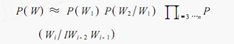中文分词工具讨论
1 中文分词原理介绍
1.1 中文分词概述
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
1.2 中文分词方法介绍
现有的分词方法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
1.2.1 基于字符串匹配的分词方法
基于字符串匹配的分词方法又称机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,字符串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,可以分为单纯分词方法和分词与词性标注相结合的一体化方法。常用的字符串匹配方法有如下几种:
(1)正向最大匹配法(从左到右的方向);
(2)逆向最大匹配法(从右到左的方向);
(3)最小切分(每一句中切出的词数最小);
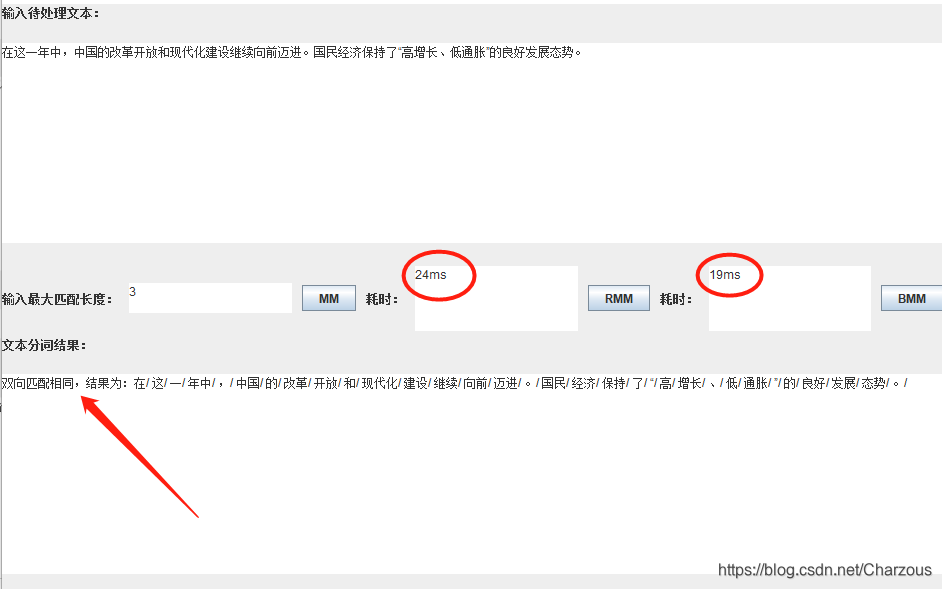
(4)双向最大匹配(进行从左到右、从右到左两次扫描)
这类算法的优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;但对歧义和未登录词处理效果不佳。
1.2.2 基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
1.2.3 基于统计的分词方法
基于统计的分词方法是在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。例如最大概率分词方法和最大熵分词方法等。随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法
主要的统计模型有:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
在实际的应用中,基于统计的分词系统都需要使用分词词典来进行字符串匹配分词,同时使用统计方法识别一些新词,即将字符串频率统计和字符串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
2 中文分词工具介绍
2.1 jieba分词
2.1.1 基本介绍
字如其名,结巴分词主要用于中文分词,很形象的画面想必一下子就出现在了用户的面前,结巴的人在说话时一个词一个词从嘴里往外蹦的时候,已经成功地模拟了我们jieba函数的处理过程。
Jieba库的分词原理是利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果。除了分词,用户还可以添加自定义的词组。
jieba分词主要有三种模式
-
精确模式:就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原为之前的文本。其中不存在冗余单词。
-
全模式:将一段文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,Jieba库会将各种不同的组合都挖掘出来。分词后的信息再组合起来会有冗余,不再是原来的文本。
-
搜索引擎模式:在精确模式基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余。
2.1.2 分词效果
-
全模式
import jieba str1 = '我来到了信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚。' seg_list = jieba.cut(str1, cut_all=True) # 使用全模式进行分词 生成列表 print('全模式分词结果:', '/'.join(seg_list)) # /拼接列表元素全模式分词结果: 我/来到/了/信息/信息工程/工程/大学/,/发现/这儿/真不/真不错/不错/,/环境/环境优美/优美/,/学习/氛围/浓厚/。 -
