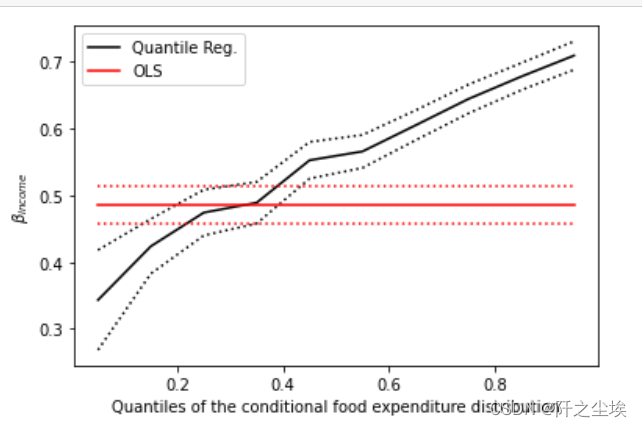
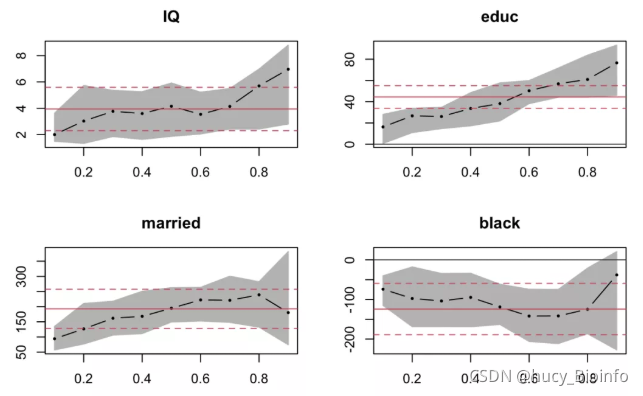
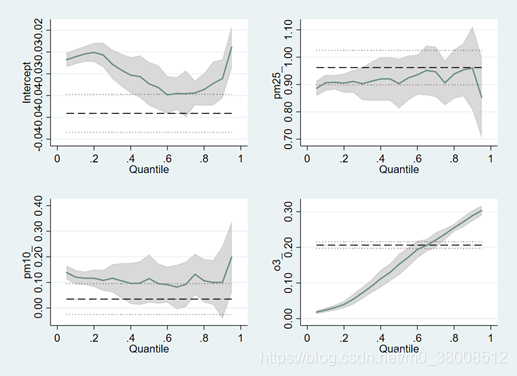
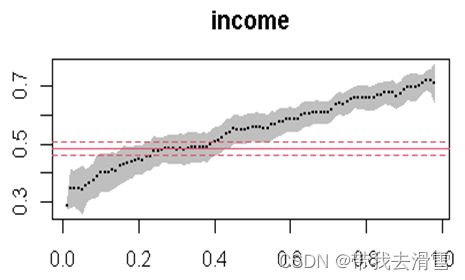
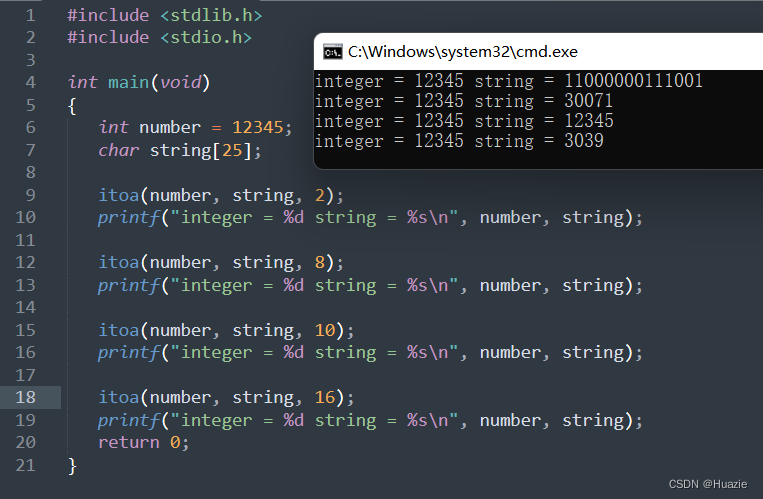
偶尔在机器学习的论文中了解到了分位数回归,发现这个方法应用也满广的。
文章目录
- 1. 分位数回归的数学原理
- 2. 分位数回归的求解原理
- 3 python 分位数回归
1. 分位数回归的数学原理
一般的回归方法是最小二乘法,即最小化误差的平方和:
min ∑ ( y i − y ^ i ) 2 \min\quad \sum(y_i-\hat{y}_i)^2 min∑(yi−y^i)2
其中, y i y_i yi 是真实值,而 y ^ i \hat{y}_i y^i 是预测值。而分位数的目标是最小化加权的误差绝对值和:
min y ^ i ∑ y i ≥ y ^ i τ ∣ y i − y ^ i ∣ + ∑ y i < y ^ i ( 1 − τ ) ∣ y i − y ^ i ∣ \min_{\hat{y}_i}\quad \sum_{y_i\geq \hat{y}_i} \tau|y_i-\hat{y}_i|+\sum_{y_i<\hat{y}_i}(1-\tau)|y_i-\hat{y}_i| y^iminyi≥y^i∑τ∣yi−y^i∣+yi<y^i∑(1−τ)∣yi−y^i∣
其中, τ \tau τ 是给定的分位数。决策变量是 y ^ i \hat{y}_i y^i,可以证明,使上面表达式最小化的 y ^ i \hat{y}_i y^i 就是给定分位数 τ \tau τ 对应的分位点(将上面式子转化为连续密度函数的积分,然后求一阶导数即可证明)。
上式也可以简写成:
min y ^ i ∑ [ τ ( y i − y ^ i ) + + ( 1 − τ ) ( y ^ i − y i ) + ] \min_{\hat{y}_i}\quad \sum \left[\tau(y_i-\hat{y}_i)^++(1-\tau)(\hat{y}_i-y_i)^+\right] y^imin∑[τ(yi−y^i)++(1−τ)(y^i−yi)+]
2. 分位数回归的求解原理
为了求出分位数的回归方程,假设 y ^ i = X i β \hat{y}_i=\bm{X_i \beta} y^i=Xiβ,那么求解的目标函数转化为:
arg min β ∈ R k ∑ [ τ ( y i − X i β ) + + ( 1 − τ ) ( X i β − y i ) + ] \argmin_{\bm{\beta}\in\mathbb{R}^k} \sum \left[\tau(y_i-\bm{X_i \beta})^++(1-\tau)(\bm{X_i \beta}-y_i)^+\right] β∈Rkargmin∑[τ(yi−Xiβ)++(1−τ)(Xiβ−yi)+]
决策变量为 k k k 维回归方程的参数向量 β \bm{\beta} β。在实际的求解中,将上式转化为一个线性规划问题,引入两个虚拟变量 u i + u_i^+ ui+, u i − u_i^- ui−:
arg min β ∈ R k ∑ [ τ u i + + ( 1 − τ ) u i − ] s . t . i = 1 , 2 , … , n y i = X i β + u i + − u i − u i + ≥ 0 , u i − ≥ 0 \begin{aligned} &\argmin_{\bm{\beta}\in\mathbb{R}^k}\quad && \sum \left[\tau u_i^++(1-\tau)u_i^-\right]\\ &s.t. && i=1,2,\dots, n\\ &&& y_i=\bm{X_i \beta}+u_i^+-u_i^-\\ &&& u_i^+\geq 0, u_i^-\geq 0 \end{aligned} β∈Rkargmins.t.∑[τui++(1−τ)ui−]i=1,2,…,nyi=Xiβ+ui+−ui−ui+≥0,ui−≥0
