其中可能有智能体不进行动作,只维持各自对于环境的观察。
● 步骤二:
RL智能体得到环境对应的反馈结果,包括当前环境的观察和奖励等。
● 步骤三:
RL智能体通过将得到的观察内容放入自己的神经网络中以计算中间结果,之后将加密过的中间结果发送给Q-网络智能体。
● 步骤四:
Q-网络智能体对所有的中间结果进行解密,并使用当前的损失通过反向传输方法训练Q-网络。
● 步骤五:
Q-网络智能体将加密过的权重梯度发送给各个协作智能体。
● 步骤六:
每一个协作智能体对梯度进行解密并更新各自的网络模型。
5.2、纵向联邦强化学习的优势
与多智能体强化学习相比,VFRL的优点可以总结为:避免智能体和用户的信息泄露,同时提高强化学习性能。