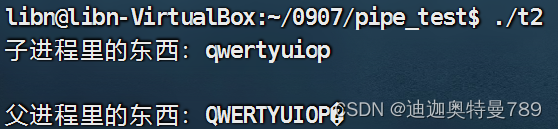
常见分词算法综述
文章目录
- 常见分词算法综述
- 一、基于词典的分词
- 1. 最大匹配分词算法
- 2. 最短路径分词算法:
- 2.1基于dijkstra算法求最短路径:
- 2.2N-dijkstra算法求最短路径:
- 2.3. 基于n-gram model的分词算法:
- 二、基于字的分词算法
- 生成式模型分词算法
- HMM分词-以jieba为例
- 判别式模型分词算法:
- 神经网络分词算法:
- 总结
分词算法根据其核心思想主要分为两种,
第一种是基于字典的分词,先把句子按照字典切分成词,再寻找词的最佳组合方式;
第二种是基于字的分词,即由字构词,先把句子分成一个个字,再将字组合成词,寻找最优的切分策略,同时也可以转化成序列标注问题。归根结底,上述两种方法都可以归结为在图或者概率图上寻找最短路径的问题。
一、基于词典的分词
1. 最大匹配分词算法
最大匹配分词寻找最优组合的方式是将匹配到的最长词组合在一起。主要的思路是先将词典构造成一棵Trie树,也称为字典树,如下图:
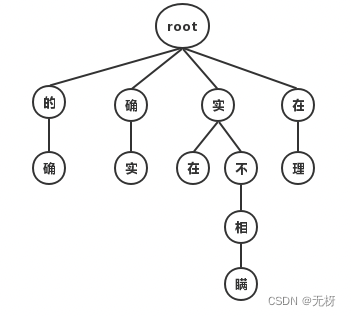
Trie树由词的公共前缀构成节点,降低了存储空间的同时提升查找效率。最大匹配分词将句子与Trie树进行匹配,在匹配到根结点时由下一个字重新开始进行查找。比如正向(从左至右)匹配“他说的确实在理”,得出的结果为“他/说/的确/实在/理”。如果进行反向最大匹配,则为“他/说/的/确实/在理”。
可见,词典分词虽然可以在O(n)时间对句子进行分词,但是效果很差,在实际情况中基本不使用此种方法。
2. 最短路径分词算法:
最短路径分词算法首先将一句话中的所有词匹配出来,构成词图(有向无环图DAG),之后寻找从起始点到终点的最短路径作为最佳组合方式
例如下图:

两点之间的最短路径也包含了路径上其他顶点间的最短路径。比如S->A->B->E为S到E到最短路径,那S->A->B一定是S到B到最短路径,否则会存在一点C使得d(S->C->B)<d(S->A->B),那S到E的最短路径也会变为S->C->B->E,这就与假设矛盾了。利用上述的最优子结构性质,可以利用贪心算法或动态规划两种求解算法:
2.1基于dijkstra算法求最短路径:
基于Dijkstra算法求解最短路径。该算法适用于所有带权有向图,求解源节点到其他所有节点的最短路径,并可以求得全局最优解。Dijkstra本质为贪心算法,在每一步走到当前路径最短的节点,递推地更新原节点到其他节点的距离。针对当前问题,Dijkstra算法的计算结果为:“他/说/的/确实/在理“。可见最短路径分词算法可以满足部分分词要求。但当存在多条距离相同的最短路径时,Dijkstra只保存一条,对其他路径不公平,也缺乏理论依据
2.2N-dijkstra算法求最短路径:
N-最短路径分词是对Dijkstra算法的扩展,在每一步保存最短的N条路径,并记录这些路径上当前节点的前驱,在最后求得最优解时回溯得到最短路径。该方法的准确率优于Dijkstra算法,但在时间和空间复杂度上都更大。
2.3. 基于n-gram model的分词算法:
语言模型的目的是构建一句话出现的概率p(s)

