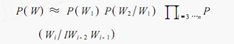文章目录
- 三种分词算法比较
- 逆向最大匹配
- 从后往前扫描
- 词典匹配
- 概率分词
- 原理
- DAG
- 计算大概率路径
- 封装
- 图论知识补充
- 图的表示方法
- 概率图模型
- 贝叶斯网络
三种分词算法比较
dt = {'空调': 1, '调和': 1, '和风': 1, '风扇': 1,'空': 1, '调': 1, '和': 2, '风': 1, '扇': 1} # 词典
max_len = max(len(w) for w in dt) # 词最大长度,默认等于词典最长词
total = sum(dt.values()) # 总频数
sentence = '空调和风扇'
length = len(sentence)def maximum_matching(sentence):"""正向最大匹配"""head = 0while head < length:tail = min(head + max_len, length)for middle in range(tail, head + 1, -1):word = sentence[head: middle]if word in dt:head = middlebreakelse:word = sentence[head]head += 1yield worddef reverse_maximum_matching(sentence):"""逆向最大匹配"""words = []tail = lengthwhile tail > 0:head = min(tail - max_len, 0)for middle in range(head, tail - 1):word = sentence[middle: tail]if word in dt:tail = middlebreakelse:tail -= 1word = sentence[tail]words.append(word) # 比words.insert(0, word)快6%return words[::-1]def probability(sentence):"""贝叶斯网络"""# get DAGDAG = dict()for head in range(length):DAG.update({head: [head]})tail = min(head + max_len, length)for middle in range(head + 2, tail + 1):word = sentence[head: middle]if word in dt:DAG[head].append(middle - 1)# calculate routeroute = {}route[length] = (1, 1)for idx in range(length - 1, -1, -1):route[idx] = max((dt.get(sentence[idx:x + 1], 0) / total * route[x + 1][0], x)for x in DAG[idx])# yieldx = 0while x < length:y = route[x][1] + 1l_word = sentence[x:y]yield l_wordx = yprint(list(maximum_matching(sentence)))
print(reverse_maximum_matching(sentence))
print(list(probability(sentence)))
- 空调和风扇分词结果
- [‘空调’, ‘和风’, ‘扇’]
[‘空’, ‘调和’, ‘风扇’]
[‘空调’, ‘和’, ‘风扇’]
逆向最大匹配
从后往前扫描
sentence = '西樵山'
# 初始化扫描位置,从句尾开始
tail = len(sentence)
# 词最大长度
max_len = 3
# 逆向扫描
while tail > 0:head = tail - max_lenif head < 0:head = 0for middle in range(head, tail):word = sentence[middle: tail]print(head, middle, tail, word)tail -= 1
0 0 3 西樵山
0 1 3 樵山
0 2 3 山
0 0 2 西樵
0 1 2 樵
0 0 1 西
词典匹配
dt = {'桂江二中', '毕业', '二中'} # 词典
sentence = '桂江二中毕业'tail = len(sentence)
max_len = 4
words = []
while tail > 0:head = max(tail - max_len, 0)for middle in range(head, tail - 1): # 忽略长度为1的词word = sentence[middle: tail]if word in dt:print(middle, tail - 1, word)words.append(word)tail = middlebreakelse:tail -= 1print(tail, tail, sentence[tail])words.append(sentence[tail])
print(words[::-1])
4 5 毕业
0 3 桂江二中
[‘桂江二中’, ‘毕业’]
概率分词
原理
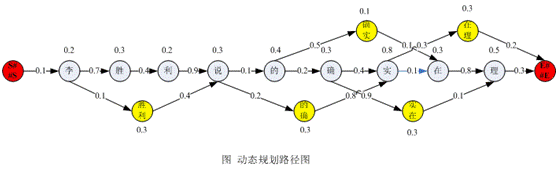
- 基于词典,对句子进行词图扫描,生成所有成词情况所构成的有向无环图(
Directed Acyclic Graph) - 根据DAG,反向计算最大概率路径(使用动态规划算法)
- 根据路径获取最大概率的分词序列
dt = {'空调': 1, '调和': 1, '和风': 1, '风扇': 1,'空': 1, '调': 1, '和': 2, '风': 1, '扇': 1} # 词典
