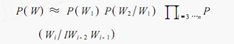导读:人类文明的重要标志之一是语言文字的诞生。数千年来,几乎人类所有知识的传播都是以语言和文字作为媒介。
自然语言处理是使用计算机科学与人工智能技术分析和理解人类语言的一门学科。在人工智能的诸多范畴中,自然语言的理解以其复杂性、多义性成为难度最大也是最有价值的领域之一。
随着机器学习、统计学、深度学习的飞速进步,自然语言处理方面的研究取得了许多突破性的进展。本文将以文本分析中最基本的分词操作为入口,介绍人工智能处理自然语言的基本工具和方法,为读者打开语言分析和认知的大门。
作者:朱晨光
来源:大数据DT(ID:hzdashuju)
00 文本分词
单词是语言中重要的基本元素。一个单词可以代表一个信息单元,有着指代名称、功能、动作、性质等作用。在语言的进化史中,不断有新的单词涌现,也有许多单词随着时代的变迁而边缘化直至消失。根据统计,《汉语词典》中包含的汉语单词数目在37万左右,《牛津英语词典》中的词汇约有17万。
理解单词对于分析语言结构和语义具有重要的作用。因此,在机器阅读理解算法中,模型通常需要首先对语句和文本进行单词分拆和解析。
分词(tokenization)的任务是将文本以单词为基本单元进行划分。由于许多词语存在词型的重叠,以及组合词的运用,解决歧义性是分词任务中的一个挑战。不同的分拆方式可能表示完全不同的语义。如在以下例子中,两种分拆方式代表的语义都有可能:
南京市|长江|大桥
南京|市长|江大桥
为了解决分词中的歧义性,许多相关算法被提出并在实践中取得了很好的效果。下面将对中文分词和英文分词进行介绍。
01 中文分词
在汉语中,句子是单词的组合。除标点符号外,单词之间并不存在分隔符。这就给中文分词带来了挑战。
分词的第一步是获得词汇表。由于许多中文词汇存在部分重叠现象,词汇表越大,分词歧义性出现的可能性就越大。因此,需要在词汇表的规模和最终分词的质量之间寻找平衡点。这里介绍一种主流的中文分词方式——基于匹配的分词。
这种分词方式采用固定的匹配规则对输入文本进行分割,使得每部分都是一个词表中的单词。正向最大匹配算法是其中一种常用算法,它的出发点是,文本中出现的词一般是可以匹配的最长候选词。
例如,对于文本“鞭炮声响彻夜空”,鞭炮和鞭炮声都是合理的单词,这里选择更长的鞭炮声,并最终分割成“鞭炮声|响彻|夜空”。
具体来说,正向最大匹配算法从第一个汉字开始,每次尝试匹配存在于词表中的最长的词,然后继续处理下一个词。这一过程无须每次在词表中查找单词,可以使用哈希表(hash table)或字母树(trie)进行高效匹配。
但是,正向最大匹配算法也经常会产生不符合逻辑的语句,如“为人民服务”,因为为人也是一个单词,所以算法会给出“为人|民|服务”的错误结果。
另一种改进的算法改变了匹配的顺序,即从后往前进行最大匹配。这种逆向最大匹配算法从文本末尾开始寻找在词表中最长的单词。读者可以发现,这种改进的算法能将“为人民服务”正确分词。统计结果表明,逆向最大匹配算法的错误率为1/245,低于正向最大匹配算法的错误率1/169。
下面给出逆向最大匹配算法的一个Python语言实现样例:
'''
逆向最大匹配算法
输入语句s和词表vocab,输出分词列表。
例子:
输入:s=‘今天天气真不错’,vocab=[‘天气’,‘今天’,‘昨天’,‘真’,‘不错’,‘真实’,‘天天’]
输出:[‘今天’,‘天气’,‘真’,‘不错’]
'''
def backward_maximal_matching(s, vocab):result = []end_pos = len(s)while end_pos > 0:found = Falsefor start_pos in range(end_pos):if s[start_pos:end_pos] in vocab:#找到最长匹配的单词,放在分词结果最前面result = [s[start_pos:end_pos]] + resultfound = Truebreakif found:end_pos = start_poselse:#未找到匹配的单词,将单字作为词分出result = [s[end_pos - 1]] + resultend_pos -= 1return result此外,中文分词还有基于统计的方法。
02 英文分词
相比于中文分词,英文分词的难度要小得多,因为英文的书写要求单词之间用空格分开。因此,最简单的方法就是去除所有标点符号之后,按空格将句子分成单词。但是,使用这种方法有以下弊端:
标点符号有时需要作为词的一部分保留。
例如:Ph.D.、http://www.stanford.edu;
英文中千分位的逗号表示。
例如:123,456.78;
英文中缩写需要展开。
例如:you're表示you are、we'll表示we will;
一些专有名词需要多个单词一起组成。
例如:New York、 San Francisco。
对于这些特例,可以使用正则表达式(regular expression)进行识别和特殊处理。此外,英文中很多词有常见变体,如动词的过去式加-ed,名词的复数加-s等。
为了使后续处理能识别同个单词的不同变体,一般要对分词结果提取词干(stemming),即提取出单词的基本形式。比如do、does、done这3个词统一转化成为词干do。提取词干可以利用规则处理,比如著名的Porter Stemmer就是采用一系列复杂的规则提取词干,如下所示。
Porter Stemmer提取词干示例:
sses→ss:classes→class
ies→i:ponies→poni
ative→ :informative→inform
在Python语言中,中文分词功能可以用jieba软件包实现:
# 安装Jieba
# pip install jieba
import jieba
seg_list = jieba.cut(‘我来到北京清华大学’)
print('/ '.join(seg_list))运行结果如下:
我/ 来到/ 北京/ 清华大学英文分词功能可以通过spaCy软件包完成:
# 安装spaCy
# pip install spacy
# python -m spacy download en_core_web_sm
import spacy
nlp = spacy.load('en_core_web_sm')
text = ('Today is very special. I just got my Ph.D. degree.')