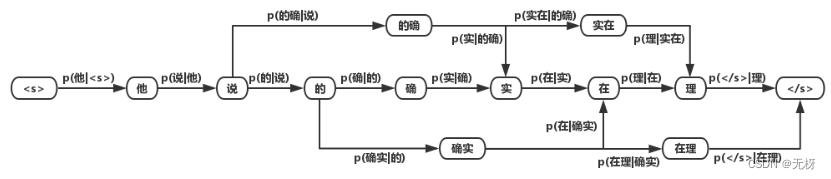
用算法求解最大概率的路径,即可得到分词结果
二、基于字的分词算法
与基于词典的分词不同的是,基于字的分词事先不对句子进行词的匹配,而是将分词看成序列标注问题,把一个字标记成B(Begin), I(Inside), O(Outside), E(End), S(Single)。因此也可以看成是每个字的分类问题,输入为每个字及其前后字所构成的特征,输出为分类标记。对于分类问题,可以用统计机器学习或神经网络的方法求解。
生成式模型分词算法
生成式模型主要有n-gram模型、HMM隐马尔可夫模型、朴素贝叶斯分类等。在分词中应用比较多的是n-gram模型和HMM模型。如果将2.1.3中的节点由词改成字,则可基于字的n-gram模型进行分词,不过这种方法的效果没有基于词的效果要好。
HMM模型认为在解决序列标注问题时存在两种序列,一种是观测序列,即人们显性观察到的句子,而序列标签是隐状态序列,即观测序列为X,隐状态序列是Y,因果关系为Y->X。因此要得到标注结果Y,必须对X的概率、Y的概率、P(X|Y)进行计算,即建立P(X,Y)的概率分布模型。
HMM分词-以jieba为例
中文分词可以转化为序列标注问题:
即可以对每个字转化为B,E,M,S四种状态,begin,end,mid,single
利用HMM模型进行分词,主要是将分词问题视为一个序列标注(sequence labeling)问题,其中,句子为观测序列,分词结果为状态序列。首先通过语料训练出HMM相关的模型,然后利用Viterbi算法进行求解,最终得到最优的状态序列,然后再根据状态序列,输出分词结果。
实例
序列标注,就是将输入句子和分词结果当作两个序列,句子为观测序列,分词结果为状态序列,当完成状态序列的标注,也就得到了分词结果。
以“去北京大学玩”为例,我们知道“去北京大学玩”的分词结果是“去 / 北京大学 / 玩”。对于分词状态,由于jieba分词中使用的是4-tag,因此我们以4-tag进行计算。4-tag,也就是每个字处在词语中的4种可能状态,B、M、E、S,分别表示Begin(这个字处于词的开始位置)、Middle(这个字处于词的中间位置)、End(这个字处于词的结束位置)、Single(这个字是单字成词)。具体如下图所示,“去”和“玩”都是单字成词,因此状态就是S,“北京大学”是多字组合成的词,因此“北”、“京”、“大”、“学”分别位于“北京大学”中的B、M、M、E。
因此对于HMM的五个因素我们可以分别对应如下:
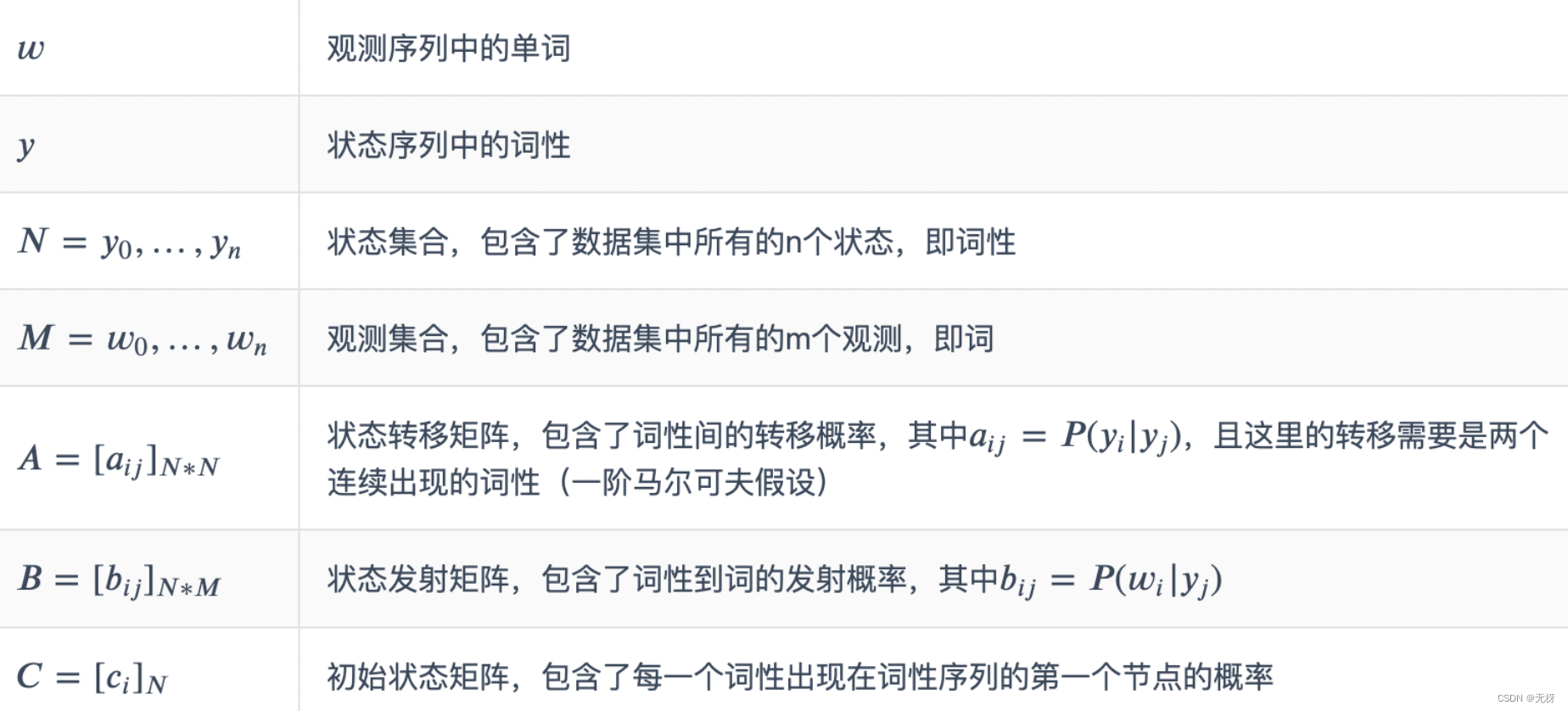
状态初始概率表示C,每个词初始状态的概率,可以看出M的几率为0,所以是负无穷
和实际相符合:开头的第一个字只可能是每个词的首字(B),或者单字成词(S)
jieba中的状态转移概率B,其实就是一个嵌套的词典,数值是概率值求对数后的值,如下所示