精确模式
import jieba str1 = '我来到了信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚。' seg_list = jieba.cut(str1, cut_all=False) # 使用精确模式进行分词 生成列表 print('全模式分词结果:', '/'.join(seg_list)) # /拼接列表元素精确模式分词结果: 我/来到/了/信息工程/大学/,/发现/这儿/真不错/,/环境优美/,/学习/氛围/浓厚/。 -
搜索引擎模式
import jieba str1 = '我来到了信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚。' seg_list = jieba.lcut_for_search(str1) # 使用搜索引擎模式进行分词 生成列表 print('搜索引擎模式分词结果:', '/'.join(seg_list)) # /拼接列表元素搜索引擎模式分词结果: 我/来到/了/信息/工程/信息工程/大学/,/发现/这儿/真不/不错/真不错/,/环境/优美/环境优美/,/学习/氛围/浓厚/。
2.1.3 总结
我们可以看到,精确模式就是我们平常所用,分词精准;搜索引擎模式,提供了更多分词可能,可以用于搜索引擎的词语匹配;而全模式则是分词的全部可能,最为全面,它把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率提供了更多分词可能,可以用于搜索引擎的词语匹配;;三种模式各具特点,针对不同的应用场景可以发挥不同的作用。
2.2 SnowNLP
2.2.1 基本介绍
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP。SnowNLP处理的是unicode编码,所以使用时需要自行decode成unicode。
2.2.2 分词效果
from snownlp import SnowNLP
#分词的对比
s=SnowNLP('我来到了信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚。')
#s.words返回一个列表,打印出来即可
print('snownlp分词结果:', '/'.join(s.words))#s.words返回一个列表,打印出来即可
#拼音真的牛
print('中文拼音:', '/'.join(s.pinyin))
#关键词tags
print('关键词:',list(s.tags))
snownlp分词结果: 我/来到/了/信息/工程/大学/,/发现/这儿/真/不错/,/环境/优美/,/学习/氛围/浓厚/。中文拼音: wo/lai/dao/liao/zhan/lve/zhi/yuan/bu/dui/xin/xi/gong/cheng/da/xue/,/fa/xian/zhe/er/zhen/bu/cuo/,/huan/jing/you/mei/,/xue/xi/fen/wei/nong/hou/。关键词: [('我', 'r'), ('来到', 'v'), ('了', 'u'), ('信息', 'n'), ('工程', 'n'), ('大学', 'n'), (',', 'w'), ('发现', 'v'), ('这儿', 'r'), ('真', 'd'), ('不错', 'a'), (',', 'w'), ('环境', 'n'), ('优美', 'a'), (',', 'w'), ('学习', 'v'), ('氛围', 'n'), ('浓厚', 'a'), ('。', 'w')]
2.2.3 总结
