理论概述
多任务深度强化学习,英文Multi-Task Deep Reinforcement Learning ,简称MTDRL或MTRL。于MARL不同,它可以是单智能体多任务的情况,也可以是多智能体多任务的情况。
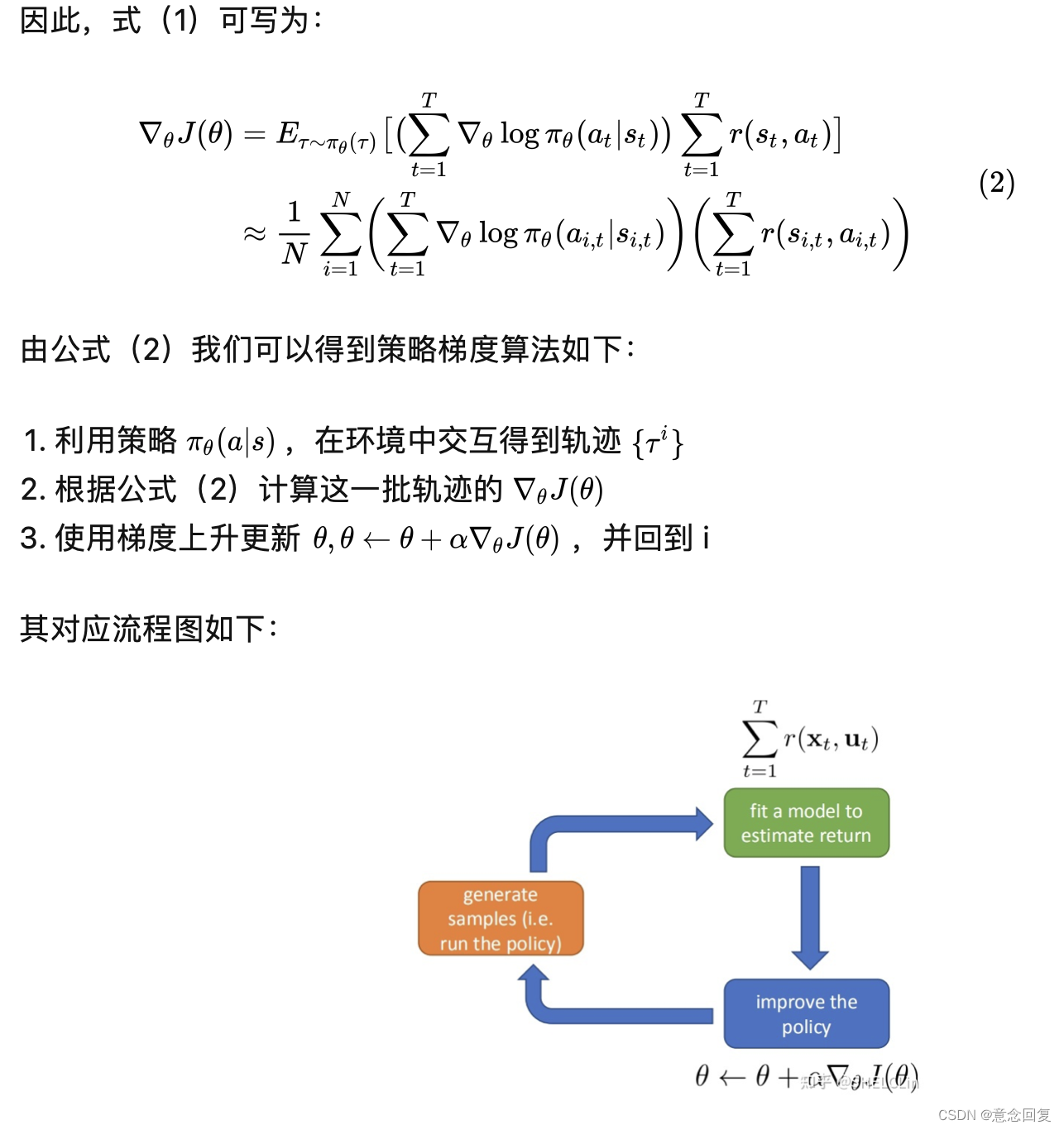
现在的深度强化学习领域虽然在很多特定任务上有着超越人类的表现,然而这些算法的共同特点是,一次只能训练一个任务,如果想要适应一个新任务,就需要训练一个全新的智能体,也就是说,每个智能体只能解决它被训练的一个任务。
在未来,我们的目标不仅仅是停留在构建多个分别擅长不同任务的简单智能体,而是要构建单个通用的智能体来同时学习并完成多个任务。,MTRL研究的就是让一个智能体同时掌握不止一个顺序决策任务。目前这一问题还没有统一的理论指导,以DeepMind、OpenAI为首的众多知名机构都在试图突破这些瓶颈。
从严格的学科定义来说,多任务学习的定义是:基于共享表示,把多个相关的任务放在一起学习的一种机器学习范式。这里明确两个概念,即共享表示和相关。
共享表示就是将不同任务的一部分信息联系在一起,目的是同时提高多个任务各自的泛化能力。方法有很多,对于传统的表示学习方法来说,我们可以讲不通任务的特征进行联合,穿件一个常见的特征集合进行学习,也就是基于约束的共享。对于DL来说,共享表示可以基于神经网络,将网络间的参数或一些卷积的操作进行共享,这就是基于参数的共享。
我们可以从多任务学习的预期定义相关。即任务A在多任务学习中与任务B、C共同学习的效果,一定会好于在单任务中单独训练A。也就是说,希望相关任务可以提升主任务的效果,这种任务就是我们需要在多任务学习模型中作为输入的一组相关任务。而经过模型分析后所得到的不同人物之间能相互促进的程度,也就是相关度。对于不同的多任务学习算法来说,相关度的结果是不一样的。