max_len = max(len(w) for w in dt) # 词最大长度,默认等于词典最长词
total = sum(dt.values()) # 总频数
sentence = '空调和风扇'
length = len(sentence)
t o t a l = 1 + 1 + 1 + 1 + 1 + 1 + 2 + 1 + 1 = 10 total=1+1+1+1+1+1+2+1+1=10 total=1+1+1+1+1+1+2+1+1=10
P ( 空 调 , 和 风 , 扇 ) = 1 10 ∗ 1 10 ∗ 1 10 = 1 1000 P(空调,和风,扇)=\frac {1} {10} * \frac {1} {10} * \frac {1} {10} = \frac {1} {1000} P(空调,和风,扇)=101∗101∗101=10001
P ( 空 , 调 和 , 风 扇 ) = 1 10 ∗ 1 10 ∗ 1 10 = 1 1000 P(空,调和,风扇)=\frac {1} {10} * \frac {1} {10} * \frac {1} {10} = \frac {1} {1000} P(空,调和,风扇)=101∗101∗101=10001
P ( 空 调 , 和 , 风 扇 ) = 1 10 ∗ 2 10 ∗ 1 10 = 2 1000 P(空调,和,风扇)=\frac {1} {10} * \frac {2} {10} * \frac {1} {10} = \frac {2} {1000} P(空调,和,风扇)=101∗102∗101=10002
P ( 空 调 , 和 , 风 扇 ) 最 大 P(空调,和,风扇)最大 P(空调,和,风扇)最大
DAG
DAG = dict()
for head in range(length):DAG.update({head: [head]})tail = min(head + max_len, length)for middle in range(head + 2, tail + 1):word = sentence[head: middle]if word in dt:DAG[head].append(middle - 1)
print(DAG)
{0: [0, 1], 1: [1, 2], 2: [2, 3], 3: [3, 4], 4: [4]}
计算大概率路径
route = {}
route[length] = (1, 1)
for idx in range(length - 1, -1, -1):route[idx] = max((dt.get(sentence[idx:x + 1], 0) / total * route[x + 1][0], x)for x in DAG[idx])
print(route)
{5: (1, 1), 4: (0.1, 4), 3: (0.1, 4), 2: (0.02, 2), 1: (0.01, 2), 0: (0.002, 1)}
封装
from os import path
import re
import jieba
from math import log
fname = path.join(path.dirname(jieba.__file__), 'dict.txt')
NA = 'NA'class Tokenizer:re_eng = re.compile('[a-zA-Z]+')re_m = re.compile('[0-9]+') # jieba数词标注为mdef __init__(self, word2freq, total, word2flag, max_len):self.word2freq = word2freqself.total = totalself.word2flag = word2flagself.max_len = max_len@classmethoddef initialization(cls):word2freq, total, word2flag = dict(), 0, dict()with open(fname, encoding='utf-8') as f:for line in f.read().strip().split('\n'):word, freq, flag = line.split()freq = int(freq)word2freq[word] = freqtotal += freqword2flag[word] = flag# 词最大长度,默认等于词典最长词(超长英文符会识别不出来)max_len = max(len(i) for i in word2freq.keys())return cls(word2freq, total, word2flag, max_len)def _get_DAG(self, sentence):length = len(sentence)DAG = dict()for head in range(length):DAG.update({head: [head]})tail = min(head + self.max_len, length)for middle in range(head + 2, tail + 1):word = sentence[head: middle]# ------------- 词典 + 正则 ------------- #if word in self.word2freq:DAG[head].append(middle - 1)elif self.re_eng.fullmatch(word):DAG[head].append(middle - 1)elif self.re_m.fullmatch(word):DAG[head].append(middle - 1)return DAGdef _calculate(self, sentence):DAG = self._get_DAG(sentence)length = len(sentence)route = dict()route[length] = (0, 0)logtotal = log(self.total)for idx in range(length - 1, -1, -1):route[idx] = max((log(self.word2freq.get(sentence[idx:x + 1], 1)) - logtotal + route[x + 1][0], x)for x in DAG[idx])return routedef cut(self, sentence):route = self._calculate(sentence)length = len(sentence)x = 0while x < length:y = route[x][1] + 1l_word = sentence[x:y]yield l_wordx = ydef lcut(self, sentence):return list(self.cut(sentence))def add_word(self, word, freq=-1, flag=NA):if freq >= 0:self.del_word(word)else:freq = 1original_freq = self.word2freq.get(word, 0)self.word2freq[word] = original_freq + freqself.total = self.total - original_freq + self.word2freq[word]self.word2flag[word] = flagdef del_word(self, word):original_freq = self.word2freq.get(word)if original_freq is not None:del self.word2freq[word]self.total -= original_freqdel self.word2flag[word]def cut2position(self, sentence):route = self._calculate(sentence)x = 0length = len(sentence)while x < length:y = route[x][1] + 1l_word = sentence[x:y]yield l_word, x, yx = ydef get_flag(self, word):return self.word2flag.get(word, NA)def get_flags(self, words):if isinstance(words, str):words = self.cut(words)return [self.get_flag(word) for word in words]# 实例化
tokenizer = Tokenizer.initialization()
cut = tokenizer.cut
lcut = tokenizer.lcut
add_word = tokenizer.add_word
del_word = tokenizer.del_word
cut2position = tokenizer.cut2position
get_flag = tokenizer.get_flag
get_flags = tokenizer.get_flagsif __name__ == '__main__':text = '幻刺斩杀大法师'print(lcut(text))add_word('幻刺', 2, 'N')print(list(cut2position(text)))del_word('大法师')print(lcut(text))print(get_flags(text))
图论知识补充
图的表示方法

- networkx
%matplotlib inline
import networkx as nx
# 创建图
G = nx.DiGraph()
# 添加边
G.add_edges_from([(0, 1), (0, 2), (1, 2), (2, 3)])
# 绘图
nx.draw(G, with_labels=True, font_size=36, node_size=1500, width=4, node_color='lightgreen')
- 矩阵
class G:def __init__(self, nodes):self.matrix = [[0] * nodes for _ in range(nodes)]def add_edge(self, start, end, value=1):self.matrix[start][end] = valueg = G(4)
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 3)
print(g.matrix)
- 字典
class G:def __init__(self):self.dt = dict()def add_edge(self, start, end, value=1):self.dt[start] = self.dt.get(start, dict())self.dt[start][end] = valueg = G()
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 3)
print(g.dt)
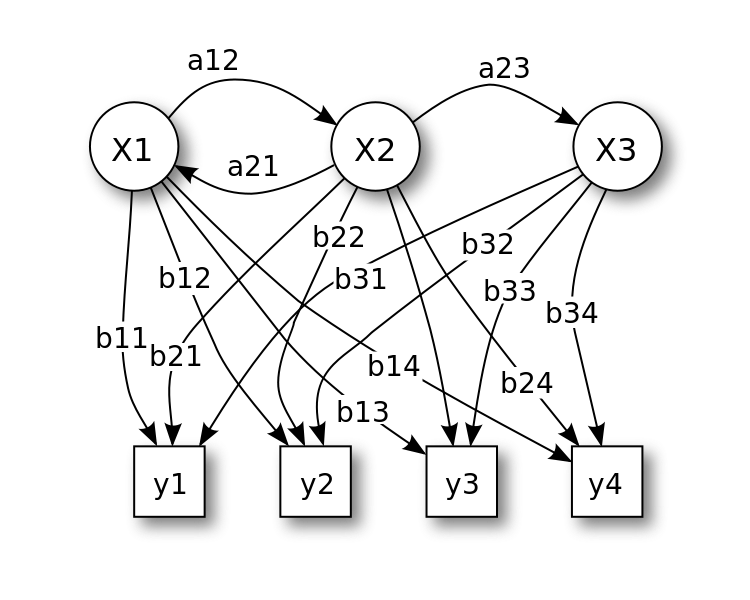
概率图模型
- 概率图模型:利用图来表示与模型有关的变量的联合概率分布
- 贝叶斯网络模型:由有向无环图和条件概率表(Conditional Probability Table,CPT)组成
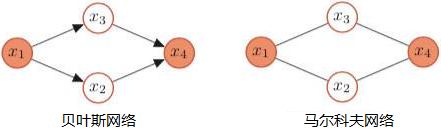
贝叶斯网络