状态发射概率A 根据HMM模型中观测独立性假设,发射概率,即观测值只取决于当前状态值


在dag中使用维特比算法:

HMM模型是常用的分词模型,基于Python的jieba分词器和基于Java的HanLP分词器都使用了HMM。要注意的是,该模型创建的概率图与上文中的DAG图并不同,因为节点具有观测概率,所以不能再用上文中的算法求解,而应该使用Viterbi算法求解最大概率的路径。
判别式模型分词算法:
判别式模型主要有感知机、SVM支持向量机、CRF条件随机场、最大熵模型等。在分词中常用的有感知机模型和CRF模型:
- 平均感知机分词算法
感知机是一种简单的二分类线性模型,通过构造超平面,将特征空间(输入空间)中的样本分为正负两类。通过组合,感知机也可以处理多分类问题。但由于每次迭代都会更新模型的所有权重,被误分类的样本会造成很大影响,因此采用平均的方法,在处理完一部分样本后对更新的权重进行平均。
- CRF分词算法
CRF可以看作一个无向图模型,对于给定的标注序列Y和观测序列X,对条件概率P(Y|X)进行定义,而不是对联合概率建模。CRF可以说是目前最常用的分词、词性标注和实体识别算法,它对未登陆词有很好的识别能力,但开销较大。
神经网络分词算法:
序列标注任务,公认效果最好的模型是BiLSTM+CRF:
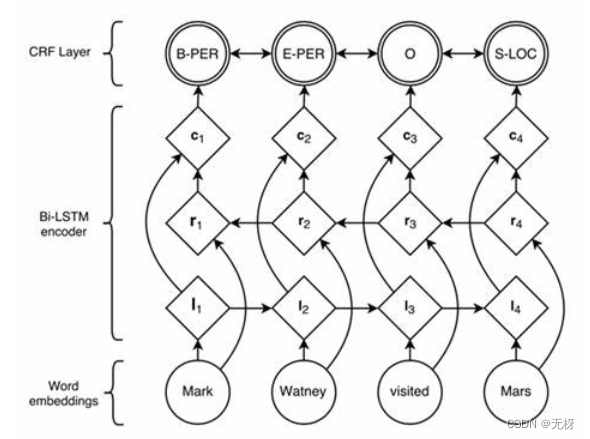
利用双向循环神经网络BiLSTM,相比于上述其它模型,可以更好的编码当前字等上下文信息,并在最终增加CRF层,核心是用Viterbi算法进行解码,以得到全局最优解,避免B,S,E这种标记结果的出现。
总结
分词算法的大概思路就是这样