对于把多个相关的任务放在一起可以提高学习效果,学术界的解释是:
- 相关多个任务放在一起学习,有相关的部分,也有不相关的部分,当学习一个任务是,与该任务不相关的部分在学习的过程中相当于噪声。因此,引入噪声可以提高学习的泛化效果。
- 单任务学习时,梯度的反向传播倾向于陷入局部最小值。多任务学习中不同任务的局部最小值处于不同的位置,通过相互作用,可以帮组隐藏层跳出局部最小值。
- 添加的新任务可以改变权值更新的动态特性,可能网络更适合多任务学习。比如多任务并行学习提升了浅层共享层的学习速率从而提升了学习率和学习效果。事实上,目前DeepMind仍在沿用的IMPALA方法也正是一种基于多任务的分布式模型,它有非常好的效果。
- 多个任务之间的参数共享,可能削弱了网络对于单一任务的学习能力,降低了网络的过拟合,提升了泛化效果。
下面介绍DRL执行多任务学习中最常用的两种方法——硬参数共享和软参数共享。
硬参数共享是神经网络中最常用的多任务机制,通常通过在所有任务直接共享隐藏层来应用它,并同时保留多个特定任务的输出层。这可以大大降低过度拟合的风险,我们同时学习的任务越多,我们的模型就越能找到多个任务的特征,因此对单一任务过拟合的可能性就越小。

软参数共享是每一个任务都有自己的模型和自己的参数,然后对模型参数见的距离进行一定的归一化,增大参数之间的相关性,可以看出,这种共享约束受到了CNN、RNN中相应的归一化技术的启发。

面临的挑战
多任务学习比单任务学习困难得多,最大的难点在于,要在多个任务的需求之间找到平衡,而这些任务又同时竞争单个学习系统十分有限的资源。多任务学习的智能体很容易将注意力集中在奖励更高的任务上,因此通常训练出来的模型更偏向于奖励密集,奖励更高的任务,而忽略了稀疏奖励的任务。
策略蒸馏法(Policy Distillation)
"蒸馏"的概念最初由Bucila等人在2006年提出,被认为是一种有效监督学习模型的压缩方法,后来被扩展到从一个集成模型(ensemble model)创建单个网络的问题。它还显示了作为一种优化方法的优点,可可以从大型数据集或动态领域中稳定地学习。它通常使用一个不太复杂的目标分布,使用监督回归的方法训练一个目标网络,从而产生于原始网络相同的输出分布。
蒸馏是一种将知识从教师模型T转移到学术模型S的方法,下面是从单任务到多任务的蒸馏过程讲解。