snownlp在分词效果上相对jieba来说感觉有些相差不多,效果也不错,但是速度稍微慢一些。但他具有的拼音和关键词功能比较厉害,对分好的词按照词性进行了标注。它最大特点是特别容易上手,用其处理中文文本时能够得到不少有意思的结果,但不少功能比较简单,还有待进一步完善。
2.3 hanlp
2.3.1 基本介绍
HanLP 是由一系列模型与算法组成的工具包,目标是普及自然语言处理在生产环境中的应用。HanLP 具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。HanLP 主要功能包括分词、词性标注、关键词提取、自动摘要、依存句法分析、命名实体识别、短语提取、拼音转换、简繁转换等等。不同于市面上的商业工具,HanLP提供训练模块,可以在用户的语料上训练模型并替换默认模型,以适应不同的领域。项目主页上提供了详细的文档,以及在一些开源语料上训练的模型。HanLP希望兼顾学术界的精准与工业界的效率,在两者之间取一个平衡,真正将自然语言处理普及到生产环境中去。
2.3.2
from pyhanlp import *
conten_list=HanLP.parseDependency("我来到了战略支援部队信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚。")
print('hanlp分析效果:',conten_list)
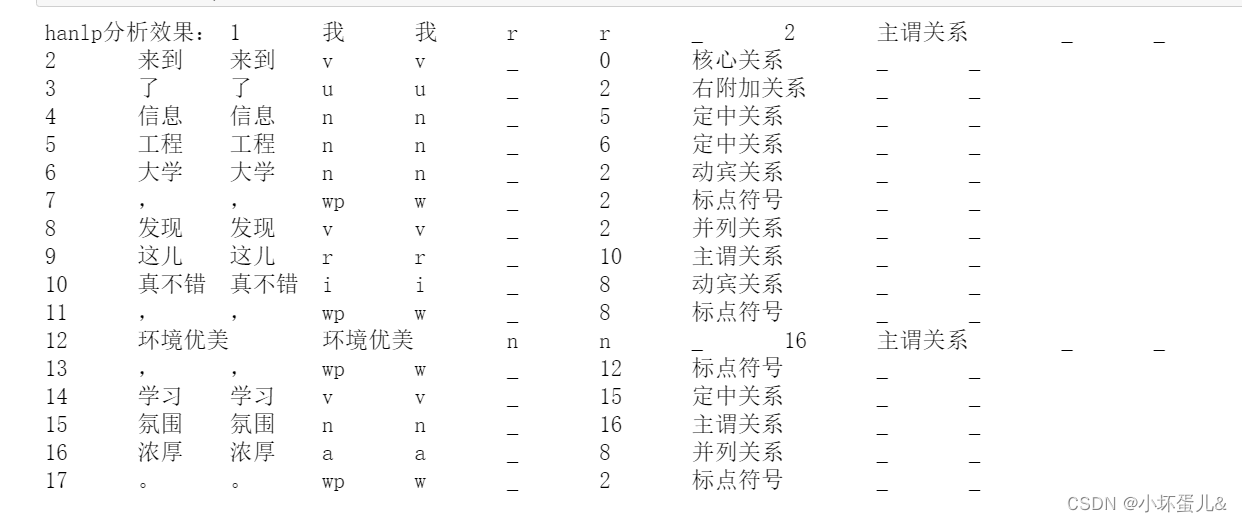
2.3.4 总结
hanlp分词效果也是不错,不仅分词,而且将各个词之间的关系,词性进行了描述。
2.4 ltp
2.4.1 基本介绍
TP 是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP 制定了基于 XML 的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块 (包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library, DLL)的应用程序接口,可视化工具,并且能够以网络服务(Web Service)的形式进行使用。pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
2.4.2 分词效果
from pyltp import Segmentor#导入Segmentor库
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/cws.model"#LTP分词模型库
segmentor = Segmentor()#实例化分词模块
segmentor.load(math_path)#加载分词库
words = segmentor.segment("我来到了信息工程大学,发现这儿真不错,环境优美,学习氛围浓厚")
print(' '.join(words).split())#分割分词后的结果
segmentor.release() # 释放模型
ltp分词效果:我/来到/了/信息/工程/大学/,/发现/这儿/真/不错/,/环境/优美/,/学习/氛围/浓厚
4 各个工具优缺点总结
4.1 jieba
-
优点:
自定义分词、词性方便
词典文件添加自定义词典比hanlp快,词典文件添加100w需要1m,八千万 2h多
-
缺点:
自定义词典时,带空格的词不支持
-
适用场景:
词典数量大于五千万
词典数据不能包含空格,否则分不出
4.2 snownlp
-
优点
容易上手
功能全面
-
缺点
处理速度慢
部分功能不够完善
4.3 hanlp
-
优点:
提供多种分词方式
可直接根据内部词库分出人名、机构等信息
可构造多个词库,在分词时可动态选择所要使用的词库
-
缺点:
自定义词典时,系统词典还是被优先使用,导致词性不是自定义词典中的词性
多单词英文姓名无法分出
4.4 ltp
-
优点
支持使用用户训练好的个性化模型
支持添加自定义词典
-
缺点
速度较慢