然后用单纯形法或内点法求解,就能得出分位数回归方程(python 与 R 软件求出的分位数回归方程可能略微不同,因为求解方法不一样, python 使用了迭代的加权最小二乘法求解)。
3 python 分位数回归
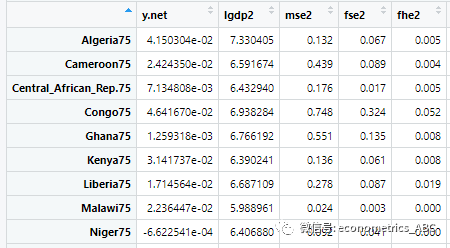
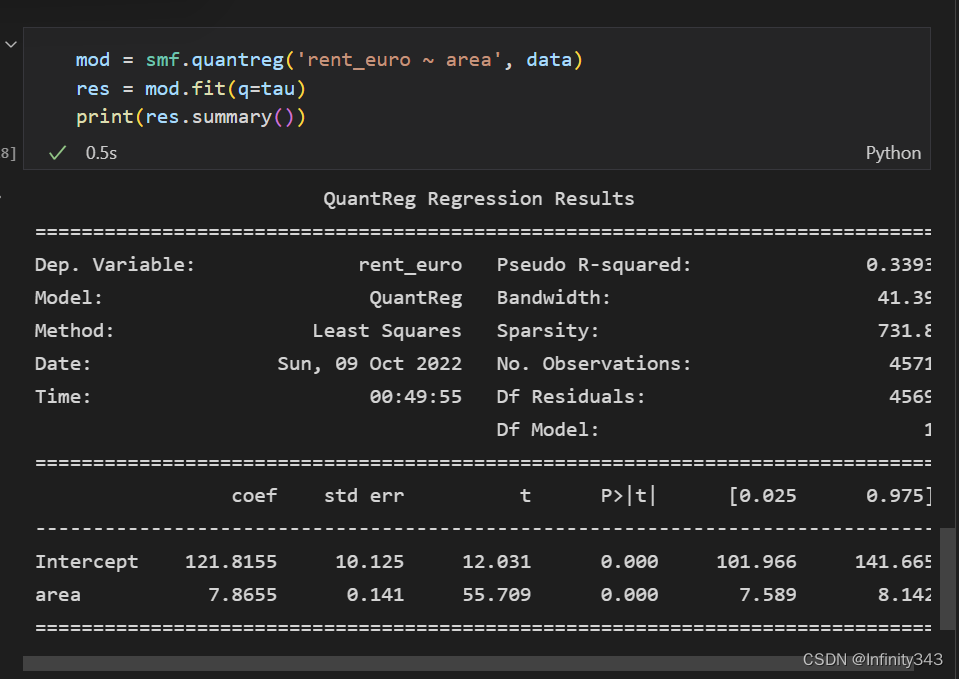
分位数回归要用到 statsmodels,下面的代码得到分位数为 0.6 的回归方程,并画图:
import statsmodels.formula.api as smf
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as pltdata = sm.datasets.engel.load_pandas().data
mod = smf.quantreg('foodexp ~ income', data)
res = mod.fit(q=0.6)
print(res.summary())plt.scatter(data['income'], data['foodexp'])
xx = np.arange(min(data['income']), max(data['income']))
yy = [i*res.params['income'] + res.params['Intercept'] for i in xx]
plt.plot(xx, yy, color='red')
plt.show()
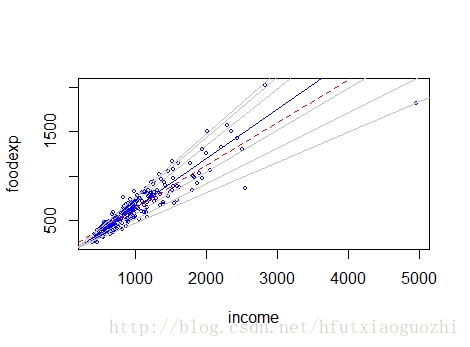
输出结果:
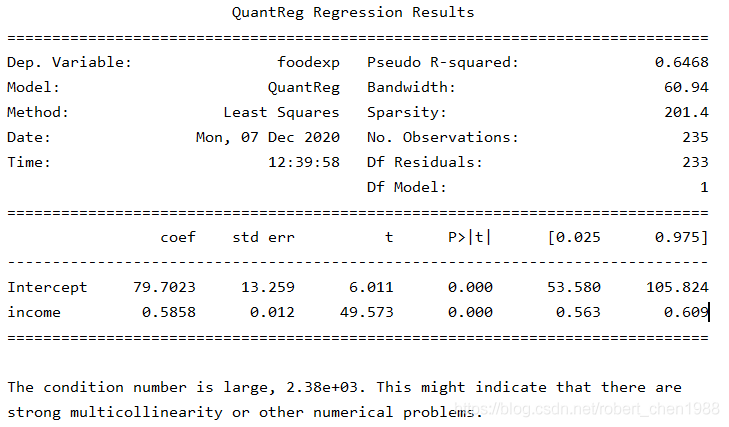
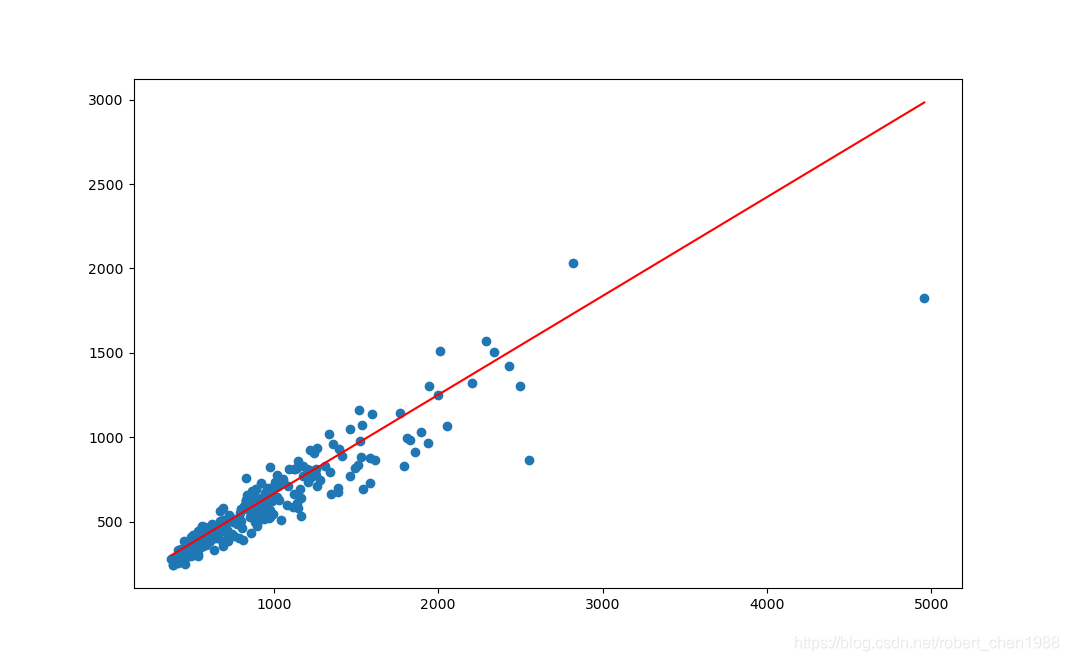
回归方程就是上面的红线,它将 40% 的数据分割在上面,60% 的数据分割在下面。
转载于个人公众号:Python 统计分析与数据科学