doc = nlp(text)
print([e.text for e in doc])运行结果如下:
['Today', 'is', 'very', 'special', '.', 'I', 'just', 'got', 'my', 'Ph.D.', 'degree', '.']一般来说,中文分词的难度远大于英文分词。在英文阅读理解任务中,即使只采用最简单的空格分词也可以取得不错的效果。而在中文语言处理中,准确的分词模块是后续处理的关键。
03 字节对编码BPE
前文中提到的分词方法均依赖预先准备的词表。一方面,如果词表规模很大,分词效率将会下降;另一方面,无论词表大小,都难免文本中出现OOV(Out-of-Vocabulary,词表之外的词)。
例如,在许多阅读理解文章中会出现一些新的人名、地名、专有名词等。一种简单的处理办法是将这些OOV单词全部以特殊符号<OOV>代替,但是这会造成单词中重要信息的丢失,影响机器阅读理解算法的准确性。
在下面的案例中,人名Hongtao和网站名Weibo并不在词表中,如果用<OOV>来表示就完全失去了相关信息。而采用不依赖于词表的分词,可以最大程度保留原有的单词信息。
使用词表和不依赖于词表的分词:
原句:Hongtao is visiting Weibo website.
使用词表分词:<OOV> | is | visiting | <OOV> | website | .
不依赖于词表分词:Hong | #tao | is | visit | #ing | Wei | #bo | website | .
其中#表示该子词和前面的子词共同组成一个单词
字节对编码(Byte Pair Encoder,BPE)就是一种常用的不依赖于词表的分词方法。BPE的原理是,找到常见的可以组成单词的子字符串,又称子词(subword),然后将每个词用这些子词来表示。
最基本的子词就是所有字符的集合,如{a, b, …, z, A, B, …, Z}。之后,BPE算法在训练文本中统计所有相邻子词出现的次数,选出出现次数最多的一对子词。将这一对子词合并形成新的子词加入集合,这称为一次合并(merge)操作,而原来的两个子词仍保留在集合中。
在若干次合并之后,得到常见的子词集合。然后,对于一个新词,可以按照之前的合并顺序得到新词的BPE表示。而从BPE表示变回原词可以按照合并的反向顺序实现。以下是构造字符对编码的程序示例:
//训练文本
wonder ponder toner
//按照当前子词分
w o n d e r
p o n d e r
t o n e r统计相邻子词出现的次数,e r出现3次,出现次数最多。因此组成新子词er。
//按照当前子词分
w o n d er
p o n d er
t o n er统计相邻子词出现次数,o n出现3次,出现次数最多。因此组成新子词on:
//按照当前子词分
w on d er
p on d er
t on er统计相邻子词出现次数,on d出现2次,出现次数最多。因此组成新子词ond:
w ond er
p ond er
t on er合并3次后,子词集合为{a, b, …, z, er, on, ond}:
//解码新词fond
合并e r: f o n d
合并o n: f on d
合并on d:f ond使用字节对编码分词有以下优点。
第一,由于BPE的子词表里含有所有单个字符,所以任何单词都可以分拆成BPE的子词,即没有OOV问题。
第二,BPE可以通过调整合并次数动态控制词表大小。
因此,BPE常被运用在机器翻译、语言模型等诸多自然语言处理算法中。例如,著名的BERT算法就使用了BPE作为分词单元。但是,BPE也存在着一定的缺陷,例如在不同训练文本上可能得到不一样的子词表,使得对应的模型无法对接。此外,BPE生成的子词是完全基于频率的,可能并不符合语言中词根的划分。
在实际工程应用中,如果需要生成自然语言(如生成阅读理解问题的答案文本),一般推荐使用BPE等不依赖于词表的分词方法;如果任务不涉及文本生成(如在文章中划出答案),可以使用既有词表,例如GloVe或Word2vec等。
关于作者:朱晨光,微软公司自然语言处理高级研究员、斯坦福大学计算机系博士。负责自然语言处理研究与开发、对话机器人的语义理解、机器阅读理解研究等,精通人工智能、深度学习与自然语言处理,尤其擅长机器阅读理解、文本总结、对话处理等方向。
作者朱晨光跨越半个地球为正在阅读本文的你送上平安符????
本文摘编自《机器阅读理解:算法与实践》,经出版方授权发布。
延伸阅读《机器阅读理解》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:微软人工智能首席技术官黄学东、中国计算机学会秘书长杜子德联袂推荐!微软高级研究员、斯坦福大学计算机系博士、2届全球阅读理解竞赛冠军朱晨光撰写。让你深刻认识机器阅读理解并直接进行相关模型开发、实验和部署。
有话要说????
Q: 关于中文分词算法,你还有哪些思路?
欢迎留言与大家分享
猜你想看????
73页PPT,教你从0到1构建用户画像系统(附下载)
零基础入门量子计算:从一个神奇的概念进入量子世界
什么是云原生?有哪些发展方向?终于有人讲明白了
7本书,读懂未来5年最火的数据分析、智能芯片、量子计算、中台(文末有福利)
更多精彩????
在公众号对话框输入以下关键词
查看更多优质内容!
PPT | 读书 | 书单 | 硬核 | 干货
大数据 | 揭秘 | Python | 可视化
AI | 人工智能 | 5G | 中台
机器学习 | 深度学习 | 神经网络
合伙人 | 1024 | 大神 | 数学
据统计,99%的大咖都完成了这个神操作
????