ResNet101–DSSD/SSD
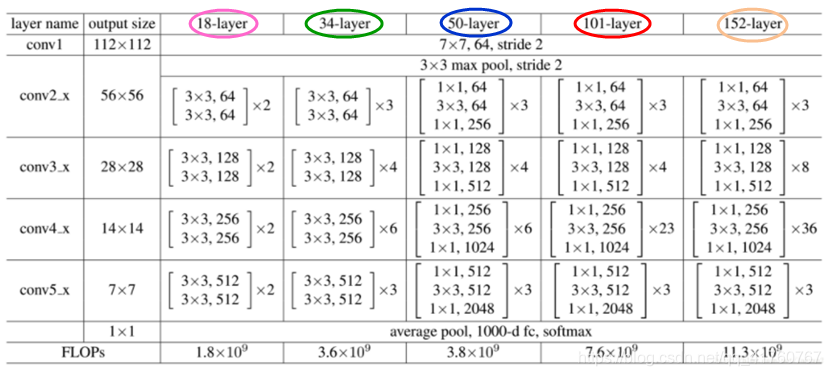
(1)ResNet在Pytorch官方代码中有5种不同深度的结构,分别为18、34、50、101、152(各网络深度指的是“需要通过训练更新参数“的层数,如卷积层,全连接层等),和论文完全一致。
(2)根据Block类型,可以将这五种ResNet分为两类:
1)基于BasicBlock,浅层网络18,34都是由BasicBlock 搭成;
2)基于Bottleneck,深层网络50,101,152是由Bottlen搭建而成;
Block相当于积木,每个layer都由Block搭建构成,再由layer组成整个网络。每中ResNet都是4个layer(不算一开始的7*7卷积层和maxpooling层)
(3)ResNet具体结构:


网络结构介绍
1、Block前面的层

所有图片只包含卷积层和Pooling层,BN层和ReLu层均为画出。
2、layer1层:(即对应conv2_x,图中所画方框)

和Basicblock不同的一点是,每一个Bottleneck都会在输入和输出之间加上一个卷积层,只不过在layer1中还没有downsample,这点和Basicblock是相同的。至于一定要加上卷积层的原因,就在于Bottleneck的conv3会将输入的通道数扩展成原来的4倍,导致输入一定和输出尺寸不同。
跳转链接的实现:out += identity—resnet.py 103行
out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)
3、layer2层:

尺寸为256×56×56 的输入进入layer2的第1个block后,首先要通过conv1将通道数降下来,之后conv2负责将尺寸降低(stride=2,图6从左向右数第2个红圈标注)。到输出处,由于尺寸发生变化,需要将输入downsample,同样是通过stride=2的1×1卷积层实现。
之后的3个block(layer2有4个block)就不需要进行downsample了(无论是residual还是输入),如图6从左向右数第3、4个红圈标注,stride均为1。因为这3个block结构均相同,所以图6中用“×3”表示
ResNet101的网络输出结构层:
ResNet101:((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): Bottleneck((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): Bottleneck((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(4): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(5): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(6): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(7): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(8): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(9): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(10): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(11): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(12): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(13): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(14): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(15): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(16): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(17): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(18): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(19): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(20): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(21): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(22): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(dilate_layer4): Sequential((0): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(1): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(extra_layer5): Sequential((0): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 1024, kernel_size=(2, 2), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(extra_layer6): Sequential((0): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 1024, kernel_size=(2, 2), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(extra_layer7): Sequential((0): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(extra_layer8): Sequential((0): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))
)Process finished with exit code 0Pytotch中ResNet网络结构的实现代码:
import torch
import torch.nn as nn
from dssd.utils.model_zoo import load_state_dict_from_url__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101','resnet152']model_urls = {'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth','resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth','resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth','resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth','resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}def convNxN(in_planes, out_planes, kernel_size=3, stride=1, padding=1, groups=1, dilation=1):"""3x3 convolution with padding"""if dilation > 1:padding = dilationreturn nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,padding=padding, groups=groups, bias=False, dilation=dilation)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None):super(BasicBlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dif groups != 1 or base_width != 64:raise ValueError('BasicBlock only supports groups=1 and base_width=64')if dilation > 1:raise NotImplementedError("Dilation > 1 not supported in BasicBlock")# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = convNxN(inplanes, planes, stride)self.bn1 = norm_layer(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = convNxN(planes, planes)self.bn2 = norm_layer(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None, kernel_size=3, padding=1):super(Bottleneck, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dwidth = int(planes * (base_width / 64.)) * groups# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = conv1x1(inplanes, width)self.bn1 = norm_layer(width)self.conv2 = convNxN(width, width, kernel_size, stride, padding, groups, dilation)self.bn2 = norm_layer(width)self.conv3 = conv1x1(width, planes * self.expansion)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return out# ResNet(Bottleneck, [3,4,23,3], **kwargs)
class ResNet(nn.Module):def __init__(self, block, layers, zero_init_residual=False,groups=1, width_per_group=64, replace_stride_with_dilation=[False, False, True],norm_layer=None):super(ResNet, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dself._norm_layer = norm_layerself.inplanes = 64self.dilation = 1if replace_stride_with_dilation is None:# each element in the tuple indicates if we should replace# the 2x2 stride with a dilated convolution instead元组中的每个元素都表示我们是否应该将2x2步幅替换为一个扩张的卷积replace_stride_with_dilation = [False, False, False]if len(replace_stride_with_dilation) != 3:raise ValueError("replace_stride_with_dilation should be None ""or a 3-element tuple, got {}".format(replace_stride_with_dilation))self.groups = groupsself.base_width = width_per_groupself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,bias=False)self.bn1 = norm_layer(self.inplanes)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2,dilate=replace_stride_with_dilation[0])self.layer3 = self._make_layer(block, 256, layers[2], stride=2,dilate=replace_stride_with_dilation[1])self.dilate_layer4 = self._make_layer(block, 256, layers[3], stride=2,dilate=replace_stride_with_dilation[2])# extra layers of added residual blocksself.extra_layer5 = self._make_extra_layer(block, 256, blocks=1, kernel_size=2, stride=2, padding=0,dilate=False)self.extra_layer6 = self._make_extra_layer(block, 256, blocks=1, kernel_size=2, stride=2, padding=0,dilate=False)self.extra_layer7 = self._make_extra_layer(block, 256, blocks=1, kernel_size=3, stride=1, padding=0,dilate=False)self.extra_layer8 = self._make_extra_layer(block, 256, blocks=1, kernel_size=3, stride=1, padding=0,dilate=False)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# Zero-initialize the last BN in each residual branch,# so that the residual branch starts with zeros, and each residual block behaves like an identity.# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677if zero_init_residual:for m in self.modules():if isinstance(m, Bottleneck):nn.init.constant_(m.bn3.weight, 0)elif isinstance(m, BasicBlock):nn.init.constant_(m.bn2.weight, 0)# self._make_layer(block, 64, layers[0])def _make_layer(self, block, planes, blocks, stride=1, dilate=False):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif dilate:self.dilation *= stridestride = 1else:self.dilation = 1if stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(conv1x1(self.inplanes, planes * block.expansion, stride),norm_layer(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, self.dilation, norm_layer))self.inplanes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer))return nn.Sequential(*layers)# self._make_extra_layer(block, 256, blocks=1, kernel_size=2, stride=2, padding=0, dilate=False)def _make_extra_layer(self, block, planes, blocks, kernel_size=3, stride=1, padding=1, dilate=False):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif dilate:self.dilation *= stridestride = 1else:self.dilation = 1downsample = nn.Sequential(convNxN(self.inplanes, planes * block.expansion, kernel_size, stride, padding),norm_layer(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, self.dilation, norm_layer, kernel_size=kernel_size, padding=padding))self.inplanes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer, kernel_size=kernel_size, padding=padding))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x5 = self.dilate_layer4(self.layer3(x))x6 = self.extra_layer5(x5)x7 = self.extra_layer6(x6)x8 = self.extra_layer7(x7)x9 = self.extra_layer8(x8)return x, x5, x6, x7, x8, x9def load_pretrained(model, state_dict):model.load_state_dict(state_dict, strict=False)# _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
def _resnet(arch, block, layers, pretrained, progress, **kwargs):'''arch='resnet101'block=Bottlenecklayers=[3,4,23,3]ResNet(Bottleneck, [3,4,23,3], **kwargs)'''model = ResNet(block, layers, **kwargs)if pretrained:state_dict = load_state_dict_from_url(model_urls[arch])load_pretrained(model, state_dict)return modeldef resnet18(pretrained=False, progress=True, **kwargs):r"""ResNet-18 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,**kwargs)def resnet34(pretrained=False, progress=True, **kwargs):r"""ResNet-34 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,**kwargs)def resnet50(pretrained=False, progress=True, **kwargs):r"""ResNet-50 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,**kwargs)def resnet101(pretrained=False, progress=True, **kwargs):r"""ResNet-101 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,**kwargs)def resnet152(pretrained=False, progress=True, **kwargs):r"""ResNet-152 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,**kwargs)def resnext50_32x4d(pretrained=False, progress=True, **kwargs):r"""ResNeXt-50 32x4d model from`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['groups'] = 32kwargs['width_per_group'] = 4return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],pretrained, progress, **kwargs)def resnext101_32x8d(pretrained=False, progress=True, **kwargs):r"""ResNeXt-101 32x8d model from`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['groups'] = 32kwargs['width_per_group'] = 8return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],pretrained, progress, **kwargs)def wide_resnet50_2(pretrained=False, progress=True, **kwargs):r"""Wide ResNet-50-2 model from`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_The model is the same as ResNet except for the bottleneck number of channelswhich is twice larger in every block. The number of channels in outer 1x1convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048channels, and in Wide ResNet-50-2 has 2048-1024-2048.Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['width_per_group'] = 64 * 2return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],pretrained, progress, **kwargs)def wide_resnet101_2(pretrained=False, progress=True, **kwargs):r"""Wide ResNet-101-2 model from`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_The model is the same as ResNet except for the bottleneck number of channelswhich is twice larger in every block. The number of channels in outer 1x1convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048channels, and in Wide ResNet-50-2 has 2048-1024-2048.Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['width_per_group'] = 64 * 2return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],pretrained, progress, **kwargs)if __name__ == '__main__':res101 = resnet101()x = torch.randn(5,3,320,320)import ipdb; ipdb.set_trace()y = res101(x)# print(res101)
参考来源:
https://zhuanlan.zhihu.com/p/79378841









![[NCTF2019]SQLi 1regexp注入](https://img-blog.csdnimg.cn/4c262ff483944f478d13a83053002daf.png)
![buuctf-[NCTF2019]Keyboard](https://img-blog.csdnimg.cn/0d2cd646c0514b2198e62508d8e3c204.jpg)

![[NCTF2019]Fake XML cookbook](https://img-blog.csdnimg.cn/98fc6bd960dd496585955723c35c48fb.png)
![[NCTF2019]True XML cookbook](https://img-blog.csdnimg.cn/20210804132458265.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzUyOTA3ODM4,size_16,color_FFFFFF,t_70)
![[NCTF2019]Sore](https://img-blog.csdnimg.cn/33348eac02774c0a82a5420314156de5.png)
![[NCTF 2018]Easy_Audit](https://img-blog.csdnimg.cn/2771ba9438c645f998e2ce26895cc89c.png)

![[NCTF 2018]签到题](https://img-blog.csdnimg.cn/img_convert/1d07b8d57d692fce62ab23139c24d11d.png)