教师的DQN的输出通过一个softmax函数,传递给未经过训练的学生模型,这里定义一个超参数τ,表示策略传递给学生知识的一种知识温度(temperature)。教师模型T的最终输出可以表示为 s o f t m a x ( q T τ ) softmax(\frac{q^T}{\tau}) softmax(τqT),这可以被学生网络有效通过回归方法学习。
但转移一个Q函数而不是分类器的情况下,预测所有动作的Q值是一个困难的回归任务。首先,Q值的大小可能难以确定,因为它是无界的,并且可能相当不稳定。另外可能出现多个动作具有相似的Q值,使得无法训练学生网络S预测唯一最佳动作。为了解决这样的问题,这里有三种策略蒸馏的损失函数。假设教师T网络已经生成了一个数据集 $D^T = ${ $ (s_i,q_i) KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲^N_{i=0}$ 。其中每一次采样都包含一个状态序列 s i s_i si和一个代表非归一化后的Q值的向量 q i q_i qi,每一个动作都有一个Q值。
第一种损失函数:
L N L L ( D T , θ S ) = − ∑ i = 1 ∣ D ∣ log P ( a i = a i , b e s t ∣ x i , θ S ) L_{NLL}(D^T,\theta_S) = - \sum_{i=1}^{|D|} \log P(a_i = a_{i,best}|x_i,\theta_S) LNLL(DT,θS)=−i=1∑∣D∣logP(ai=ai,best∣xi,θS)
第二种损失函数:
L N L L ( D T , θ S ) = ∑ i = 1 ∣ D ∣ ∣ ∣ q i T − q i S ∣ ∣ 2 2 L_{NLL}(D^T,\theta_S) = \sum_{i=1}^{|D|} ||q_i^T- q_i^S||_2^2 LNLL(DT,θS)=i=1∑∣D∣∣∣qiT−qiS∣∣22
第三种损失函数:
L N L L ( D T , θ S ) = ∑ i = 1 ∣ D ∣ s o f t m a x ( q i T τ ) ln s o f t m a x ( q i T τ ) s o f t m a x ( q i S ) L_{NLL}(D^T,\theta_S) = \sum_{i=1}^{|D|} softmax(\frac{q_i^T}{\tau}) \ln \frac{softmax(\frac{q_i^T}{\tau})}{softmax({q_i^S})} LNLL(DT,θS)=i=1∑∣D∣softmax(τqiT)lnsoftmax(qiS)softmax(τqiT)
在策略蒸馏的情况下,教师模型的输出可以不是一个分布,而是每一个可能的行动所带来的未来折扣奖励。我们可能需要提高每一个更优动作的概率强度,也就是尖锐化,而不是将它们的概率分布平缓化。
下面介绍多任务的策略蒸馏方法:

其核心代码基本就是DQN,只不过是通过一些框架上的改变实现了多任务的思路。每一个DQN网络对应一个不同的游戏,并且单独训练。数据存储在各自单独的经验复用池中,蒸馏损失函数模块一次从这N个数据存储单元中学习,计算损失函数后更新唯一的学生网络。每个任务都有一个单独的输出层,在训练和评估期间,需要时刻标记任务的id,用于切换到正确的输出。
不同的教师T将知识以此传递给学生S,之后无论从这n个数据存储区中取出怎么样的状态空间集合,学生策略网络都会有一个正常的输出,而学生的输出与教师的输出对应初始化之后每一次的更新都是必要的输入。这就形成了一个完整而有十分简单的多任务框架,也就是策略蒸馏框架。
策略蒸馏具有多个优点:网络规模可以压缩15倍而性能不降低,多个智能体策略可以组合成一个多任务策略,而性能还优于原来的智能体策略。最后,通过不断提取目标网络的最优策略,可以作为一个实时的在线学习过程,从而有效追踪不断演化的Q-learning策略。但策略蒸馏的框架过于简单,DQN提升的能力有限,后面陆续提出了各种各样的方法。
多任务深度强化学习算法
无监督强化与辅助学习(UNREAL)
英文名:Unsupervised Reinforcement and Auxiliary Learning
论文:Reinforcement Learning with Unsupervised Auxiliary Tasks
渐进式神经网络(Progressive Neural Network)
论文:Progressive Neural Networks
基于单智能体的任务共享模型
这个方法将蒸馏法和迁移学习结合在一起,诞生了Distral,即Distill&transfer learning。
论文:Teh, Yee, et al. “Distral: Robust multitask reinforcement learning.” Advances in Neural Information Processing Systems. 2017.
博文:【强化学习算法 32】Distral
提出了一种同时在多个任务上训练的强化学习方法,主要的想法是把各个任务上学到的策略进行提纯(distill,本意是蒸馏)得到一个共有的策略,然后再使用这个共有的策略去指导各个特定任务上的策略进行更好的学习。文章称,这种多任务的强化学习方法避免了不同任务产生互斥的梯度,反而干扰学习;同时,也避免了各个任务学习进度不一致,导致某个任务的学习主导了整体的学习。
使用PopArt归一化多任务更新幅度
PopArt是IMPALA上的重大改进。既可以获得像IMPALA这样大规模更新的好处,又能保持多任务问题庞大的网络参数中已经学习得非常不错的部分。命名为PopArt的原因也是:它在运行过程中既能精准地保持输出,又能自适应地重新缩放目标。
论文:Multi-task Deep Reinforcement Learning with PopArt